


COMPOSITION
DESIGN
COLOR
-
OpenColorIO standard
Read more: OpenColorIO standardhttps://www.provideocoalition.com/color-management-part-11-introducing-opencolorio/
OpenColorIO (OCIO) is a new open source project from Sony Imageworks.
Based on development started in 2003, OCIO enables color transforms and image display to be handled in a consistent manner across multiple graphics applications. Unlike other color management solutions, OCIO is geared towards motion-picture post production, with an emphasis on visual effects and animation color pipelines.

-
Light and Matter : The 2018 theory of Physically-Based Rendering and Shading by Allegorithmic
Read more: Light and Matter : The 2018 theory of Physically-Based Rendering and Shading by Allegorithmicacademy.substance3d.com/courses/the-pbr-guide-part-1
academy.substance3d.com/courses/the-pbr-guide-part-2

 Local copy:
Local copy:
-
Rec-2020 – TVs new color gamut standard used by Dolby Vision?
Read more: Rec-2020 – TVs new color gamut standard used by Dolby Vision?https://www.hdrsoft.com/resources/dri.html#bit-depth
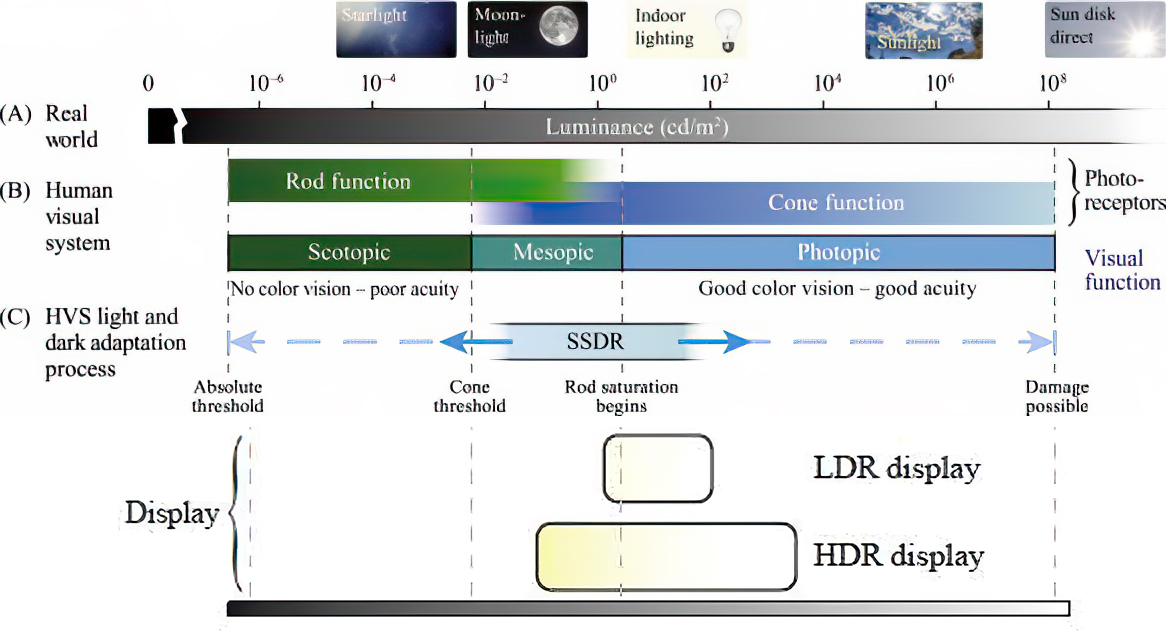
The dynamic range is a ratio between the maximum and minimum values of a physical measurement. Its definition depends on what the dynamic range refers to.
For a scene: Dynamic range is the ratio between the brightest and darkest parts of the scene.
For a camera: Dynamic range is the ratio of saturation to noise. More specifically, the ratio of the intensity that just saturates the camera to the intensity that just lifts the camera response one standard deviation above camera noise.
For a display: Dynamic range is the ratio between the maximum and minimum intensities emitted from the screen.
The Dynamic Range of real-world scenes can be quite high — ratios of 100,000:1 are common in the natural world. An HDR (High Dynamic Range) image stores pixel values that span the whole tonal range of real-world scenes. Therefore, an HDR image is encoded in a format that allows the largest range of values, e.g. floating-point values stored with 32 bits per color channel. Another characteristics of an HDR image is that it stores linear values. This means that the value of a pixel from an HDR image is proportional to the amount of light measured by the camera.
For TVs HDR is great, but it’s not the only new TV feature worth discussing.
Wide color gamut, or WCG, is often lumped in with HDR. While they’re often found together, they’re not intrinsically linked. Where HDR is an increase in the dynamic range of the picture (with contrast and brighter highlights in particular), a TV’s wide color gamut coverage refers to how much of the new, larger color gamuts a TV can display.
Wide color gamuts only really matter for HDR video sources like UHD Blu-rays and some streaming video, as only HDR sources are meant to take advantage of the ability to display more colors.
www.cnet.com/how-to/what-is-wide-color-gamut-wcg/
Color depth is only one aspect of color representation, expressing the precision with which the amount of each primary can be expressed through a pixel; the other aspect is how broad a range of colors can be expressed (the gamut)
Image rendering bit depth
Wide color gamuts include a greater number of colors than what most current TVs can display, so the greater a TV’s coverage of a wide color gamut, the more colors a TV will be able to reproduce.
When we talk about a color space or color gamut we refer to the range of color values stored in an image. The perception of these color also requires a display that has been tuned with to resolve these color profiles at best. This is often referred to as a ‘viewer lut’.
So this comes also usually paired with an increase in bit depth, going from the old 8 bit system (256 shades per color, with the potential of over 16.7 million colors: 256 green x 256 blue x 256 red) to 10 (1024+ shades per color, with access to over a billion colors) or higher bits, like 12 bit (4096 shades per RGB for 68 billion colors).
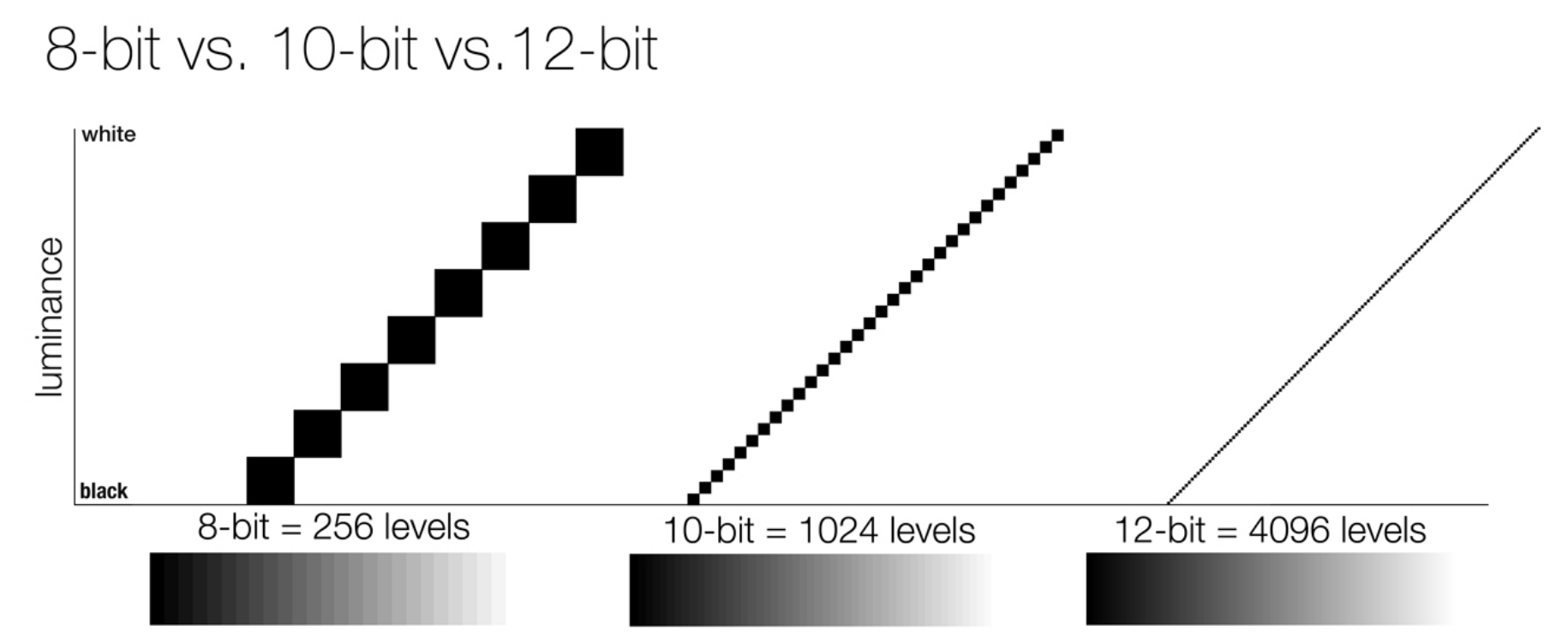
The advantage of higher bit depth is in the ability to bias color with the minimum loss.
For an extreme example, raising the brightness from a completely dark image allows for better reproduction, independently on the reproduction medium, due to the amount of data available at editing time:
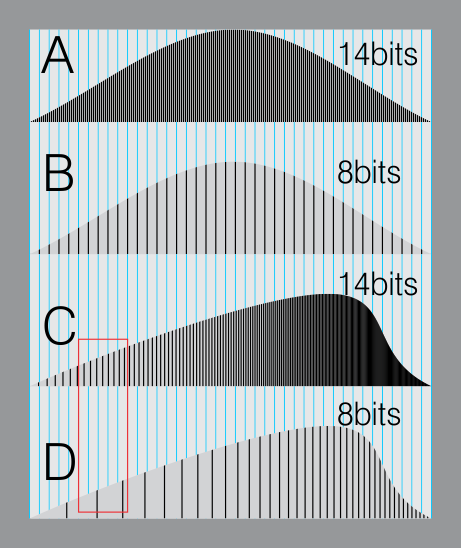
For reference, 8-bit images (i.e. 24 bits per pixel for a color image) are considered Low Dynamic Range.
They can store around 5 stops of light and each pixel carry a value from 0 (black) to 255 (white).
As a comparison, DSLR cameras can capture ~12-15 stops of light and they use RAW files to store the information.
https://www.cambridgeincolour.com/tutorials/dynamic-range.htm
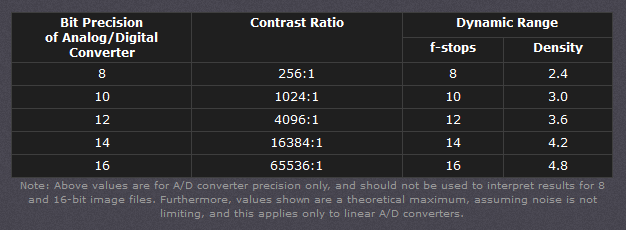
https://www.hdrsoft.com/resources/dri.html#bit-depth
Note that the number of bits itself may be a misleading indication of the real dynamic range that the image reproduces — converting a Low Dynamic Range image to a higher bit depth does not change its dynamic range, of course.
- 8-bit images (i.e. 24 bits per pixel for a color image) are considered Low Dynamic Range.
- 16-bit images (i.e. 48 bits per pixel for a color image) resulting from RAW conversion are still considered Low Dynamic Range, even though the range of values they can encode is significantly higher than for 8-bit images (65536 versus 256). Note that converting a RAW file involves applying a tonal curve that compresses the dynamic range of the RAW data so that the converted image shows correctly on low dynamic range monitors. The need to adapt the output image file to the dynamic range of the display is the factor that dictates how much the dynamic range is compressed, not the output bit-depth. By using 16 instead of 8 bits, you will gain precision but you will not gain dynamic range.
- 32-bit images (i.e. 96 bits per pixel for a color image) are considered High Dynamic Range.Unlike 8- and 16-bit images which can take a finite number of values, 32-bit images are coded using floating point numbers, which means the values they can take is unlimited.It is important to note, though, that storing an image in a 32-bit HDR format is a necessary condition for an HDR image but not a sufficient one. When an image comes from a single capture with a standard camera, it will remain a Low Dynamic Range image,
Also note that bit depth and dynamic range are often confused as one, but are indeed separate concepts and there is no direct one to one relationship between them. Bit depth is about capacity, dynamic range is about the actual ratio of data stored.
The bit depth of a capturing or displaying device gives you an indication of its dynamic range capacity. That is, the highest dynamic range that the device would be capable of reproducing if all other constraints are eliminated.https://rawpedia.rawtherapee.com/Bit_Depth
Finally, note that there are two ways to “count” bits for an image — either the number of bits per color channel (BPC) or the number of bits per pixel (BPP). A bit (0,1) is the smallest unit of data stored in a computer.
For a grayscale image, 8-bit means that each pixel can be one of 256 levels of gray (256 is 2 to the power 8).
For an RGB color image, 8-bit means that each one of the three color channels can be one of 256 levels of color.
Since each pixel is represented by 3 colors in this case, 8-bit per color channel actually means 24-bit per pixel.Similarly, 16-bit for an RGB image means 65,536 levels per color channel and 48-bit per pixel.
To complicate matters, when an image is classified as 16-bit, it just means that it can store a maximum 65,535 values. It does not necessarily mean that it actually spans that range. If the camera sensors can not capture more than 12 bits of tonal values, the actual bit depth of the image will be at best 12-bit and probably less because of noise.
The following table attempts to summarize the above for the case of an RGB color image.
Type of digital support Bit depth per color channel Bit depth per pixel FStops Theoretical maximum Dynamic Range Reality 8-bit 8 24 8 256:1 most consumer images 12-bit CCD 12 36 12 4,096:1 real maximum limited by noise 14-bit CCD 14 42 14 16,384:1 real maximum limited by noise 16-bit TIFF (integer) 16 48 16 65,536:1 bit-depth in this case is not directly related to the dynamic range captured 16-bit float EXR 16 48 30 65,536:1 values are distributed more closely in the (lower) darker tones than in the (higher) lighter ones, thus allowing for a more accurate description of the tones more significant to humans. The range of normalized 16-bit floats can represent thirty stops of information with 1024 steps per stop. We have eighteen and a half stops over middle gray, and eleven and a half below. The denormalized numbers provide an additional ten stops with decreasing precision per stop.
http://download.nvidia.com/developer/GPU_Gems/CD_Image/Image_Processing/OpenEXR/OpenEXR-1.0.6/doc/#recsHDR image (e.g. Radiance format) 32 96 “infinite” 4.3 billion:1 real maximum limited by the captured dynamic range 32-bit floats are often called “single-precision” floats, and 64-bit floats are often called “double-precision” floats. 16-bit floats therefore are called “half-precision” floats, or just “half floats”.
https://petapixel.com/2018/09/19/8-12-14-vs-16-bit-depth-what-do-you-really-need
On a separate note, even Photoshop does not handle 16bit per channel. Photoshop does actually use 16-bits per channel. However, it treats the 16th digit differently – it is simply added to the value created from the first 15-digits. This is sometimes called 15+1 bits. This means that instead of 216 possible values (which would be 65,536 possible values) there are only 215+1 possible values (which is 32,768 +1 = 32,769 possible values).
Rec-601 (for the older SDTV format, very similar to rec-709) and Rec-709 (the HDTV’s recommended set of color standards, at times also referred to sRGB, although not exactly the same) are currently the most spread color formats and hardware configurations in the world.
Following those you can find the larger P3 gamut, more commonly used in theaters and in digital production houses (with small variations and improvements to color coverage), as well as most of best 4K/WCG TVs.
And a new standard is now promoted against P3, referred to Rec-2020 and UHDTV.

It is still debatable if this is going to be adopted at consumer level beyond the P3, mainly due to lack of hardware supporting it. But initial tests do prove that it would be a future proof investment.
www.colour-science.org/anders-langlands/
Rec. 2020 is ultimately designed for television, and not cinema. Therefore, it is to be expected that its properties must behave according to current signal processing standards. In this respect, its foundation is based on current HD and SD video signal characteristics.
As far as color bit depth is concerned, it allows for a maximum of 12 bits, which is more than enough for humans.
Comparing standards, REC-709 covers 35.9% of the human visible spectrum. P3 45.5%. And REC-2020 75.8%.
https://www.avsforum.com/forum/166-lcd-flat-panel-displays/2812161-what-color-volume.htmlComparing coverage to hardware devices
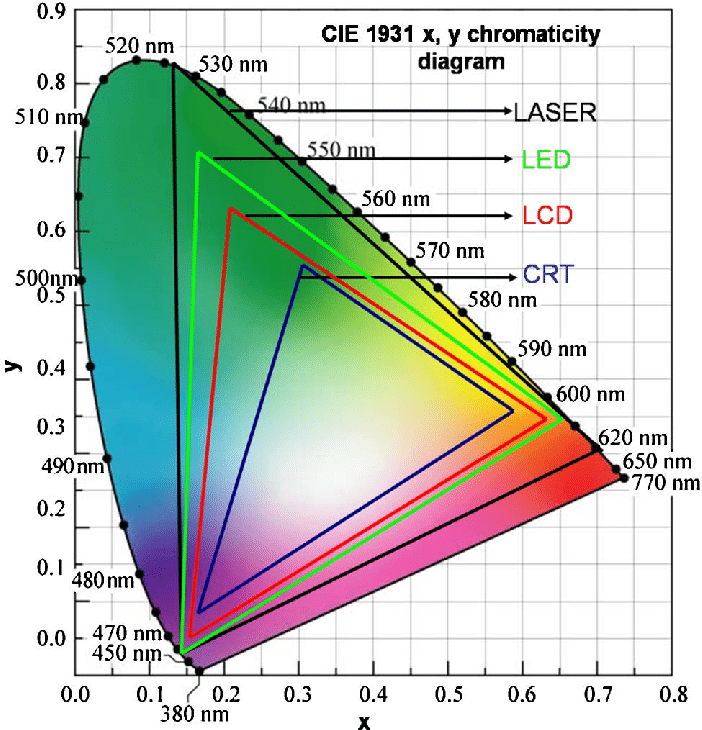
To note that all the new standards generally score very high on the Pointer’s Gamut chart. But with REC-2020 scoring 99.9% vs P3 at 88.2%.
www.tftcentral.co.uk/articles/pointers_gamut.htmhttps://www.slideshare.net/hpduiker/acescg-a-common-color-encoding-for-visual-effects-applications
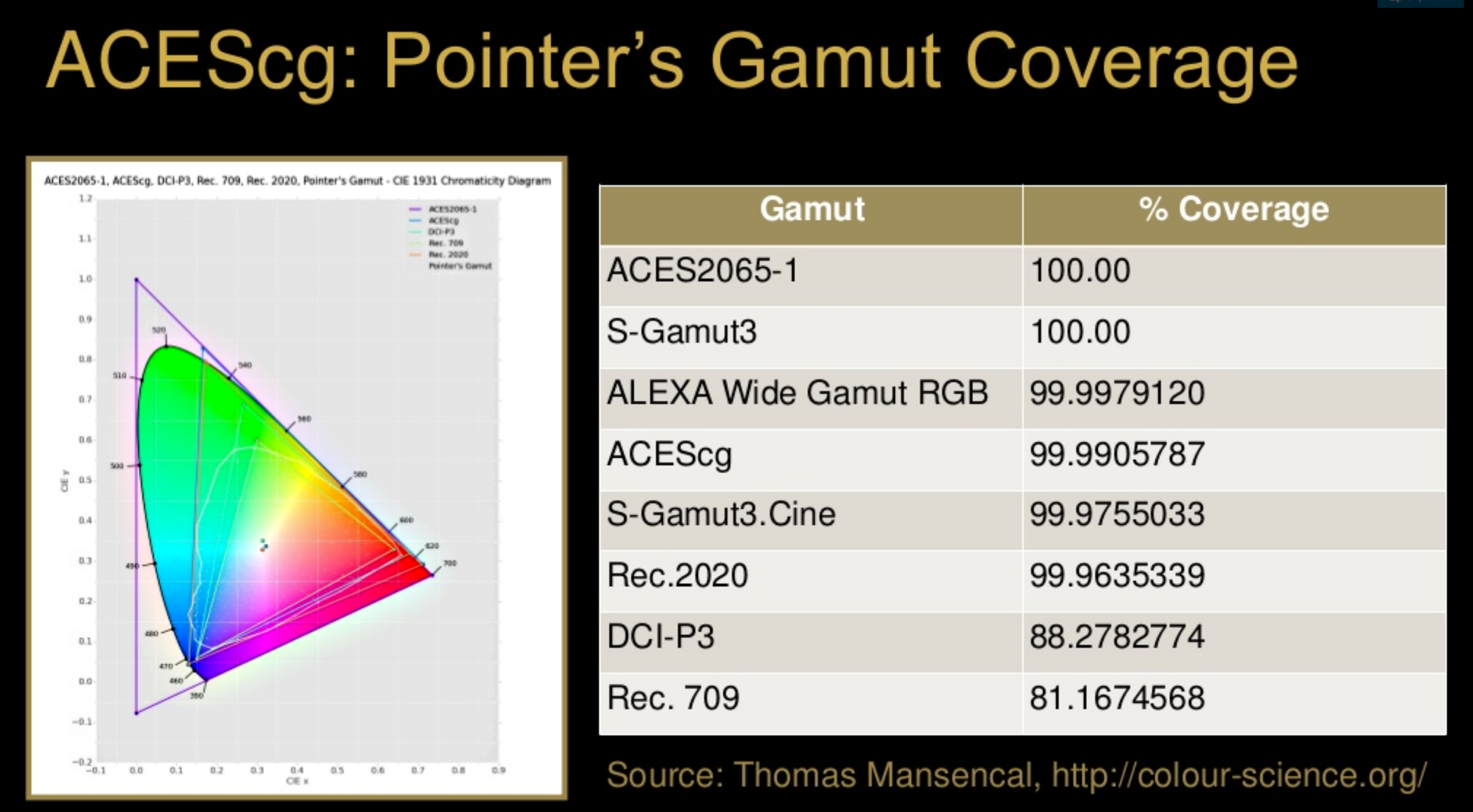
The Pointer’s gamut is (an approximation of) the gamut of real surface colors as can be seen by the human eye, based on the research by Michael R. Pointer (1980). What this means is that every color that can be reflected by the surface of an object of any material is inside the Pointer’s gamut. Basically establishing a widely respected target for color reproduction. Visually, Pointers Gamut represents the colors we see about us in the natural world. Colors outside Pointers Gamut include those that do not occur naturally, such as neon lights and computer-generated colors possible in animation. Which would partially be accounted for with the new gamuts.
cinepedia.com/picture/color-gamut/
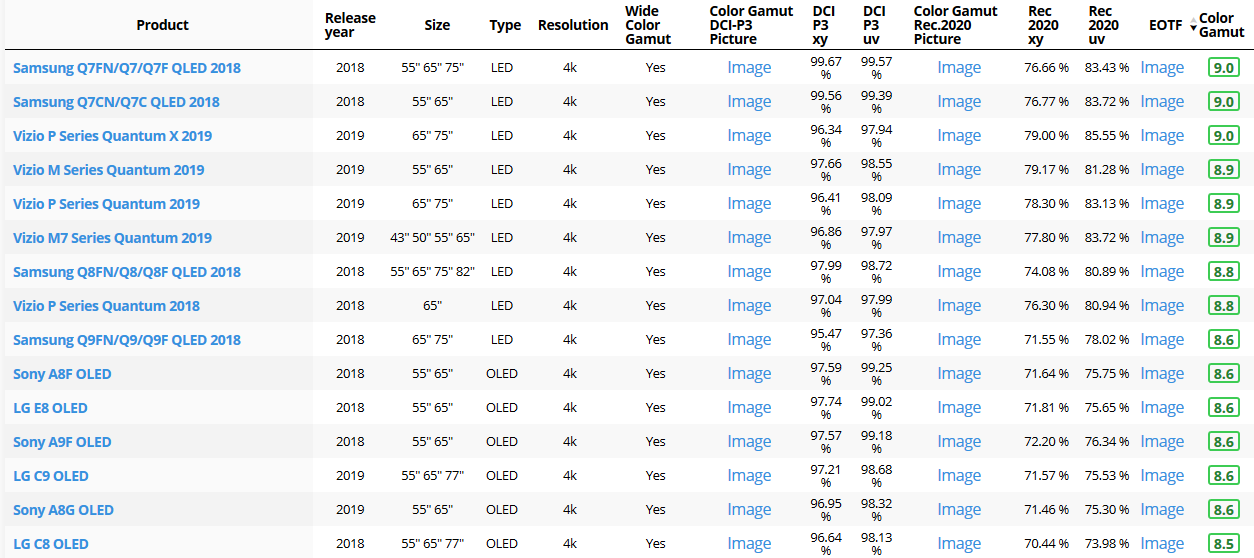
Not all current TVs can support the full spread of the new gamuts. Here is a list of modern TVs’ color coverage in percentage:
www.rtings.com/tv/tests/picture-quality/wide-color-gamut-rec-709-dci-p3-rec-2020There are no TVs that can come close to displaying all the colors within Rec.2020, and there likely won’t be for at least a few years. However, to help future-proof the technology, Rec.2020 support is already baked into the HDR spec. That means that the same genuine HDR media that fills the DCI P3 space on a compatible TV now, will in a few years also fill Rec.2020 on a TV supporting that larger space.
Rec.2020’s main gains are in the number of new tones of green that it will display, though it also offers improvements to the number of blue and red colors as well. Altogether, Rec.2020 will cover about 75% of the visual spectrum, which is a sizeable increase in coverage even over DCI P3.
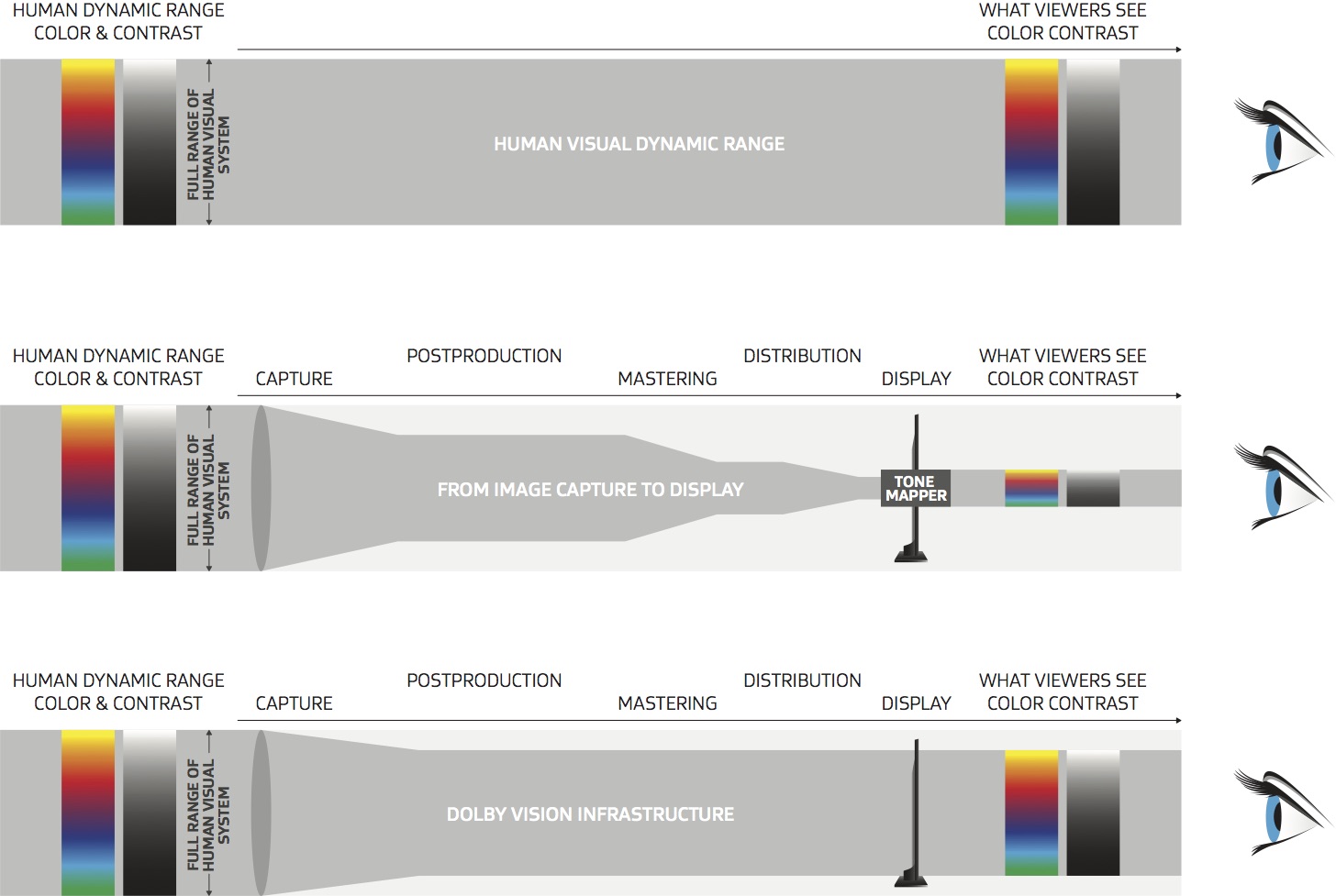
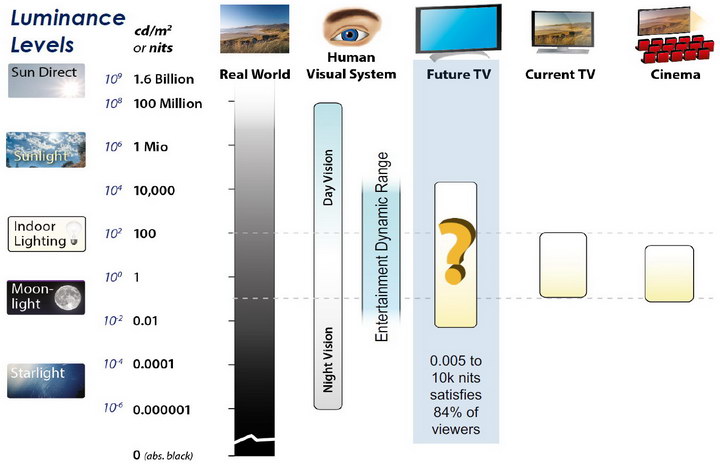
Dolby Vision
https://www.highdefdigest.com/news/show/what-is-dolby-vision/39049
https://www.techhive.com/article/3237232/dolby-vision-vs-hdr10-which-is-best.html
Dolby Vision is a proprietary end-to-end High Dynamic Range (HDR) format that covers content creation and playback through select cinemas, Ultra HD displays, and 4K titles. Like other HDR standards, the process uses expanded brightness to improve contrast between dark and light aspects of an image, bringing out deeper black levels and more realistic details in specular highlights — like the sun reflecting off of an ocean — in specially graded Dolby Vision material.
The iPhone 12 Pro gets the ability to record 4K 10-bit HDR video. According to Apple, it is the very first smartphone that is capable of capturing Dolby Vision HDR.
The iPhone 12 Pro takes two separate exposures and runs them through Apple’s custom image signal processor to create a histogram, which is a graph of the tonal values in each frame. The Dolby Vision metadata is then generated based on that histogram. In Laymen’s terms, it is essentially doing real-time grading while you are shooting. This is only possible due to the A14 Bionic chip.
Dolby Vision also allows for 12-bit color, as opposed to HDR10’s and HDR10+’s 10-bit color. While no retail TV we’re aware of supports 12-bit color, Dolby claims it can be down-sampled in such a way as to render 10-bit color more accurately.

Resources for more reading:
https://www.avsforum.com/forum/166-lcd-flat-panel-displays/2812161-what-color-volume.html
wolfcrow.com/say-hello-to-rec-2020-the-color-space-of-the-future/
www.cnet.com/news/ultra-hd-tv-color-part-ii-the-future/












LIGHTING
-
Light properties
Read more: Light propertiesHow It Works – Issue 114
https://www.howitworksdaily.com/
-
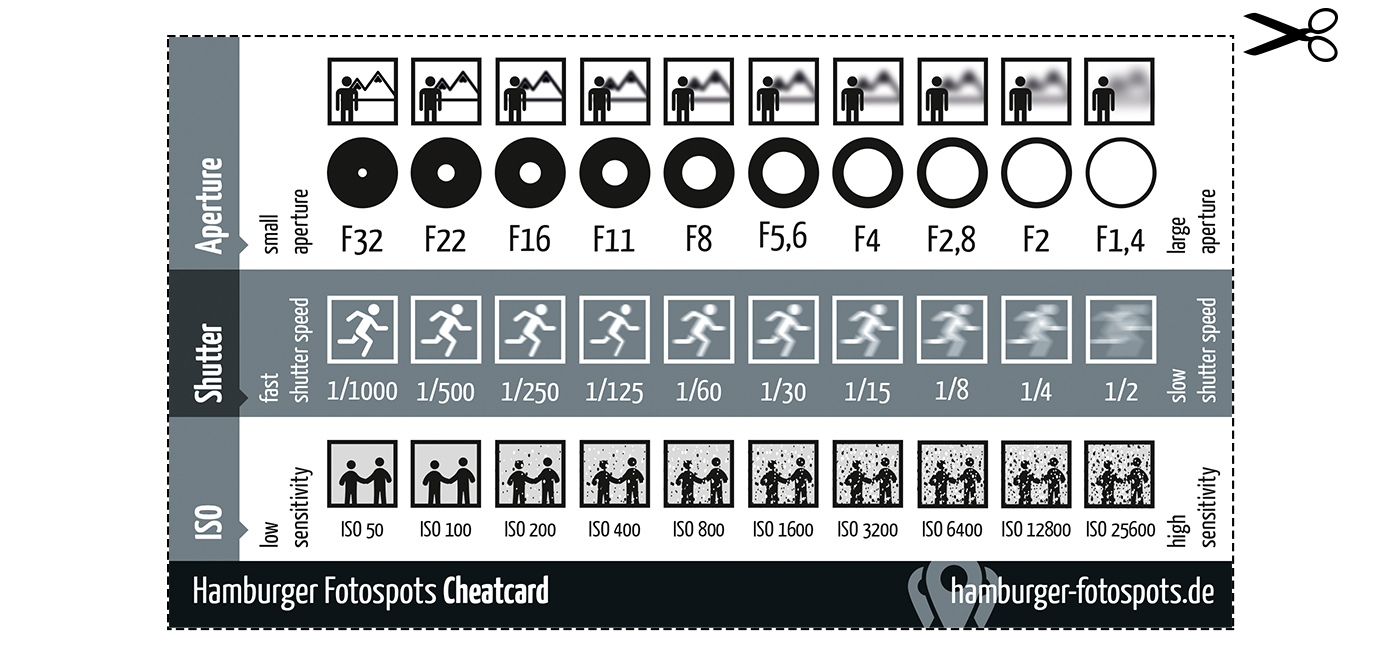
Photography basics: How Exposure Stops (Aperture, Shutter Speed, and ISO) Affect Your Photos – cheat sheet cards
Read more: Photography basics: How Exposure Stops (Aperture, Shutter Speed, and ISO) Affect Your Photos – cheat sheet cardsAlso see:
https://www.pixelsham.com/2018/11/22/exposure-value-measurements/
https://www.pixelsham.com/2016/03/03/f-stop-vs-t-stop/

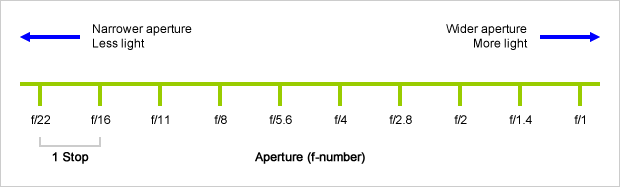
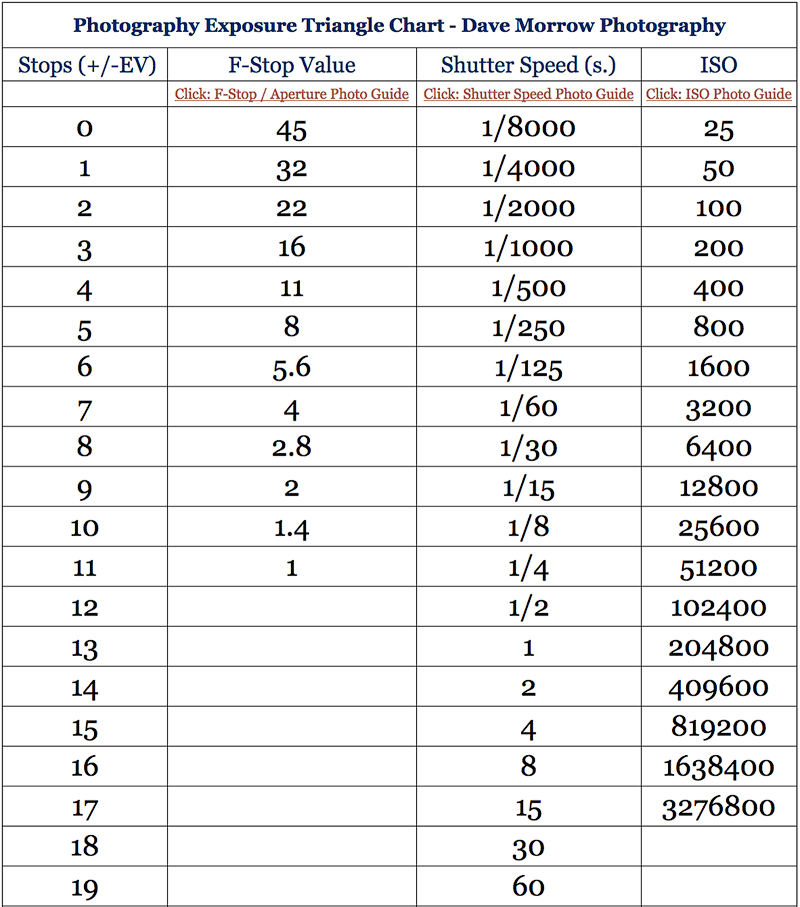
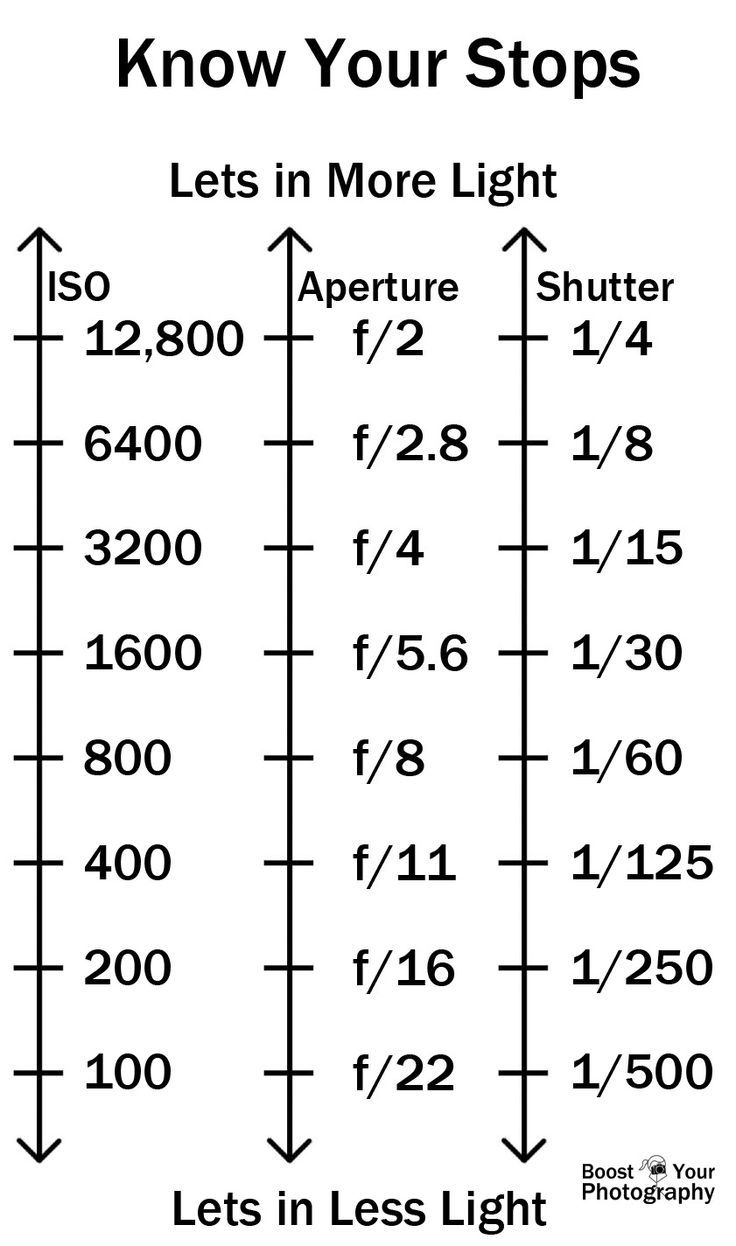
An exposure stop is a unit measurement of Exposure as such it provides a universal linear scale to measure the increase and decrease in light, exposed to the image sensor, due to changes in shutter speed, iso and f-stop.
+-1 stop is a doubling or halving of the amount of light let in when taking a photo
1 EV (exposure value) is just another way to say one stop of exposure change.
https://www.photographymad.com/pages/view/what-is-a-stop-of-exposure-in-photography
Same applies to shutter speed, iso and aperture.
Doubling or halving your shutter speed produces an increase or decrease of 1 stop of exposure.
Doubling or halving your iso speed produces an increase or decrease of 1 stop of exposure.


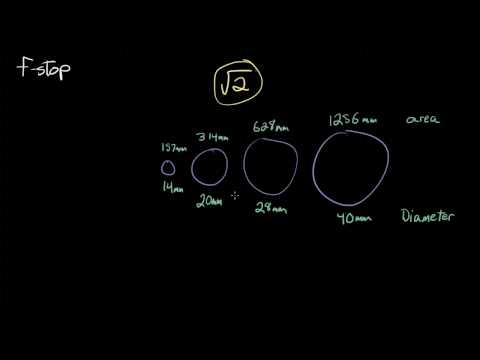
Because of the way f-stop numbers are calculated (ratio of focal length/lens diameter, where focal length is the distance between the lens and the sensor), an f-stop doesn’t relate to a doubling or halving of the value, but to the doubling/halving of the area coverage of a lens in relation to its focal length. And as such, to a multiplying or dividing by 1.41 (the square root of 2). For example, going from f/2.8 to f/4 is a decrease of 1 stop because 4 = 2.8 * 1.41. Changing from f/16 to f/11 is an increase of 1 stop because 11 = 16 / 1.41.
A wider aperture means that light proceeding from the foreground, subject, and background is entering at more oblique angles than the light entering less obliquely.
Consider that absolutely everything is bathed in light, therefore light bouncing off of anything is effectively omnidirectional. Your camera happens to be picking up a tiny portion of the light that’s bouncing off into infinity.
Now consider that the wider your iris/aperture, the more of that omnidirectional light you’re picking up:
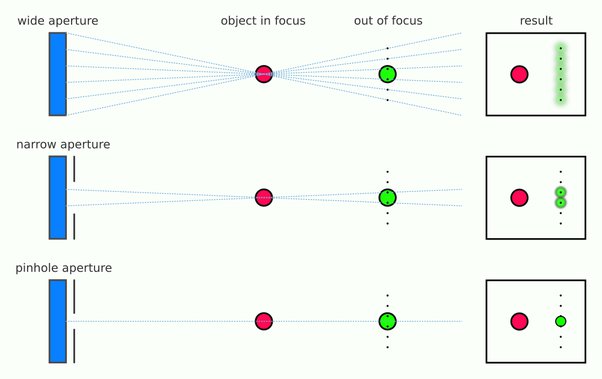
When you have a very narrow iris you are eliminating a lot of oblique light. Whatever light enters, from whatever distance, enters moderately parallel as a whole. When you have a wide aperture, much more light is entering at a multitude of angles. Your lens can only focus the light from one depth – the foreground/background appear blurred because it cannot be focused on.
https://frankwhitephotography.com/index.php?id=28:what-is-a-stop-in-photography
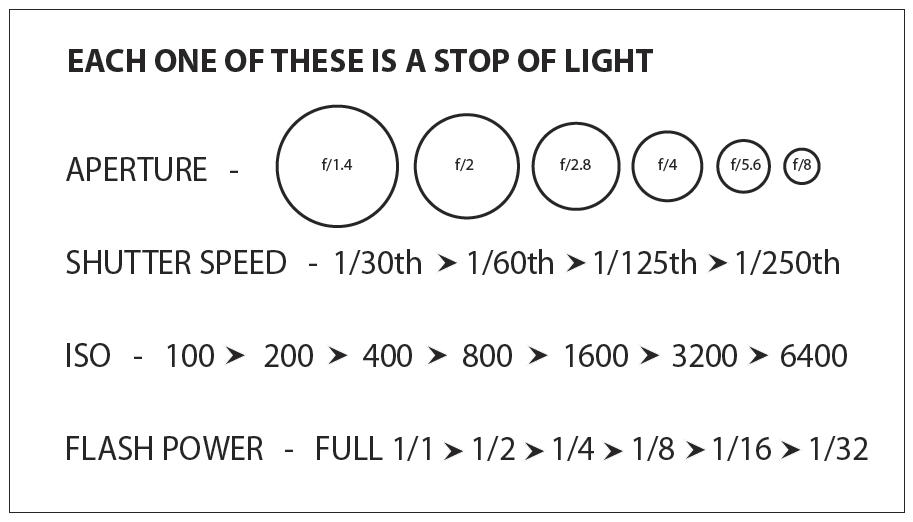
The great thing about stops is that they give us a way to directly compare shutter speed, aperture diameter, and ISO speed. This means that we can easily swap these three components about while keeping the overall exposure the same.
http://lifehacker.com/how-aperture-shutter-speed-and-iso-affect-pictures-sh-1699204484
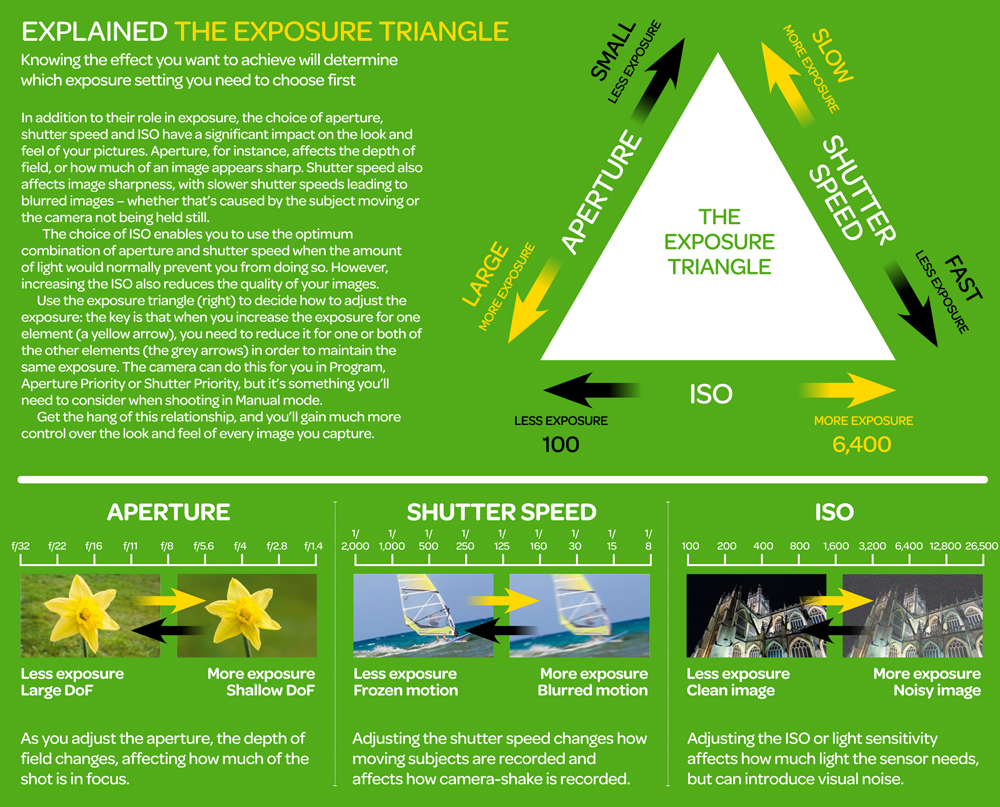
https://www.techradar.com/how-to/the-exposure-triangle

https://www.videoschoolonline.com/what-is-an-exposure-stop
Note. All three of these measurements (aperture, shutter, iso) have full stops, half stops and third stops, but if you look at the numbers they aren’t always consistent. For example, a one third stop between ISO100 and ISO 200 would be ISO133, yet most cameras are marked at ISO125.
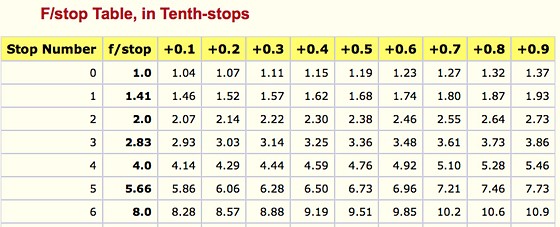
Third-stops are especially important as they’re the increment that most cameras use for their settings. These are just imaginary divisions in each stop.
From a practical standpoint manufacturers only standardize the full stops, meaning that while they try and stay somewhat consistent there is some rounding up going on between the smaller numbers.


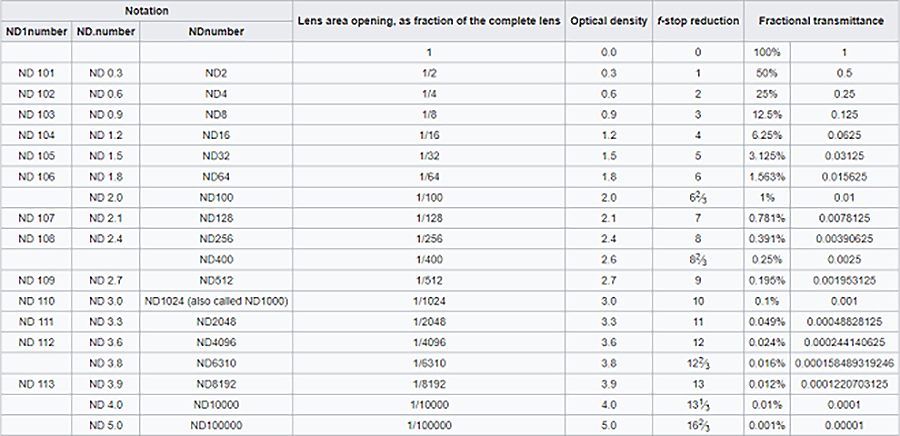
Note that ND Filters directly modify the exposure triangle.
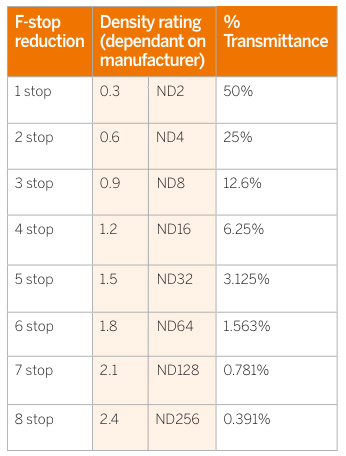


-
Debayer – A free command line tool to convert camera raw images into scene-linear exr
Read more: Debayer – A free command line tool to convert camera raw images into scene-linear exr
https://github.com/jedypod/debayer
The only required dependency is oiiotool. However other “debayer engines” are also supported.
- OpenImageIO – oiiotool is used for converting debayered tif images to exr.
- Debayer Engines
- RawTherapee – Powerful raw development software used to decode raw images. High quality, good selection of debayer algorithms, and more advanced raw processing like chromatic aberration removal.
- LibRaw – dcraw_emu commandline utility included with LibRaw. Optional alternative for debayer. Simple, fast and effective.
- Darktable – Uses darktable-cli plus an xmp config to process.
- vkdt – uses vkdt-cli to debayer. Pretty experimental still. Uses Vulkan for image processing. Stupidly fast. Pretty limited.
-
Ethan Roffler interviews CG Supervisor Daniele Tosti
Read more: Ethan Roffler interviews CG Supervisor Daniele TostiEthan Roffler
I recently had the honor of interviewing this VFX genius and gained great insight into what it takes to work in the entertainment industry. Keep in mind, these questions are coming from an artist’s perspective but can be applied to any creative individual looking for some wisdom from a professional. So grab a drink, sit back, and enjoy this fun and insightful conversation.
Ethan
To start, I just wanted to say thank you so much for taking the time for this interview!Daniele
My pleasure.
When I started my career I struggled to find help. Even people in the industry at the time were not that helpful. Because of that, I decided very early on that I was going to do exactly the opposite. I spend most of my weekends talking or helping students. ;)Ethan
That’s awesome! I have also come across the same struggle! Just a heads up, this will probably be the most informal interview you’ll ever have haha! Okay, so let’s start with a small introduction!Daniele
Short introduction: I worked very hard and got lucky enough to work on great shows with great people. ;) Slightly longer version: I started working for a TV channel, very early, while I was learning about CG. Slowly made my way across the world, working along very great people and amazing shows. I learned that to be successful in this business, you have to really love what you do as much as respecting the people around you. What you do will improve to the final product; the way you work with people will make a difference in your life.
Ethan
How long have you been an artist?Daniele
Loaded question. I believe I am still trying and craving to be one. After each production I finish I realize how much I still do not know. And how many things I would like to try. I guess in my CG Sup and generalist world, being an artist is about learning as much about the latest technologies and production cycles as I can, then putting that in practice. Having said that, I do consider myself a cinematographer first, as I have been doing that for about 25 years now.Ethan
Words of true wisdom, the more I know the less I know:) How did you get your start in the industry?
How did you break into such a competitive field?Daniele
There were not many schools when I started. It was all about a few magazines, some books, and pushing software around trying to learn how to make pretty images. Opportunities opened because of that knowledge! The true break was learning to work hard to achieve a Suspension of Disbelief in my work that people would recognize as such. It’s not something everyone can do, but I was fortunate to not be scared of working hard, being a quick learner and having very good supervisors and colleagues to learn from.Ethan
Which do you think is better, having a solid art degree or a strong portfolio?Daniele
Very good question. A strong portfolio will get you a job now. A solid strong degree will likely get you a job for a longer period. Let me digress here; Working as an artist is not about being an artist, it’s about making money as an artist. Most people fail to make that difference and have either a poor career or lack the understanding to make a stable one. One should never mix art with working as an artist. You can do both only if you understand business and are fair to yourself.
Ethan
That’s probably the most helpful answer to that question I have ever heard.
What’s some advice you can offer to someone just starting out who wants to break into the industry?Daniele
Breaking in the industry is not just about knowing your art. It’s about knowing good business practices. Prepare a good demo reel based on the skill you are applying for; research all the places where you want to apply and why; send as many reels around; follow up each reel with a phone call. Business is all about right time, right place.Ethan
A follow-up question to that is: Would you consider it a bad practice to send your demo reels out in mass quantity rather than focusing on a handful of companies to research and apply for?Daniele
Depends how desperate you are… I would say research is a must. To improve your options, you need to know which company is working on what and what skills they are after. If you were selling vacuum cleaners you probably would not want to waste energy contacting shoemakers or cattle farmers.Ethan
What do you think the biggest killer of creativity and productivity is for you?Daniele
Money…If you were thinking as an artist. ;) If you were thinking about making money as an artist… then I would say “thinking that you work alone”.Ethan
Best. Answer. Ever.
What are ways you fight complacency and maintain fresh ideas, outlooks, and perspectivesDaniele
Two things: Challenge yourself to go outside your comfort zone. And think outside of the box.Ethan
What are the ways/habits you have that challenge yourself to get out of your comfort zone and think outside the box?Daniele
If you think you are a good character painter, pick up a camera and go take pictures of amazing landscapes. If you think you are good only at painting or sketching, learn how to code in python. If you cannot solve a problem, that being a project or a person, learn to ask for help or learn about looking at the problem from various perspectives. If you are introvert, learn to be extrovert. And vice versa. And so on…
Ethan
How do you avoid burnout?Daniele
Oh… I wish I learned about this earlier. I think anyone that has a passion in something is at risk of burning out. Artists, more than many, because we see the world differently and our passion goes deep. You avoid burnouts by thinking that you are in a long term plan and that you have an obligation to pay or repay your talent by supporting and cherishing yourself and your family, not your paycheck. You do this by treating your art as a business and using business skills when dealing with your career and using artistic skills only when you are dealing with a project itself.Ethan
Looking back, what was a big defining moment for you?Daniele
Recognizing that people around you, those being colleagues, friends or family, come first.
It changed my career overnight.Ethan
Who are some of your personal heroes?Daniele
Too many to list. Most recently… James Cameron; Joe Letteri; Lawrence Krauss; Richard Dawkins. Because they all mix science, art, and poetry in their own way.Ethan
Last question:
What’s your dream job? ;)Daniele
Teaching artists to be better at being business people… as it will help us all improve our lives and the careers we took…
Being a VFX artist is fundamentally based on mistrust.
This because schedules, pipelines, technology, creative calls… all have a native and naive instability to them that causes everyone to grow a genuine but beneficial lack of trust in the status quo. This is a fine balance act to build into your character. The VFX motto: “Love everyone but trust no one” is born on that.





























COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
