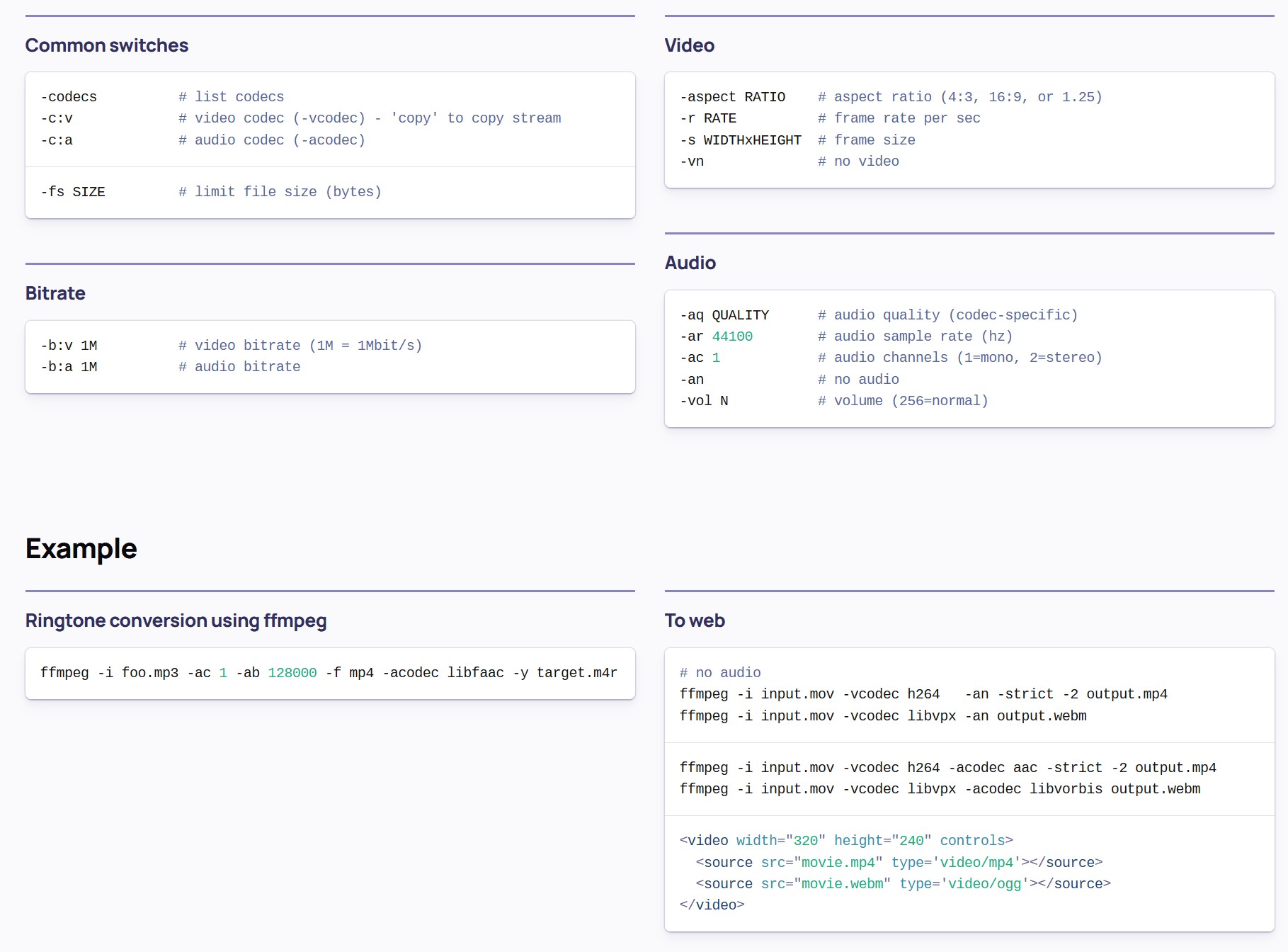
# extract one frame at the end of a video ffmpeg -sseof -0.1 -i intro_1.mp4 -frames:v 1 -q:v 1 intro_end.jpg
-sseof -0.1: This option tells FFmpeg to seek to 0.1 seconds before the end of the file. This approach is often more reliable for extracting the last frame, especially if the video’s duration isn’t an exact multiple of the frame interval. Super User -frames:v 1: Extracts a single frame. -q:v 1: Sets the quality of the output image; 1 is the highest quality.
# extract one frame at the beginning of a video ffmpeg -i speaking_4.mp4 -frames:v 1 speaking_beginning.jpg
# check video length ffmpeg -i C:\myvideo.mp4 -f null –
# Convert mov/mp4 to animated gifEdit ffmpeg -i input.mp4 -pix_fmt rgb24 output.gif Other useful ffmpeg commandsEdit
There’s been no statements as to when Midjourney’s technology will start showing up in Meta’s products, or to what degree it will be baked into the company’s AI strategy.
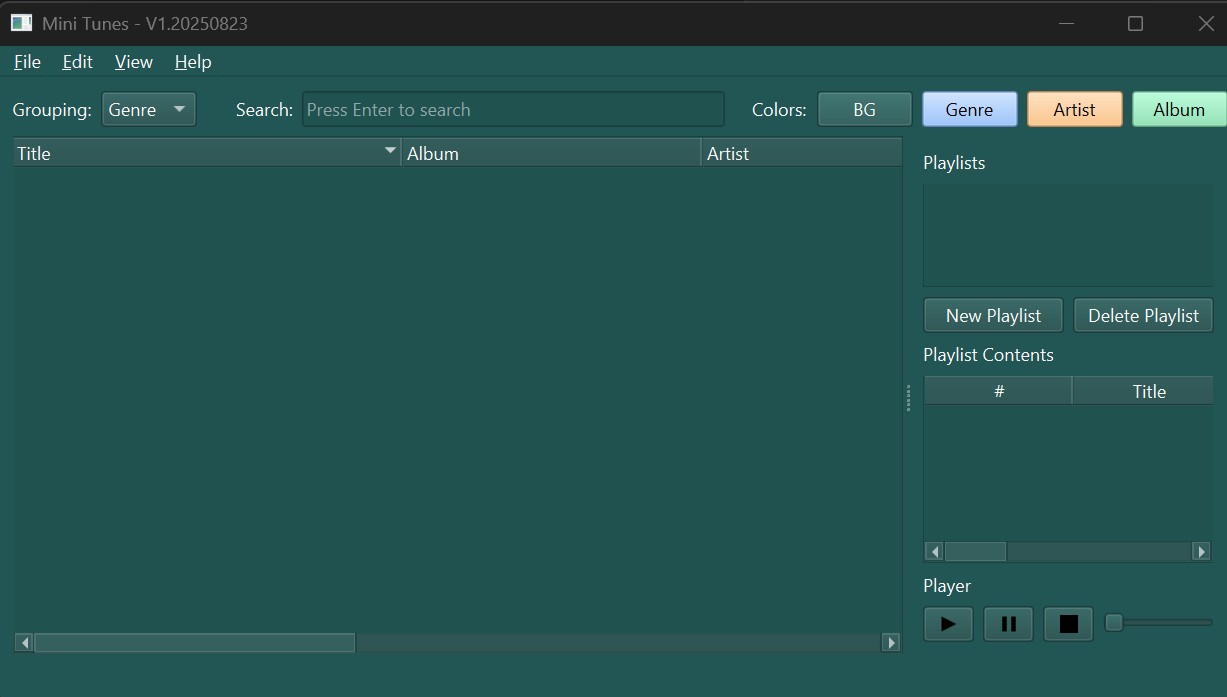
Tired of having iTunes messing up your mp3 library? … Time to try MiniTunes!
– Arrange your library by Genre, Artists or Albums. – Change UI colors at will. – Edit tags and create playlists. – Consolidate your library once for all. – Windows 64 only
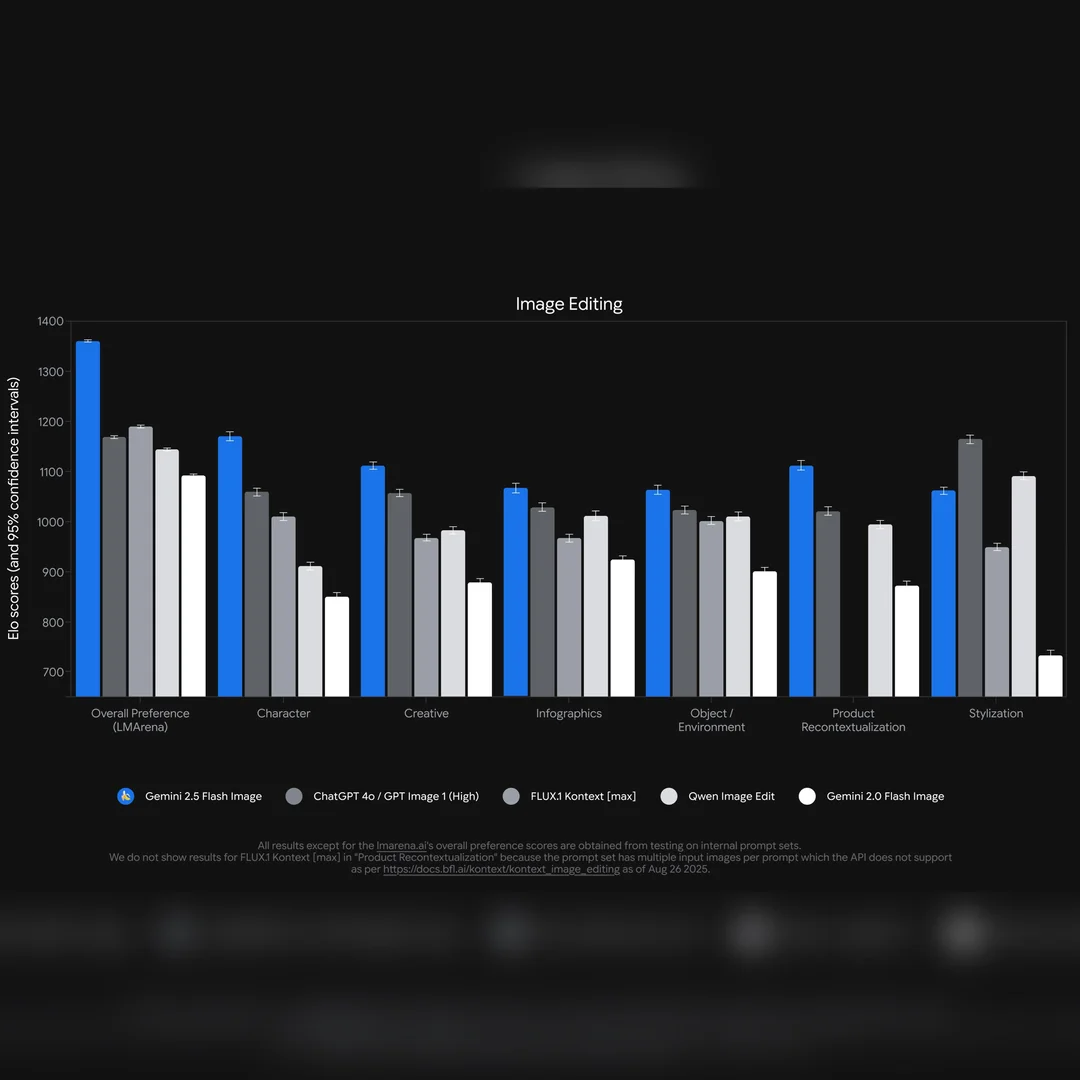
Qwen-Image-Edit is the image editing version of Qwen-Image. It is further trained based on the 20B Qwen-Image model, successfully extending Qwen-Image’s unique text rendering capabilities to editing tasks, enabling precise text editing. In addition, Qwen-Image-Edit feeds the input image into both Qwen2.5-VL (for visual semantic control) and the VAE Encoder (for visual appearance control), thus achieving dual semantic and appearance editing capabilities.
For years, tech firms were fighting a war for talent. Now they are waging war on talent.
This shift has led to a weakening of the social contract between employees and employers, with culture and employee values being sidelined in favor of financial discipline and free cash flow.
The operating environment has changed from a high tolerance for failure (where cheap capital and willing spenders accepted slipped dates and feature lag) to a very low – if not zero – tolerance for failure (fiscal discipline is in vogue again).
While preventing and containing mistakes staves off shocks to the income statement, it doesn’t fundamentally reduce costs. Years of payroll bloat – aggressive hiring, aggressive comp packages to attract and retain people – make labor the biggest cost in tech. …
Of course, companies can reduce their labor force through natural attrition. Other labor policy changes – return to office mandates, contraction of fringe benefits, reduction of job promotions, suspension of bonuses and comp freezes – encourage more people to exit voluntarily. It’s cheaper to let somebody self-select out than it is to lay them off. …
Employees recruited in more recent years from outside the ranks of tech were given the expectation that we’ll teach you what you need to know, we want you to join because we value what you bring to the table. That is no longer applicable. Runway for individual growth is very short in zero-tolerance-for-failure operating conditions. Job preservation, at least in the short term for this cohort, comes from completing corporate training and acquiring professional certifications. Training through community or experience is not in the cards. …
The ability to perform competently in multiple roles, the extra-curriculars, the self-directed enrichment, the ex-company leadership – all these things make no matter. The calculus is what you got paid versus how you performed on objective criteria relative to your cohort. Nothing more. …
Here is where the change in the social contract is perhaps the most blatant. In the “destination employer” years, the employee invested in the community and its values, and the employer rewarded the loyalty of its employees through things like runway for growth (stretch roles and sponsored work innovation) and tolerance for error (valuing demonstrable learning over perfection in execution). No longer. …