FlashVSR is a streaming, one-step diffusion-based video super-resolution framework with block-sparse attention and a Tiny Conditional Decoder. It reaches ~17 FPS at 768×1408 on a single A100 GPU. A Locality-Constrained Attention design further improves generalization and perceptual quality on ultra-high-resolution videos.
Stable Video Infinity (SVI) is able to generate ANY-length videos with high temporal consistency, plausible scene transitions, and controllable streaming storylines in ANY domains.
OpenSVI: Everything is open-sourced: training & evaluation scripts, datasets, and more.
Infinite Length: No inherent limit on video duration; generate arbitrarily long stories (see the 10‑minute “Tom and Jerry” demo).
Versatile: Supports diverse in-the-wild generation tasks: multi-scene short films, single‑scene animations, skeleton-/audio-conditioned generation, cartoons, and more.
Efficient: Only LoRA adapters are tuned, requiring very little training data: anyone can make their own SVI easily.
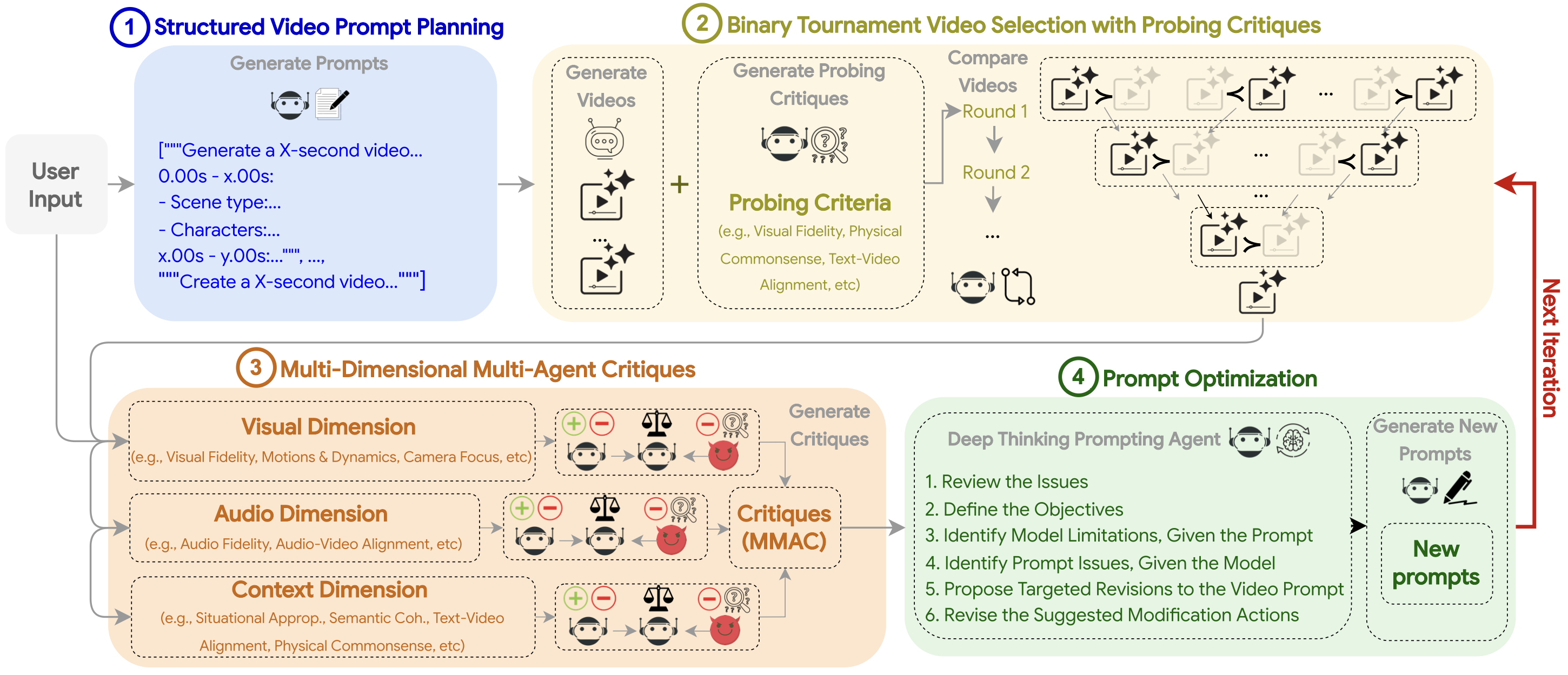
VISTA is a modular, configurable framework for optimizing text-to-video generation. Given a user video prompt P, it produces an optimized video V* and its refined prompt P* through two phases: (i) Initialization and (ii) Self-Improvement, inspired by the human video optimization process via prompting. During (i), the prompt is parsed and planned into variants to generate candidate videos (Step 1), after which the best video-prompt pair is selected (Step 2). In (ii), the system generates multi-dimensional, multi-agent critiques (Step 3), refines the prompt (Step 4), produces new videos, and reselects the champion pair (Step 2). This phase continues until a stopping criterion is met or the maximum number of iterations is reached.
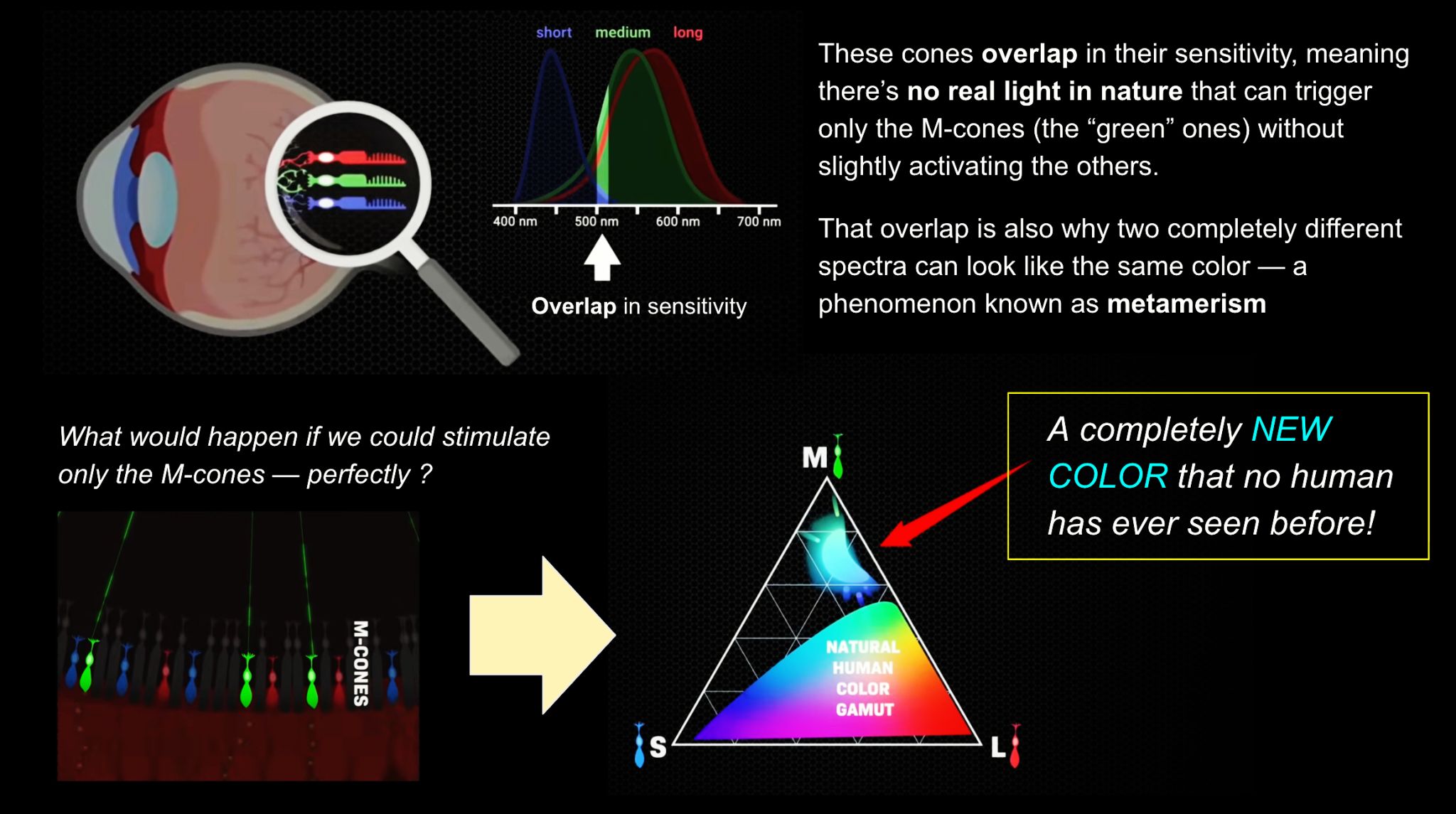
We introduce a principle, Oz, for displaying color imagery: directly controlling the human eye’s photoreceptor activity via cell-by-cell light delivery. Theoretically, novel colors are possible through bypassing the constraints set by the cone spectral sensitivities and activating M cone cells exclusively. In practice, we confirm a partial expansion of colorspace toward that theoretical ideal. Attempting to activate M cones exclusively is shown to elicit a color beyond the natural human gamut, formally measured with color matching by human subjects. They describe the color as blue-green of unprecedented saturation. Further experiments show that subjects perceive Oz colors in image and video form. The prototype targets laser microdoses to thousands of spectrally classified cones under fixational eye motion. These results are proof-of-principle for programmable control over individual photoreceptors at population scale.
SeC (Segment Concept) is a breakthrough in video object segmentation that shifts from simple feature matching to high-level conceptual understanding. Unlike SAM 2.1 which relies primarily on visual similarity, SeC uses a Large Vision-Language Model (LVLM) to understand what an object is conceptually, enabling robust tracking through:
Semantic Understanding: Recognizes objects by concept, not just appearance
Scene Complexity Adaptation: Automatically balances semantic reasoning vs feature matching
Superior Robustness: Handles occlusions, appearance changes, and complex scenes better than SAM 2.1
SOTA Performance: +11.8 points over SAM 2.1 on SeCVOS benchmark
How SeC Works
Visual Grounding: You provide initial prompts (points/bbox/mask) on one frame
Concept Extraction: SeC’s LVLM analyzes the object to build a semantic understanding
Smart Tracking: Dynamically uses both semantic reasoning and visual features
Keyframe Bank: Maintains diverse views of the object for robust concept understanding
The result? SeC tracks objects more reliably through challenging scenarios like rapid appearance changes, occlusions, and complex multi-object scenes.
Hand drawn sketch | Models made in CC4 with ZBrush | Textures in Substance Painter | Paint over in Photoshop | Renders, Animation, VFX with AI. Each 5-8 hours spread over a couple days.
As I continue to explore the use of AI tools to enhance my 3D character creation process, I discover they can be incredibly useful during the previsualization phase to see what a character might ultimately look like in production. I selectively use AI to enhance and accelerate my creative process, not to replace it or use it as an end to end solution.
The dynamic range is a ratio between the maximum and minimum values of a physical measurement. Its definition depends on what the dynamic range refers to.
For a scene: Dynamic range is the ratio between the brightest and darkest parts of the scene.
For a camera: Dynamic range is the ratio of saturation to noise. More specifically, the ratio of the intensity that just saturates the camera to the intensity that just lifts the camera response one standard deviation above camera noise.
For a display: Dynamic range is the ratio between the maximum and minimum intensities emitted from the screen.
The Dynamic Range of real-world scenes can be quite high — ratios of 100,000:1 are common in the natural world. An HDR (High Dynamic Range) image stores pixel values that span the whole tonal range of real-world scenes. Therefore, an HDR image is encoded in a format that allows the largest range of values, e.g. floating-point values stored with 32 bits per color channel. Another characteristics of an HDR image is that it stores linear values. This means that the value of a pixel from an HDR image is proportional to the amount of light measured by the camera.
For TVs HDR is great, but it’s not the only new TV feature worth discussing.