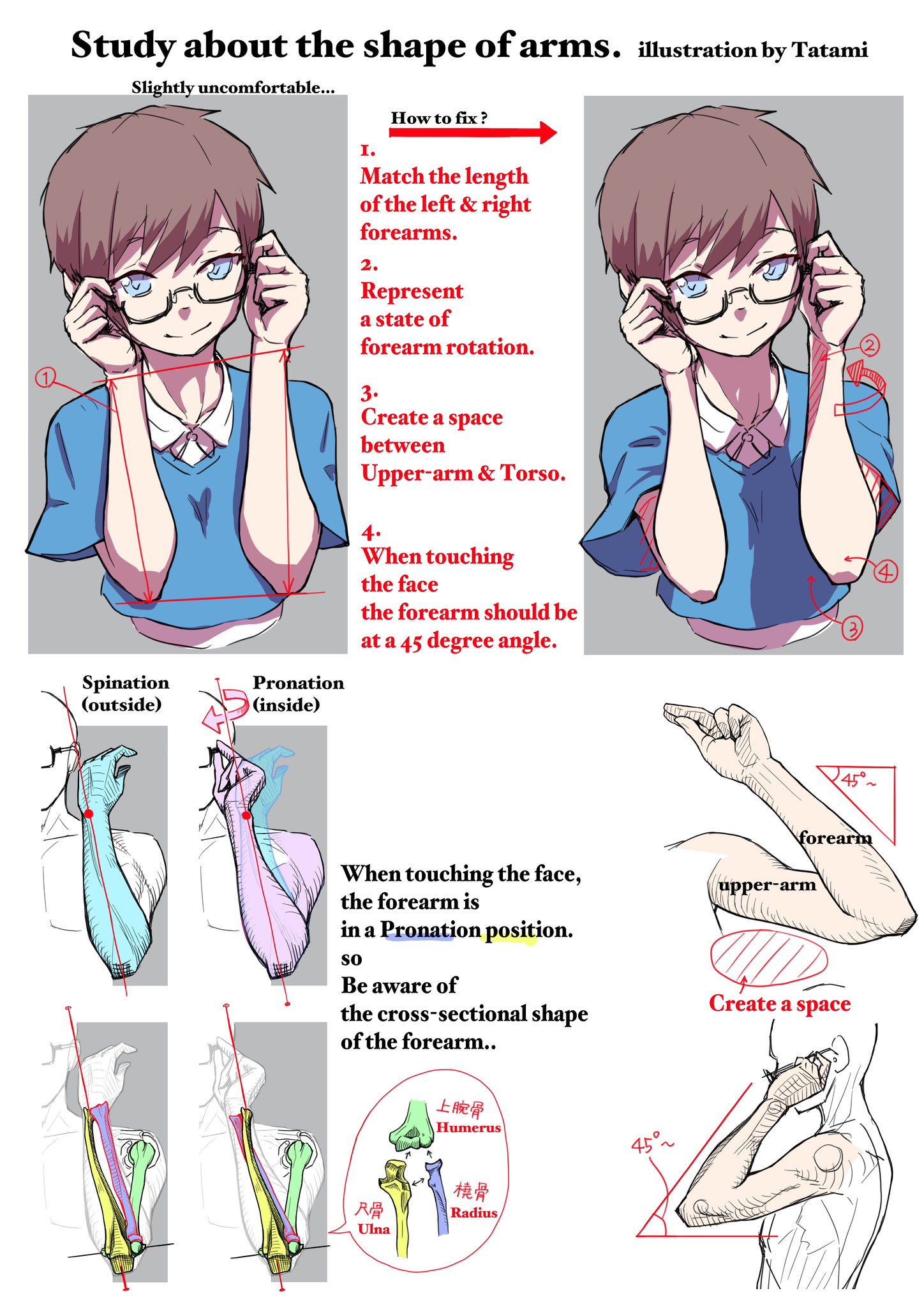
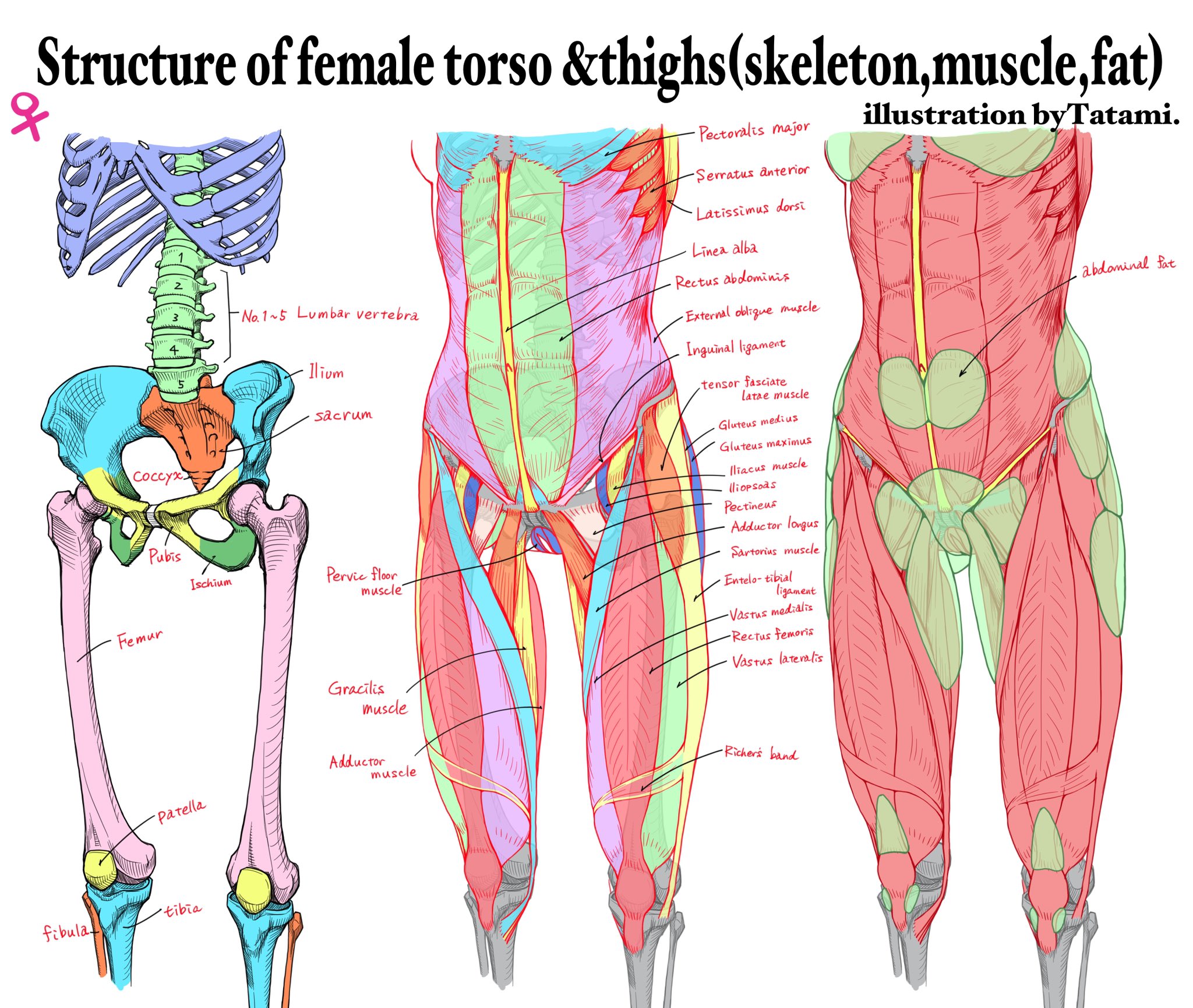
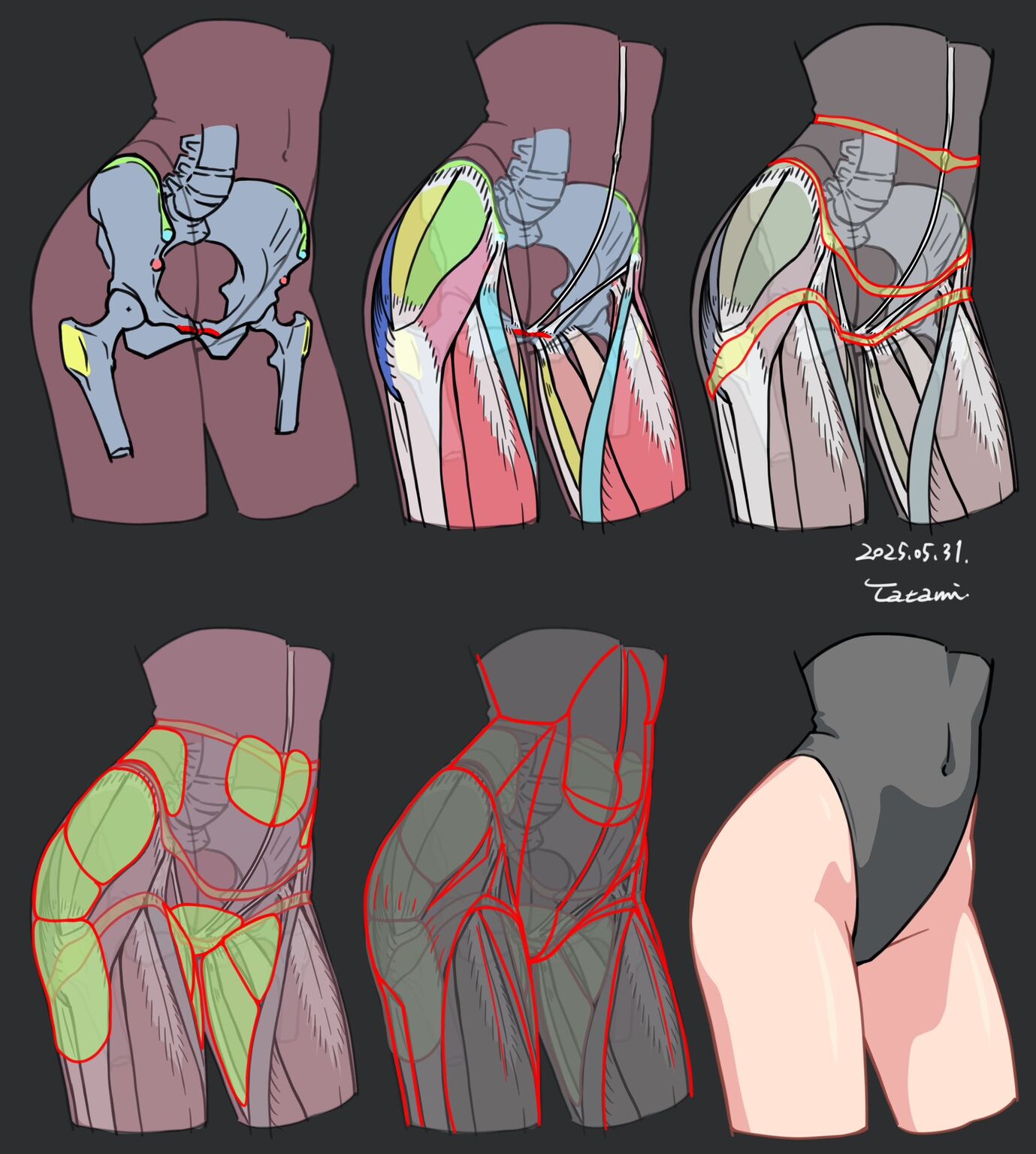
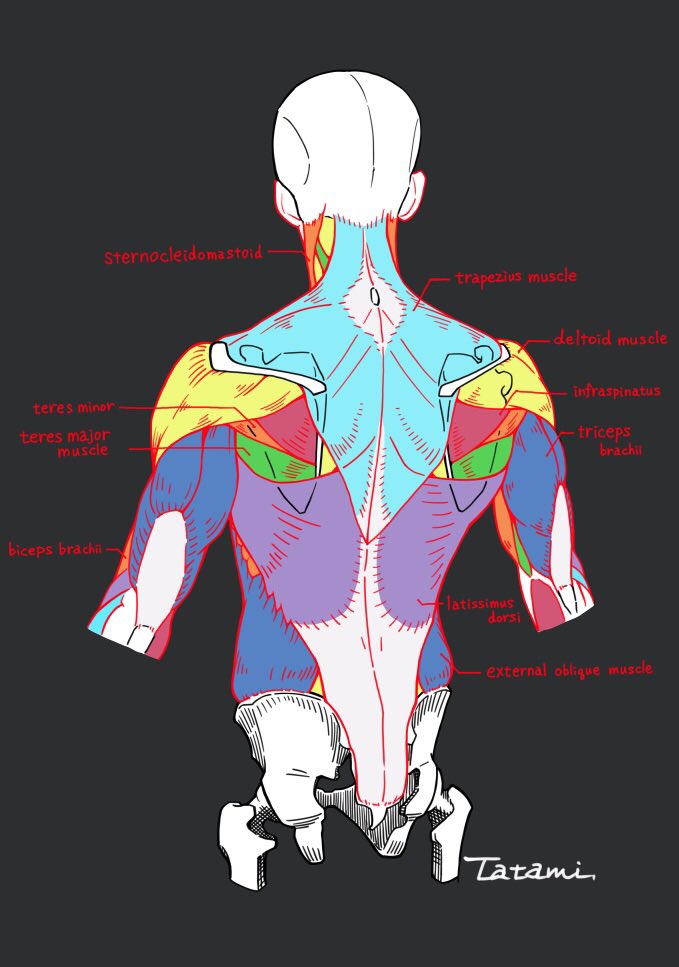
BREAKING NEWS
LATEST POSTS
-
TurboSquid move towards supporting AI against its own policies
https://www.turbosquid.com/ai-3d-generator
The AI is being trained using a mix of Shutterstock 2D imagery and 3D models drawn from the TurboSquid marketplace. However, it’s only being trained on models that artists have approved for this use.
People cannot generate a model and then immediately sell it. However, a generated 3D model can be used as a starting point for further customization, which could then be sold on the TurboSquid marketplace. However, models created using our generative 3D tool—and their derivatives—can only be sold on the TurboSquid marketplace.
TurboSquid does not accept AI-generated content from our artists
As AI-powered tools become more accessible, it is important for us to address the impact AI has on our artist community as it relates to content made licensable on TurboSquid. TurboSquid, in line with its parent company Shutterstock, is taking an ethically responsible approach to AI on its platforms. We want to ensure that artists are properly compensated for their contributions to AI projects while supporting customers with the protections and coverage issued through the TurboSquid license.In order to ensure that customers are protected, that intellectual property is not misused, and that artists’ are compensated for their work, TurboSquid will not accept content uploaded and sold on our marketplace that is generated by AI. Per our Publisher Agreement, artists must have proven IP ownership of all content that is submitted. AI-generated content is produced using machine learning models that are trained using many other creative assets. As a result, we cannot accept content generated by AI because its authorship cannot be attributed to an individual person, and we would be unable to ensure that all artists who were involved in the generation of that content are compensated.
-
How to View Apple’s Spatial Videos
https://blog.frame.io/2024/02/01/how-to-capture-and-view-vision-pro-spatial-video/
Apple’s Immersive Videos format is a special container for 3D or “spatial” video. You can capture spatial video to this format either by using the Vision Pro as a head-mounted camera, or with an iPhone 15 Pro or 15 Pro Max. The headset offers better capture because its cameras are more optimized for 3D, resulting in higher resolution and improved depth effects.
While the iPhone wasn’t designed specifically as a 3D camera, it can use its primary and ultrawide cameras in landscape orientation simultaneously, allowing it to capture spatial video—as long as you hold it horizontally. Computational photography is used to compensate for the lens differences, and the output is two separate 1080p, 30fps videos that capture a 180-degree field of view.
These spatial videos are stored using the MV-HEVC (Multi-View High-Efficiency Video Coding) format, which uses H.265 compression to crunch this down to approximately 130MB per minute, including spatial audio. Unlike conventional stereoscopic formats—which combine the two views into a flattened video file that’s either side-by-side or top/bottom—these spatial videos are stored as discrete tracks within the file container.
Spatialify is an iOS app designed to view and convert various 3D formats. It also works well on Mac OS, as long as your Mac has an Apple Silicon CPU. And it supports MV-HEVC, so you’ll be all set. It’s just $4.99, a genuine bargain considering what it does. Find Spatialify here.












FEATURED POSTS

-
AI and the Law – Copyright Traps for Large Language Models – This new tool can tell you whether AI has stolen your work
https://github.com/computationalprivacy/copyright-traps
Copyright traps (see Meeus et al. (ICML 2024)) are unique, synthetically generated sequences who have been included into the training dataset of CroissantLLM. This dataset allows for the evaluation of Membership Inference Attacks (MIAs) using CroissantLLM as target model, where the goal is to infer whether a certain trap sequence was either included in or excluded from the training data.
This dataset contains non-member (
label=0) and member (label=1) trap sequences, which have been generated using this code and by sampling text from LLaMA-2 7B while controlling for sequence length and perplexity. The dataset contains splits according toseq_len_{XX}_n_rep_{YY}where sequences ofXX={25,50,100}tokens are considered andYY={10, 100, 1000}number of repetitions for member sequences. Each dataset also contains the ‘perplexity bucket’ for each trap sequence, where the original paper showed that higher perplexity sequences tend to be more vulnerable.Note that for a fixed sequence length, and across various number of repetitions, each split contains the same set of non-member sequences (
n_rep=0). Also additional non-members generated in exactly the same way are provided here, which might be required for some MIA methodologies making additional assumptions for the attacker.