


COMPOSITION
-
Photography basics: Depth of Field and composition
Read more: Photography basics: Depth of Field and compositionDepth of field is the range within which focusing is resolved in a photo.
Aperture has a huge affect on to the depth of field.
Changing the f-stops (f/#) of a lens will change aperture and as such the DOF.
f-stops are a just certain number which is telling you the size of the aperture. That’s how f-stop is related to aperture (and DOF).
If you increase f-stops, it will increase DOF, the area in focus (and decrease the aperture). On the other hand, decreasing the f-stop it will decrease DOF (and increase the aperture).
The red cone in the figure is an angular representation of the resolution of the system. Versus the dotted lines, which indicate the aperture coverage. Where the lines of the two cones intersect defines the total range of the depth of field.
This image explains why the longer the depth of field, the greater the range of clarity.

-
StudioBinder – Roger Deakins on How to Choose a Camera Lens — Cinematography Composition Techniques
Read more: StudioBinder – Roger Deakins on How to Choose a Camera Lens — Cinematography Composition Techniques
https://www.studiobinder.com/blog/camera-lens-buying-guide/
https://www.studiobinder.com/blog/e-books/camera-lenses-explained-volume-1-ebook















DESIGN
COLOR
-
OLED vs QLED – What TV is better?
Read more: OLED vs QLED – What TV is better?
Supported by LG, Philips, Panasonic and Sony sell the OLED system TVs.
OLED stands for “organic light emitting diode.”
It is a fundamentally different technology from LCD, the major type of TV today.
OLED is “emissive,” meaning the pixels emit their own light.Samsung is branding its best TVs with a new acronym: “QLED”
QLED (according to Samsung) stands for “quantum dot LED TV.”
It is a variation of the common LED LCD, adding a quantum dot film to the LCD “sandwich.”
QLED, like LCD, is, in its current form, “transmissive” and relies on an LED backlight.OLED is the only technology capable of absolute blacks and extremely bright whites on a per-pixel basis. LCD definitely can’t do that, and even the vaunted, beloved, dearly departed plasma couldn’t do absolute blacks.
QLED, as an improvement over OLED, significantly improves the picture quality. QLED can produce an even wider range of colors than OLED, which says something about this new tech. QLED is also known to produce up to 40% higher luminance efficiency than OLED technology. Further, many tests conclude that QLED is far more efficient in terms of power consumption than its predecessor, OLED.

When analyzing TVs color, it may be beneficial to consider at least 3 elements:
“Color Depth”, “Color Gamut”, and “Dynamic Range”.Color Depth (or “Bit-Depth”, e.g. 8-bit, 10-bit, 12-bit) determines how many distinct color variations (tones/shades) can be viewed on a given display.
Color Gamut (e.g. WCG) determines which specific colors can be displayed from a given “Color Space” (Rec.709, Rec.2020, DCI-P3) (i.e. the color range).
Dynamic Range (SDR, HDR) determines the luminosity range of a specific color – from its darkest shade (or tone) to its brightest.
The overall brightness range of a color will be determined by a display’s “contrast ratio”, that is, the ratio of luminance between the darkest black that can be produced and the brightest white.
Color Volume is the “Color Gamut” + the “Dynamic/Luminosity Range”.
A TV’s Color Volume will not only determine which specific colors can be displayed (the color range) but also that color’s luminosity range, which will have an affect on its “brightness”, and “colorfulness” (intensity and saturation).The better the colour volume in a TV, the closer to life the colours appear.
QLED TV can express nearly all of the colours in the DCI-P3 colour space, and of those colours, express 100% of the colour volume, thereby producing an incredible range of colours.
With OLED TV, when the image is too bright, the percentage of the colours in the colour volume produced by the TV drops significantly. The colours get washed out and can only express around 70% colour volume, making the picture quality drop too.
Note. OLED TV uses organic material, so it may lose colour expression as it ages.
Resources for more reading and comparison below
www.avsforum.com/forum/166-lcd-flat-panel-displays/2812161-what-color-volume.html
www.newtechnologytv.com/qled-vs-oled/
news.samsung.com/za/qled-tv-vs-oled-tv
www.cnet.com/news/qled-vs-oled-samsungs-tv-tech-and-lgs-tv-tech-are-not-the-same/

-
HDR and Color
Read more: HDR and Colorhttps://www.soundandvision.com/content/nits-and-bits-hdr-and-color
In HD we often refer to the range of available colors as a color gamut. Such a color gamut is typically plotted on a two-dimensional diagram, called a CIE chart, as shown in at the top of this blog. Each color is characterized by its x/y coordinates.

Good enough for government work, perhaps. But for HDR, with its higher luminance levels and wider color, the gamut becomes three-dimensional.

For HDR the color gamut therefore becomes a characteristic we now call the color volume. It isn’t easy to show color volume on a two-dimensional medium like the printed page or a computer screen, but one method is shown below. As the luminance becomes higher, the picture eventually turns to white. As it becomes darker, it fades to black. The traditional color gamut shown on the CIE chart is simply a slice through this color volume at a selected luminance level, such as 50%.
Three different color volumes—we still refer to them as color gamuts though their third dimension is important—are currently the most significant. The first is BT.709 (sometimes referred to as Rec.709), the color gamut used for pre-UHD/HDR formats, including standard HD.
The largest is known as BT.2020; it encompasses (roughly) the range of colors visible to the human eye (though ET might find it insufficient!).
Between these two is the color gamut used in digital cinema, known as DCI-P3.

sRGB

D65

-
Mysterious animation wins best illusion of 2011 – Motion silencing illusion
Read more: Mysterious animation wins best illusion of 2011 – Motion silencing illusionThe 2011 Best Illusion of the Year uses motion to render color changes invisible, and so reveals a quirk in our visual systems that is new to scientists.
https://en.wikipedia.org/wiki/Motion_silencing_illusion
“It is a really beautiful effect, revealing something about how our visual system works that we didn’t know before,” said Daniel Simons, a professor at the University of Illinois, Champaign-Urbana. Simons studies visual cognition, and did not work on this illusion. Before its creation, scientists didn’t know that motion had this effect on perception, Simons said.
A viewer stares at a speck at the center of a ring of colored dots, which continuously change color. When the ring begins to rotate around the speck, the color changes appear to stop. But this is an illusion. For some reason, the motion causes our visual system to ignore the color changes. (You can, however, see the color changes if you follow the rotating circles with your eyes.)

-
Photography basics: Why Use a (MacBeth) Color Chart?
Read more: Photography basics: Why Use a (MacBeth) Color Chart?Start here: https://www.pixelsham.com/2013/05/09/gretagmacbeth-color-checker-numeric-values/
https://www.studiobinder.com/blog/what-is-a-color-checker-tool/



In LightRoom

in Final Cut

in Nuke
Note: In Foundry’s Nuke, the software will map 18% gray to whatever your center f/stop is set to in the viewer settings (f/8 by default… change that to EV by following the instructions below).
You can experiment with this by attaching an Exposure node to a Constant set to 0.18, setting your viewer read-out to Spotmeter, and adjusting the stops in the node up and down. You will see that a full stop up or down will give you the respective next value on the aperture scale (f8, f11, f16 etc.).One stop doubles or halves the amount or light that hits the filmback/ccd, so everything works in powers of 2.
So starting with 0.18 in your constant, you will see that raising it by a stop will give you .36 as a floating point number (in linear space), while your f/stop will be f/11 and so on.If you set your center stop to 0 (see below) you will get a relative readout in EVs, where EV 0 again equals 18% constant gray.

In other words. Setting the center f-stop to 0 means that in a neutral plate, the middle gray in the macbeth chart will equal to exposure value 0. EV 0 corresponds to an exposure time of 1 sec and an aperture of f/1.0.
This will set the sun usually around EV12-17 and the sky EV1-4 , depending on cloud coverage.
To switch Foundry’s Nuke’s SpotMeter to return the EV of an image, click on the main viewport, and then press s, this opens the viewer’s properties. Now set the center f-stop to 0 in there. And the SpotMeter in the viewport will change from aperture and fstops to EV.




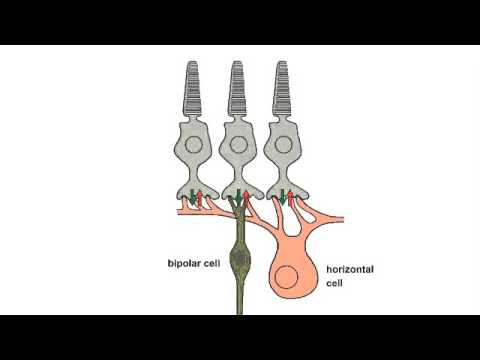







LIGHTING
-
What’s the Difference Between Ray Casting, Ray Tracing, Path Tracing and Rasterization? Physical light tracing…
Read more: What’s the Difference Between Ray Casting, Ray Tracing, Path Tracing and Rasterization? Physical light tracing…RASTERIZATION
Rasterisation (or rasterization) is the task of taking the information described in a vector graphics format OR the vertices of triangles making 3D shapes and converting them into a raster image (a series of pixels, dots or lines, which, when displayed together, create the image which was represented via shapes), or in other words “rasterizing” vectors or 3D models onto a 2D plane for display on a computer screen.For each triangle of a 3D shape, you project the corners of the triangle on the virtual screen with some math (projective geometry). Then you have the position of the 3 corners of the triangle on the pixel screen. Those 3 points have texture coordinates, so you know where in the texture are the 3 corners. The cost is proportional to the number of triangles, and is only a little bit affected by the screen resolution.
In computer graphics, a raster graphics or bitmap image is a dot matrix data structure that represents a generally rectangular grid of pixels (points of color), viewable via a monitor, paper, or other display medium.
With rasterization, objects on the screen are created from a mesh of virtual triangles, or polygons, that create 3D models of objects. A lot of information is associated with each vertex, including its position in space, as well as information about color, texture and its “normal,” which is used to determine the way the surface of an object is facing.
Computers then convert the triangles of the 3D models into pixels, or dots, on a 2D screen. Each pixel can be assigned an initial color value from the data stored in the triangle vertices.
Further pixel processing or “shading,” including changing pixel color based on how lights in the scene hit the pixel, and applying one or more textures to the pixel, combine to generate the final color applied to a pixel.
The main advantage of rasterization is its speed. However, rasterization is simply the process of computing the mapping from scene geometry to pixels and does not prescribe a particular way to compute the color of those pixels. So it cannot take shading, especially the physical light, into account and it cannot promise to get a photorealistic output. That’s a big limitation of rasterization.
There are also multiple problems:
If you have two triangles one is behind the other, you will draw twice all the pixels. you only keep the pixel from the triangle that is closer to you (Z-buffer), but you still do the work twice.
The borders of your triangles are jagged as it is hard to know if a pixel is in the triangle or out. You can do some smoothing on those, that is anti-aliasing.
You have to handle every triangles (including the ones behind you) and then see that they do not touch the screen at all. (we have techniques to mitigate this where we only look at triangles that are in the field of view)
Transparency is hard to handle (you can’t just do an average of the color of overlapping transparent triangles, you have to do it in the right order)



RAY CASTING
It is almost the exact reverse of rasterization: you start from the virtual screen instead of the vector or 3D shapes, and you project a ray, starting from each pixel of the screen, until it intersect with a triangle.The cost is directly correlated to the number of pixels in the screen and you need a really cheap way of finding the first triangle that intersect a ray. In the end, it is more expensive than rasterization but it will, by design, ignore the triangles that are out of the field of view.
You can use it to continue after the first triangle it hit, to take a little bit of the color of the next one, etc… This is useful to handle the border of the triangle cleanly (less jagged) and to handle transparency correctly.
RAYTRACING



Same idea as ray casting except once you hit a triangle you reflect on it and go into a different direction. The number of reflection you allow is the “depth” of your ray tracing. The color of the pixel can be calculated, based off the light source and all the polygons it had to reflect off of to get to that screen pixel.The easiest way to think of ray tracing is to look around you, right now. The objects you’re seeing are illuminated by beams of light. Now turn that around and follow the path of those beams backwards from your eye to the objects that light interacts with. That’s ray tracing.
Ray tracing is eye-oriented process that needs walking through each pixel looking for what object should be shown there, which is also can be described as a technique that follows a beam of light (in pixels) from a set point and simulates how it reacts when it encounters objects.
Compared with rasterization, ray tracing is hard to be implemented in real time, since even one ray can be traced and processed without much trouble, but after one ray bounces off an object, it can turn into 10 rays, and those 10 can turn into 100, 1000…The increase is exponential, and the the calculation for all these rays will be time consuming.
Historically, computer hardware hasn’t been fast enough to use these techniques in real time, such as in video games. Moviemakers can take as long as they like to render a single frame, so they do it offline in render farms. Video games have only a fraction of a second. As a result, most real-time graphics rely on the another technique called rasterization.

PATH TRACING
Path tracing can be used to solve more complex lighting situations.
Path tracing is a type of ray tracing. When using path tracing for rendering, the rays only produce a single ray per bounce. The rays do not follow a defined line per bounce (to a light, for example), but rather shoot off in a random direction. The path tracing algorithm then takes a random sampling of all of the rays to create the final image. This results in sampling a variety of different types of lighting.When a ray hits a surface it doesn’t trace a path to every light source, instead it bounces the ray off the surface and keeps bouncing it until it hits a light source or exhausts some bounce limit.
It then calculates the amount of light transferred all the way to the pixel, including any color information gathered from surfaces along the way.
It then averages out the values calculated from all the paths that were traced into the scene to get the final pixel color value.It requires a ton of computing power and if you don’t send out enough rays per pixel or don’t trace the paths far enough into the scene then you end up with a very spotty image as many pixels fail to find any light sources from their rays. So when you increase the the samples per pixel, you can see the image quality becomes better and better.
Ray tracing tends to be more efficient than path tracing. Basically, the render time of a ray tracer depends on the number of polygons in the scene. The more polygons you have, the longer it will take.
Meanwhile, the rendering time of a path tracer can be indifferent to the number of polygons, but it is related to light situation: If you add a light, transparency, translucence, or other shader effects, the path tracer will slow down considerably.
blogs.nvidia.com/blog/2018/03/19/whats-difference-between-ray-tracing-rasterization/
https://en.wikipedia.org/wiki/Rasterisation
https://www.quora.com/Whats-the-difference-between-ray-tracing-and-path-tracing
-
Debayer – A free command line tool to convert camera raw images into scene-linear exr
Read more: Debayer – A free command line tool to convert camera raw images into scene-linear exr
https://github.com/jedypod/debayer
The only required dependency is oiiotool. However other “debayer engines” are also supported.
- OpenImageIO – oiiotool is used for converting debayered tif images to exr.
- Debayer Engines
- RawTherapee – Powerful raw development software used to decode raw images. High quality, good selection of debayer algorithms, and more advanced raw processing like chromatic aberration removal.
- LibRaw – dcraw_emu commandline utility included with LibRaw. Optional alternative for debayer. Simple, fast and effective.
- Darktable – Uses darktable-cli plus an xmp config to process.
- vkdt – uses vkdt-cli to debayer. Pretty experimental still. Uses Vulkan for image processing. Stupidly fast. Pretty limited.
















COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Yann Lecun: Meta AI, Open Source, Limits of LLMs, AGI & the Future of AI | Lex Fridman Podcast #416
-
Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacy
-
Guide to Prompt Engineering
-
Animation/VFX/Game Industry JOB POSTINGS by Chris Mayne
-
Methods for creating motion blur in Stop motion
-
Blender VideoDepthAI – Turn any video into 3D Animated Scenes
-
ComfyUI FLOAT – A container for FLOAT Generative Motion Latent Flow Matching for Audio-driven Talking Portrait – lip sync
-
Matt Hallett – WAN 2.1 VACE Total Video Control in ComfyUI
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
