


-
Transformer Explainer -Interactive Learning of Text-Generative Models
https://github.com/poloclub/transformer-explainer
Transformer Explainer is an interactive visualization tool designed to help anyone learn how Transformer-based models like GPT work. It runs a live GPT-2 model right in your browser, allowing you to experiment with your own text and observe in real time how internal components and operations of the Transformer work together to predict the next tokens. Try Transformer Explainer at http://poloclub.github.io/transformer-explainer
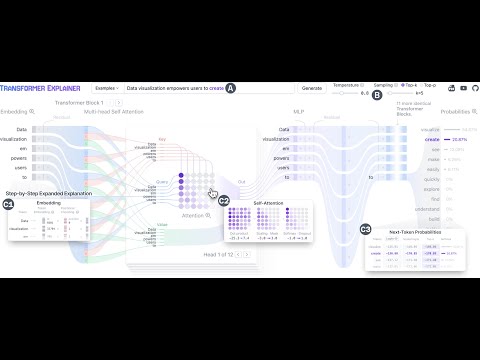
-
Henry Daubrez – How to generate VR/ 360 videos directly with Google VEO
https://www.linkedin.com/posts/upskydown_vr-googleveo-veo3-activity-7334269406396461059-d8Da
If you prompt for a 360° video in VEO (like literally write “360°” ) it can generate a Monoscopic 360 video, then the next step is to inject the right metadata in your file so you can play it as an actual 360 video.
Once it’s saved with the right Metadata, it will be recognized as an actual 360/VR video, meaning you can just play it in VLC and drag your mouse to look around. -
Black Forest Labs released FLUX.1 Kontext
https://replicate.com/blog/flux-kontext
https://replicate.com/black-forest-labs/flux-kontext-pro
There are three models, two are available now, and a third open-weight version is coming soon:
- FLUX.1 Kontext [pro]: State-of-the-art performance for image editing. High-quality outputs, great prompt following, and consistent results.
- FLUX.1 Kontext [max]: A premium model that brings maximum performance, improved prompt adherence, and high-quality typography generation without compromise on speed.
- Coming soon: FLUX.1 Kontext [dev]: An open-weight, guidance-distilled version of Kontext.
We’re so excited with what Kontext can do, we’ve created a collection of models on Replicate to give you ideas:
- Multi-image kontext: Combine two images into one.
- Portrait series: Generate a series of portraits from a single image
- Change haircut: Change a person’s hair style and color
- Iconic locations: Put yourself in front of famous landmarks
- Professional headshot: Generate a professional headshot from any image

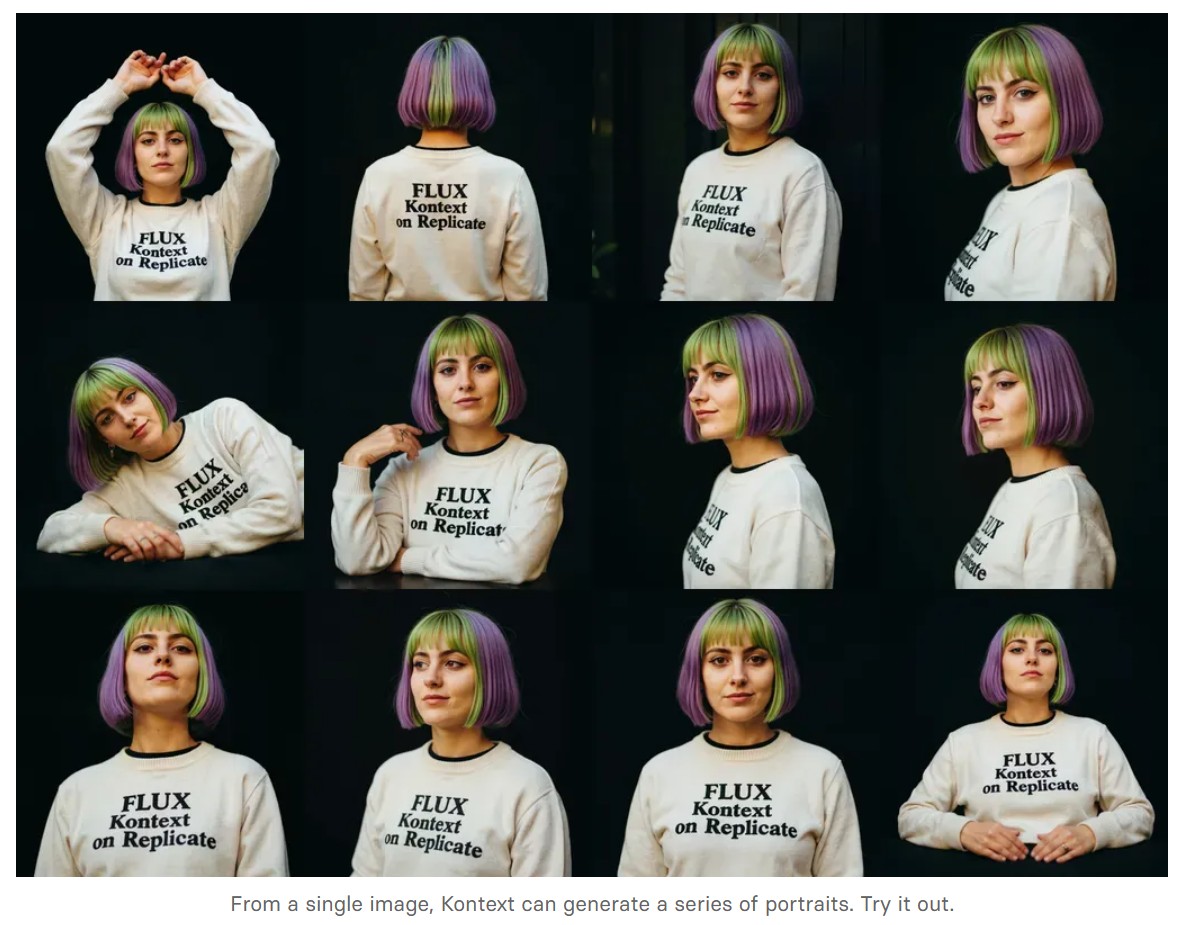
-
AI Models – A walkthrough by Andreas Horn
the 8 most important model types and what they’re actually built to do: ⬇️
1. 𝗟𝗟𝗠 – 𝗟𝗮𝗿𝗴𝗲 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹
→ Your ChatGPT-style model.
Handles text, predicts the next token, and powers 90% of GenAI hype.
🛠 Use case: content, code, convos.
2. 𝗟𝗖𝗠 – 𝗟𝗮𝘁𝗲𝗻𝘁 𝗖𝗼𝗻𝘀𝗶𝘀𝘁𝗲𝗻𝗰𝘆 𝗠𝗼𝗱𝗲𝗹
→ Lightweight, diffusion-style models.
Fast, quantized, and efficient — perfect for real-time or edge deployment.
🛠 Use case: image generation, optimized inference.
3. 𝗟𝗔𝗠 – 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗔𝗰𝘁𝗶𝗼𝗻 𝗠𝗼𝗱𝗲𝗹
→ Where LLM meets planning.
Adds memory, task breakdown, and intent recognition.
🛠 Use case: AI agents, tool use, step-by-step execution.
4. 𝗠𝗼𝗘 – 𝗠𝗶𝘅𝘁𝘂𝗿𝗲 𝗼𝗳 𝗘𝘅𝗽𝗲𝗿𝘁𝘀
→ One model, many minds.
Routes input to the right “expert” model slice — dynamic, scalable, efficient.
🛠 Use case: high-performance model serving at low compute cost.
5. 𝗩𝗟𝗠 – 𝗩𝗶𝘀𝗶𝗼𝗻 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹
→ Multimodal beast.
Combines image + text understanding via shared embeddings.
🛠 Use case: Gemini, GPT-4o, search, robotics, assistive tech.
6. 𝗦𝗟𝗠 – 𝗦𝗺𝗮𝗹𝗹 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹
→ Tiny but mighty.
Designed for edge use, fast inference, low latency, efficient memory.
🛠 Use case: on-device AI, chatbots, privacy-first GenAI.
7. 𝗠𝗟𝗠 – 𝗠𝗮𝘀𝗸𝗲𝗱 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹
→ The OG foundation model.
Predicts masked tokens using bidirectional context.
🛠 Use case: search, classification, embeddings, pretraining.
8. 𝗦𝗔𝗠 – 𝗦𝗲𝗴𝗺𝗲𝗻𝘁 𝗔𝗻𝘆𝘁𝗵𝗶𝗻𝗴 𝗠𝗼𝗱𝗲𝗹
→ Vision model for pixel-level understanding.
Highlights, segments, and understands *everything* in an image.
🛠 Use case: medical imaging, AR, robotics, visual agents.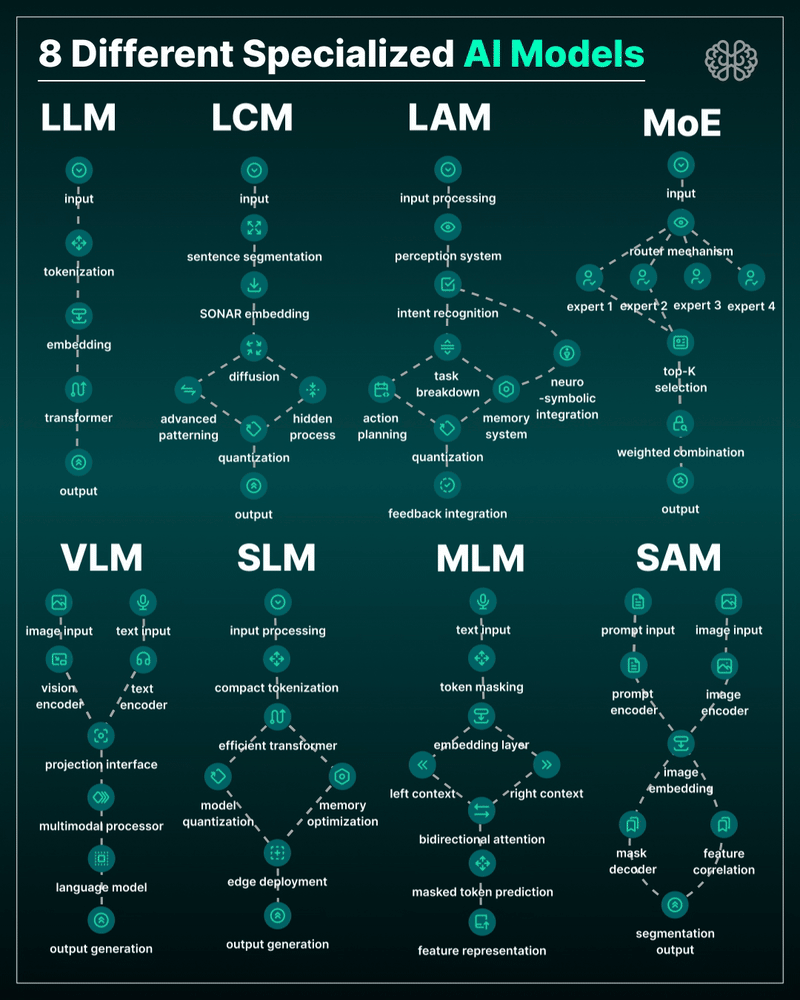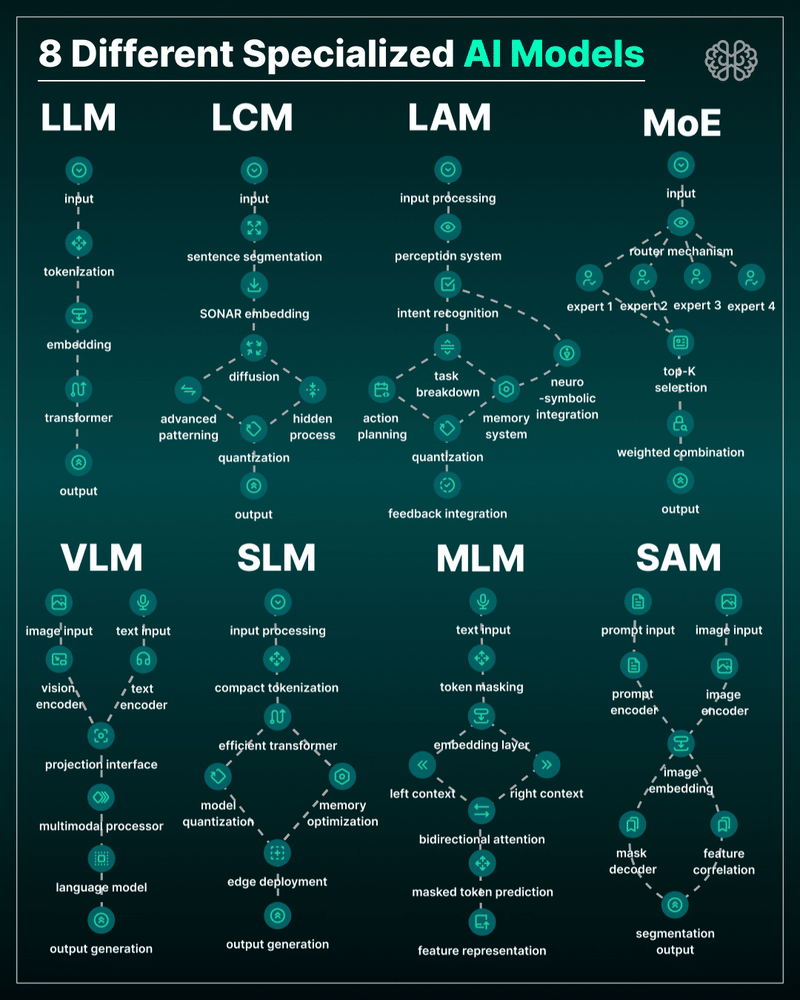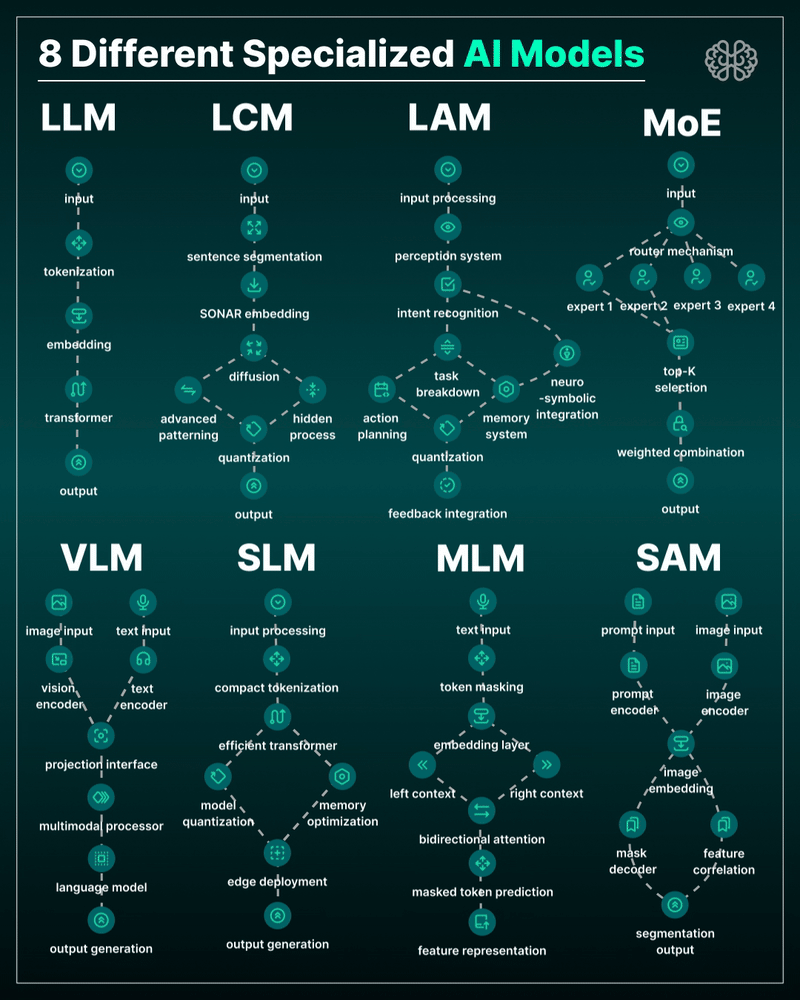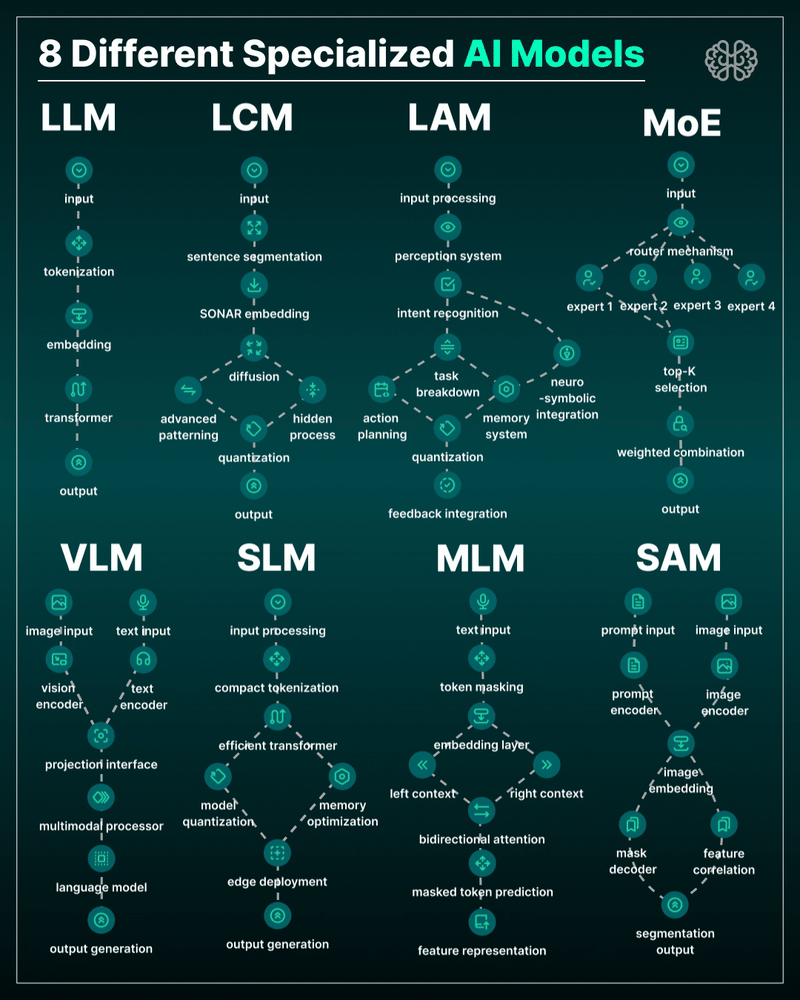
-
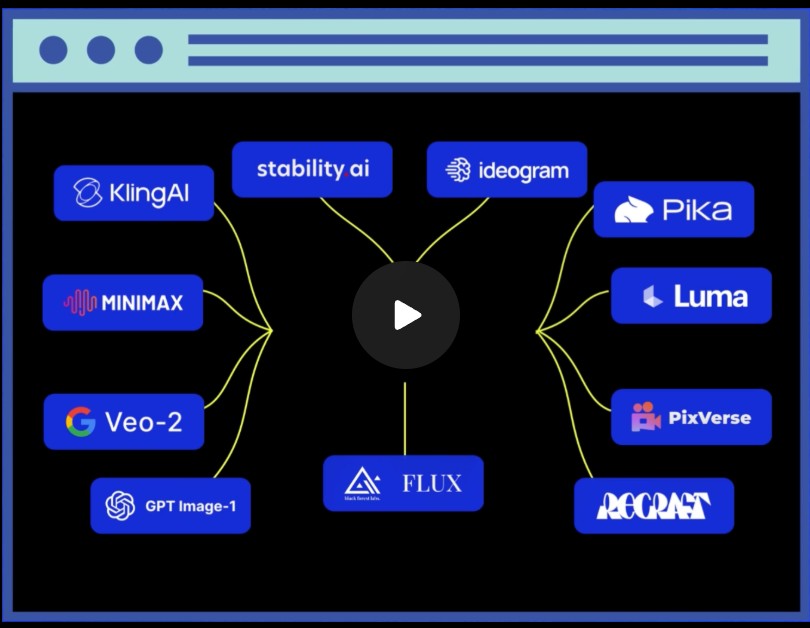
Introducting ComfyUI Native API Nodes
https://blog.comfy.org/p/comfyui-native-api-nodes
Models Supported
- Black Forest Labs Flux 1.1[pro] Ultra, Flux .1[pro]
- Kling 2.0, 1.6, 1.5 & Various Effects
- Luma Photon, Ray2, Ray1.6
- MiniMax Text-to-Video, Image-to-Video
- PixVerse V4 & Effects
- Recraft V3, V2 & Various Tools
- Stability AI Stable Image Ultra, Stable Diffusion 3.5 Large
- Google Veo2
- Ideogram V3, V2, V1
- OpenAI GPT4o image
- Pika 2.2
-
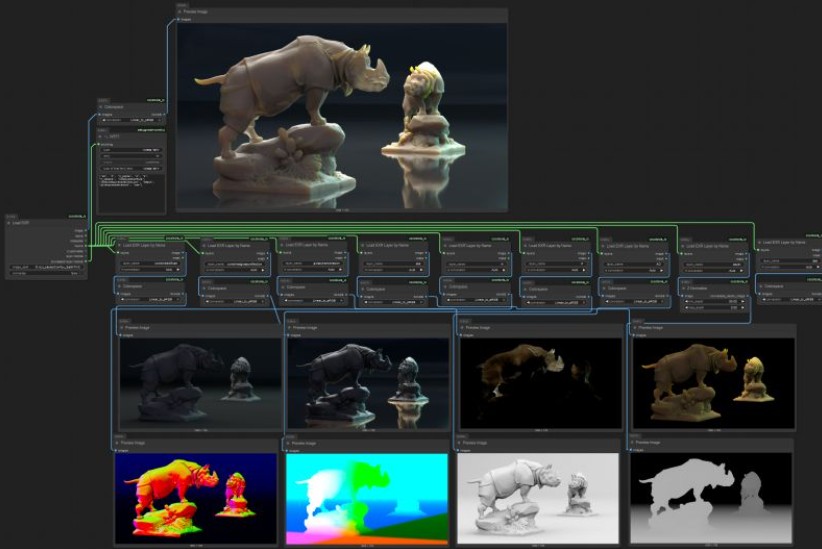
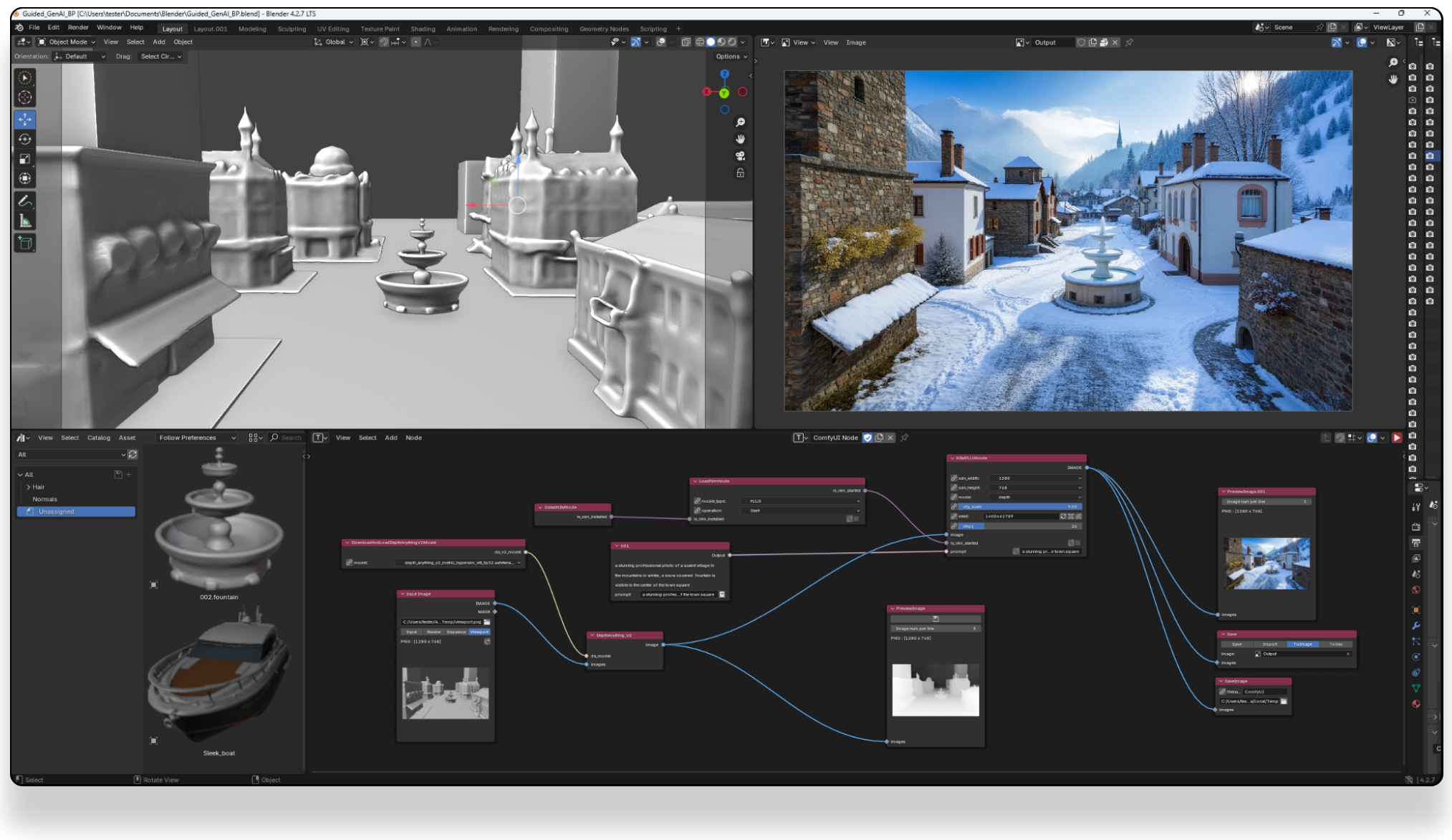
ComfyUI-CoCoTools_IO – A set of nodes focused on advanced image I/O operations, particularly for EXR file handling
https://github.com/Conor-Collins/ComfyUI-CoCoTools_IO
Features
- Advanced EXR image input with multilayer support
- EXR layer extraction and manipulation
- High-quality image saving with format-specific options
- Standard image format loading with bit depth awareness
Current Nodes
Image I/O
- Image Loader: Load standard image formats (PNG, JPG, WebP, etc.) with proper bit depth handling
- Load EXR: Comprehensive EXR file loading with support for multiple layers, channels, and cryptomatte data
- Load EXR Layer by Name: Extract specific layers from EXR files (similar to Nuke’s Shuffle node)
- Cryptomatte Layer: Specialized handling for cryptomatte layers in EXR files
- Image Saver: Save images in various formats with format-specific options (bit depth, compression, etc.)
Image Processing
- Colorspace: Convert between sRGB and Linear colorspaces
- Z Normalize: Normalize depth maps and other single-channel data











COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Most common ways to smooth 3D prints
-
The Perils of Technical Debt – Understanding Its Impact on Security, Usability, and Stability
-
Methods for creating motion blur in Stop motion
-
UV maps
-
Black Body color aka the Planckian Locus curve for white point eye perception
-
Types of AI Explained in a few Minutes – AI Glossary
-
copypastecharacter.com – alphabets, special characters, alt codes and symbols library
-
What the Boeing 737 MAX’s crashes can teach us about production business – the effects of commoditisation
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
