


-
VFX Giant MPC and Parent Company Technicolor Shut Down Amid ‘Severe Financial Challenges
https://variety.com/2025/film/global/technicolor-vfx-mpc-shutter-severe-challenges-1236316354
Shaun Severi, Head of Creative Production at the Mill, claimed in a LinkedIn post that 4,500 had lost their jobs in 24 hours: “The problem wasn’t talent or execution — it was mismanagement at the highest levels…the incompetence at the top was nothing short of disastrous.”
According to Severi, successive company presidents “buried the company under massive debt by acquiring VFX Studios…the second president, after a disastrous merger of the post houses, took us public, artificially inflating the company’s value — only for it to come crashing down when the real numbers were revealed….and the third and final president, who came from a car rental company, had no vision of what she was building, selling or managing.”

-
Moondream Gaze Detection – Open source code
This is convenient for captioning videos, understanding social dynamics, and for specific cases such as sports analytics, or detecting when drivers or operators are distracted.
https://huggingface.co/spaces/moondream/gaze-demo
https://moondream.ai/blog/announcing-gaze-detection

-
X-Dyna – Expressive Dynamic Human Image Animation
https://x-dyna.github.io/xdyna.github.io
A novel zero-shot, diffusion-based pipeline for animating a single human image using facial expressions and body movements derived from a driving video, that generates realistic, context-aware dynamics for both the subject and the surrounding environment.

-
Flex 1 Alpha – a pre-trained base 8 billion parameter rectified flow transformer
https://huggingface.co/ostris/Flex.1-alpha
Flex.1 started as the FLUX.1-schnell-training-adapter to make training LoRAs on FLUX.1-schnell possible.

-
Generative Detail Enhancement for Physically Based Materials
https://arxiv.org/html/2502.13994v1
https://arxiv.org/pdf/2502.13994
A tool for enhancing the detail of physically based materials using an off-the-shelf diffusion model and inverse rendering.

-
Camera Metadata Toolkit (camdkit) for Virtual Production
https://github.com/SMPTE/ris-osvp-metadata-camdkit
Today
camdkitsupports mapping (or importing, if you will) of metadata from five popular digital cinema cameras into a canonical form; it also supports a mapping of the metadata defined in the F4 protocol used by tracking system components from Mo-Sys.
-
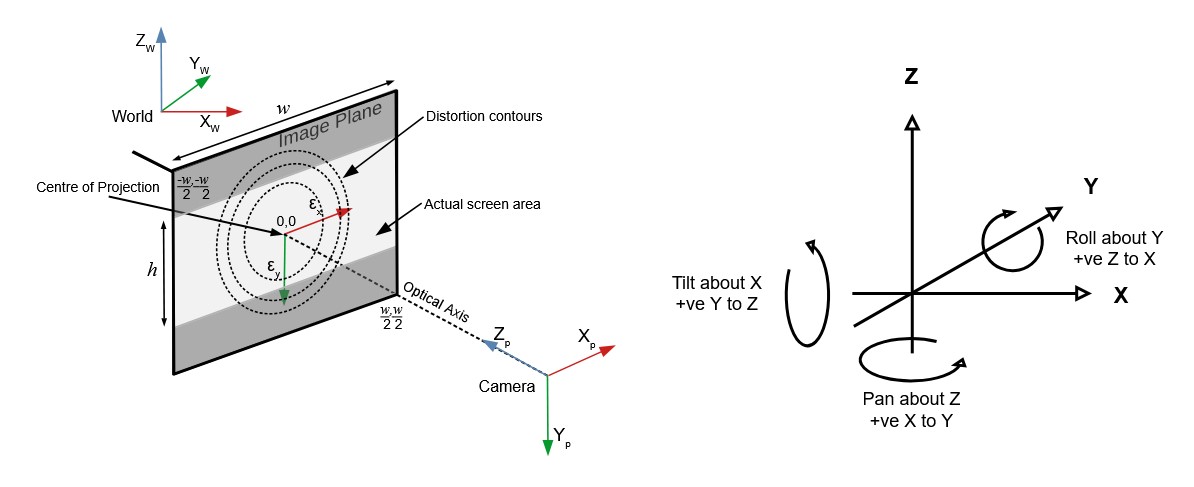
OpenTrackIO – free and open-source protocol designed to improve interoperability in Virtual Production
OpenTrackIO defines the schema of JSON samples that contain a wide range of metadata about the device, its transform(s), associated camera and lens. The full schema is given below and can be downloaded here.
-
Martin Gent – Comparing current video AI models
https://www.linkedin.com/posts/martingent_imagineapp-veo2-kling-activity-7298979787962806272-n0Sn
🔹 𝗩𝗲𝗼 2 – After the legendary prompt adherence of Veo 2 T2V, I have to say I2V is a little disappointing, especially when it comes to camera moves. You often get those Sora-like jump-cuts too which can be annoying.
🔹 𝗞𝗹𝗶𝗻𝗴 1.6 Pro – Still the one to beat for I2V, both for image quality and prompt adherence. It’s also a lot cheaper than Veo 2. Generations can be slow, but are usually worth the wait.
🔹 𝗥𝘂𝗻𝘄𝗮𝘆 Gen 3 – Useful for certain shots, but overdue an update. The worst performer here by some margin. Bring on Gen 4!
🔹 𝗟𝘂𝗺𝗮 Ray 2 – I love the energy and inventiveness Ray 2 brings, but those came with some image quality issues. I want to test more with this model though for sure.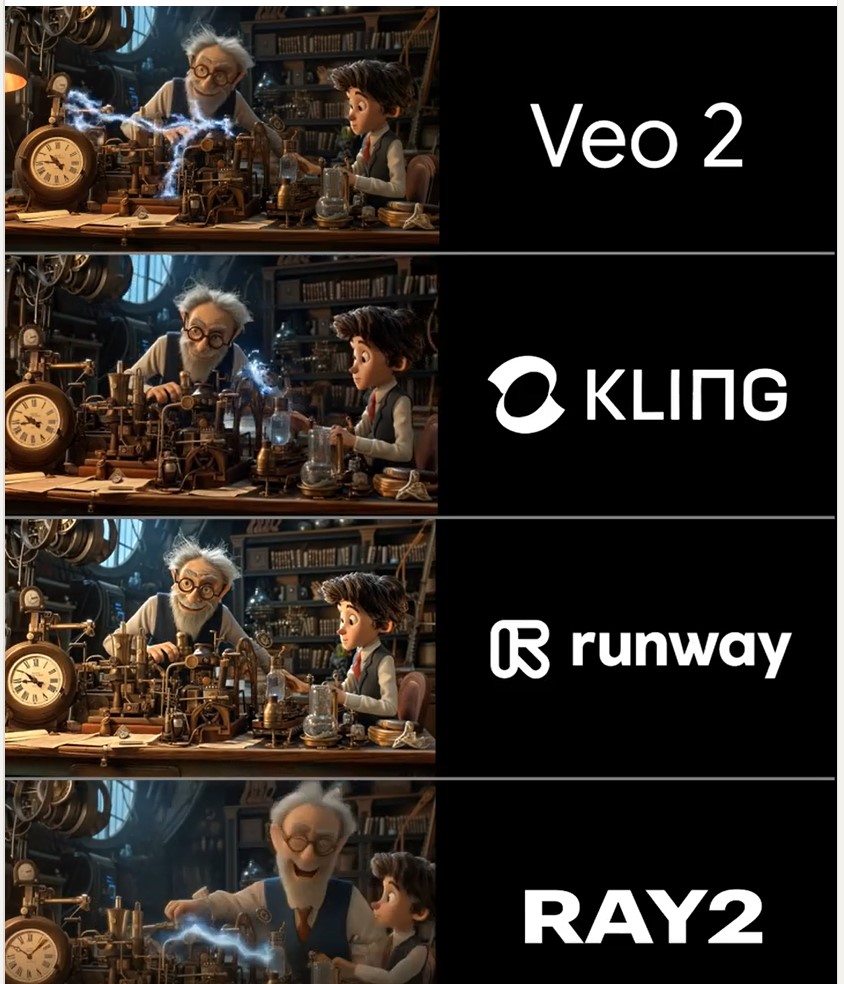
-
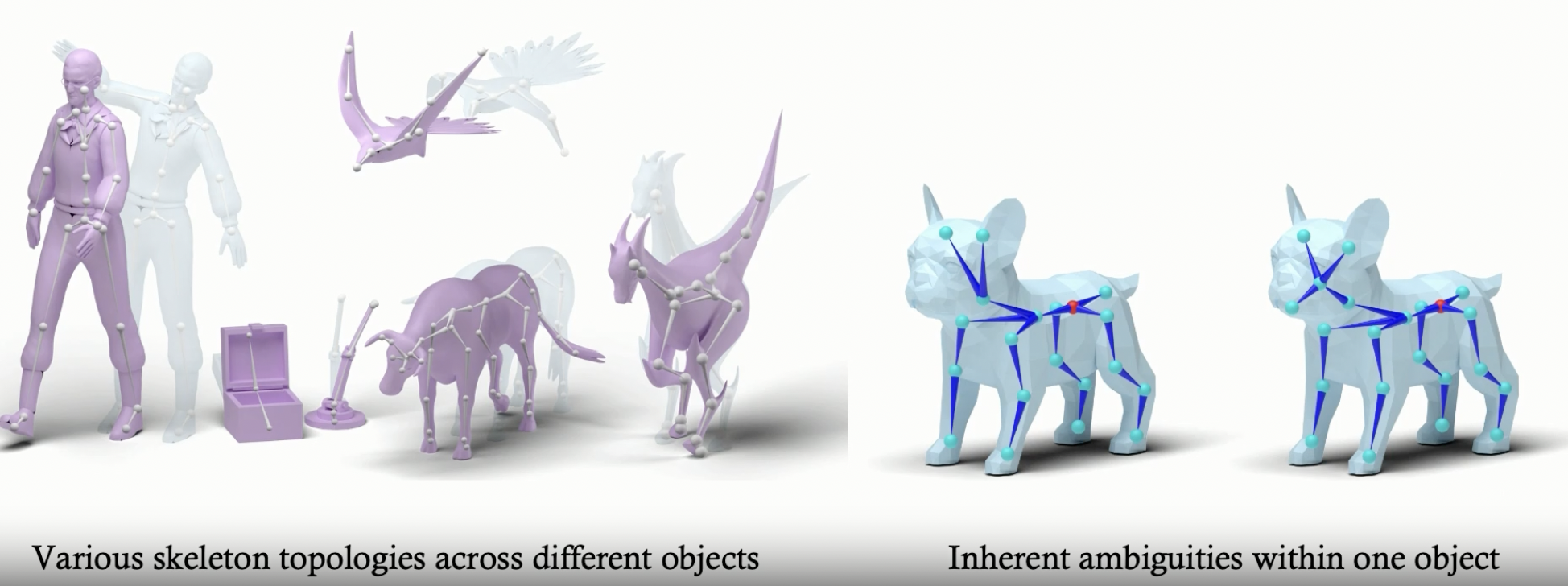
RigAnything – Template-Free Autoregressive Rigging for Diverse 3D Assets
https://www.liuisabella.com/RigAnything
RigAnything was developed through a collaboration between UC San Diego, Adobe Research, and Hillbot Inc. It addresses one of 3D animation’s most persistent challenges: automatic rigging.
- Template-Free Autoregressive Rigging. A transformer-based model that sequentially generates skeletons without predefined templates, enabling automatic rigging across diverse 3D assets through probabilistic joint prediction and skinning weight assignment.
- Support Arbitrary Input Pose. Generates high-quality skeletons for shapes in any pose through online joint pose augmentation during training, eliminating the common rest-pose requirement of existing methods and enabling broader real-world applications.
- Fast Rigging Speed. Achieves 20x faster performance than existing template-based methods, completing rigging in under 2 seconds per shape.
-
Skywork SkyReels – All-in-one open source AI video creation based on Hynyuan
https://github.com/SkyworkAI/SkyReels-V1
All-in-one AI platform for video creation, including voiceover, lipsync, SFX, and editing. One click turn text to video & image to video. Turns idea into stunning video in minutes. Check Pricing Details. Start For Free. All-In-One Platform.
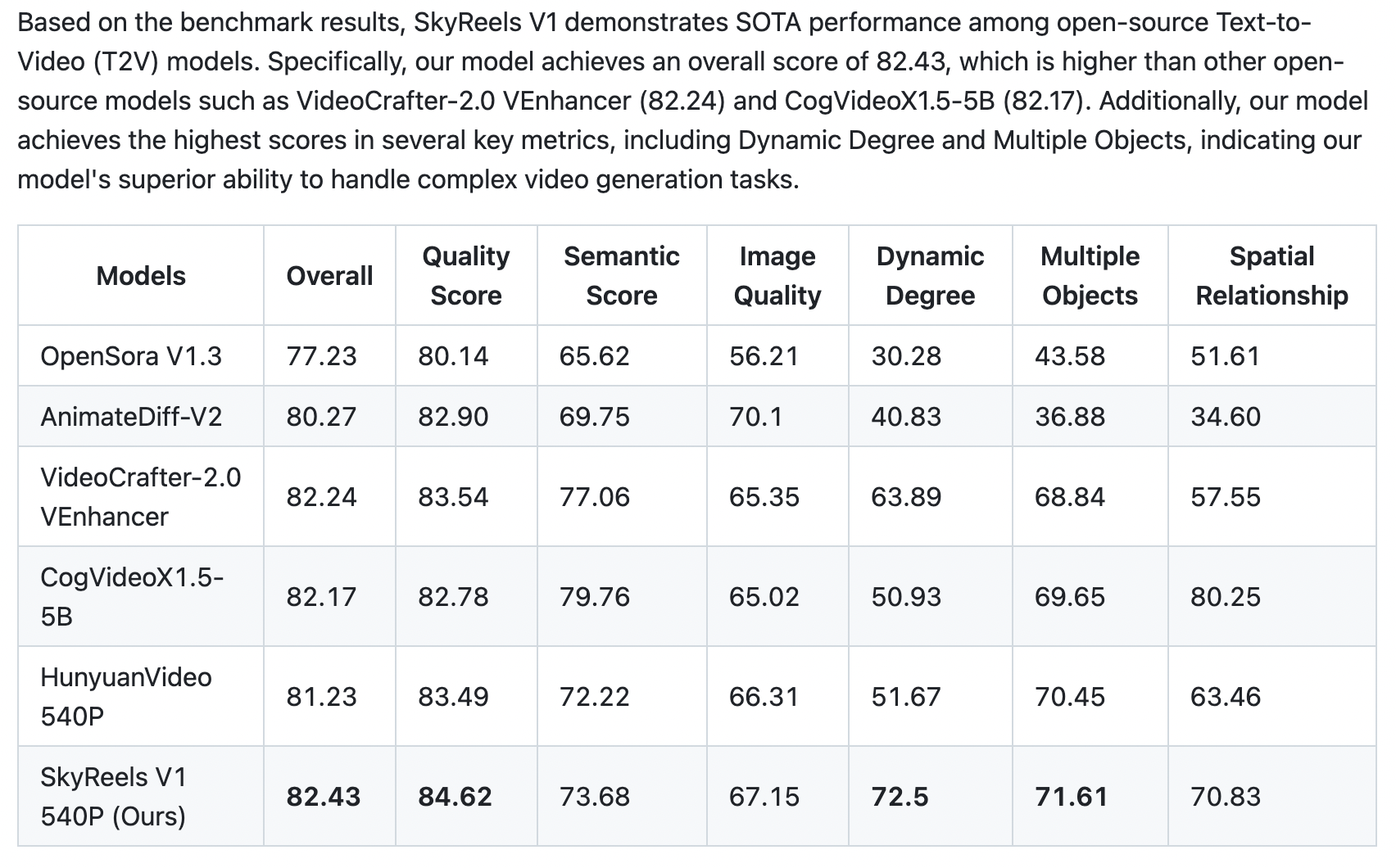
SkyReels-V1 is purpose-built for AI short video production based on Hynyuan. It achieves cinematic-grade micro-expression performances with 33 nuanced facial expressions and 400+ natural body movements that can be freely combined. The model integrates film-quality lighting aesthetics, generating visually stunning compositions and textures through text-to-video or image-to-video conversion – outperforming all existing open-source models across key metrics.






COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
