1. Watch every frame of raw footage twice. On the second time, take notes. If you don’t do this and try to start developing a scene premature, then it’s a big disservice to yourself and to the director, actors and production crew.
2. Nurture the relationships with the director. You are the secondary person in the relationship. Be calm and continually offer solutions. Get the main intention of the film as soon as possible from the director.
3. Organize your media so that you can find any shot instantly.
4. Factor in extra time for renders, exports, errors and crashes.
5. Attempt edits and ideas that shouldn’t work. It just might work. Until you do it and watch it, you won’t know. Don’t rule out ideas just because they don’t make sense in your mind.
6. Spend more time on your audio. It’s the glue of your edit. AUDIO SAVES EVERYTHING. Create fluid and seamless audio under your video.
7. Make cuts for the scene, but always in context for the whole film. Have a macro and a micro view at all times.
this is the epic story of a group of talented digital artists trying to overcame daily technical challenges to achieve incredibly photorealistic projects of monsters and aliens
Black-body radiation is the type of electromagnetic radiation within or surrounding a body in thermodynamic equilibrium with its environment, or emitted by a black body (an opaque and non-reflective body) held at constant, uniform temperature. The radiation has a specific spectrum and intensity that depends only on the temperature of the body.
A black-body at room temperature appears black, as most of the energy it radiates is infra-red and cannot be perceived by the human eye. At higher temperatures, black bodies glow with increasing intensity and colors that range from dull red to blindingly brilliant blue-white as the temperature increases.
In color technology, color depth also known as bit depth, is either the number of bits used to indicate the color of a single pixel, OR the number of bits used for each color component of a single pixel.
When referring to a pixel, the concept can be defined as bits per pixel (bpp).
When referring to a color component, the concept can be defined as bits per component, bits per channel, bits per color (all three abbreviated bpc), and also bits per pixel component, bits per color channel or bits per sample (bps). Modern standards tend to use bits per component, but historical lower-depth systems used bits per pixel more often.
Color depth is only one aspect of color representation, expressing the precision with which the amount of each primary can be expressed; the other aspect is how broad a range of colors can be expressed (the gamut). The definition of both color precision and gamut is accomplished with a color encoding specification which assigns a digital code value to a location in a color space.
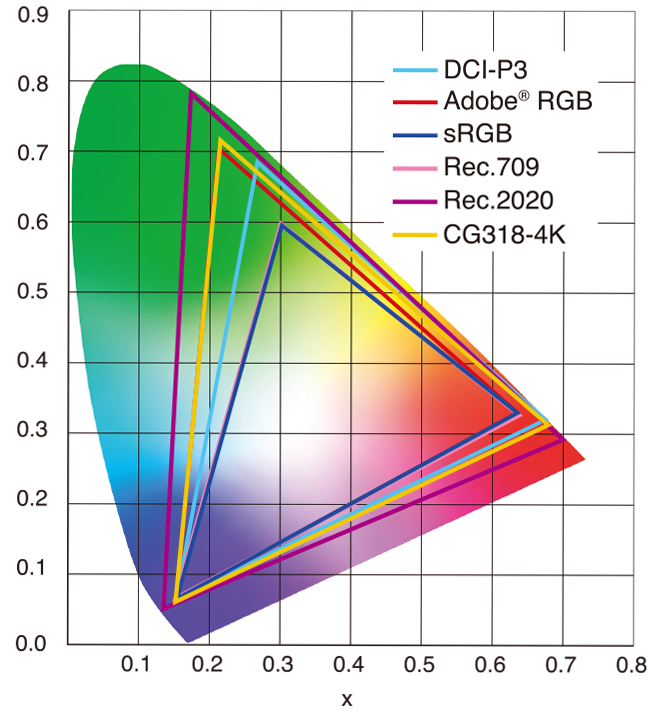
This page compares images rendered in Arnold using spectral rendering and different sets of colourspace primaries: Rec.709, Rec.2020, ACES and DCI-P3. The SPD data for the GretagMacbeth Color Checker are the measurements of Noburu Ohta, taken from Mansencal, Mauderer and Parsons (2014) colour-science.org.
“Memory colors are colors that are universally associated with specific objects, elements or scenes in our environment. They are the colors that we expect to see in specific situations: these colors are based on our expectation of how certain objects should look based on our past experiences and memories.
For instance, we associate specific hues, saturation and brightness values with human skintones and a slight variation can significantly affect the way we perceive a scene.
Similarly, we expect blue skies to have a particular hue, green trees to be a specific shade and so on.
Memory colors live inside of our brains and we often impose them onto what we see. By considering them during the grading process, the resulting image will be more visually appealing and won’t distract the viewer from the intended message of the story. Even a slight deviation from memory colors in a movie can create a sense of discordance, ultimately detracting from the viewer’s experience.”
sRGB: A standard “web”/computer-display RGB color space defined by IEC 61966-2-1. It’s used for most monitors, cameras, printers, and the vast majority of images on the Internet.
Rec. 709: An HD-video color space defined by ITU-R BT.709. It’s the go-to standard for HDTV broadcasts, Blu-ray discs, and professional video pipelines.
Why they exist
sRGB: Ensures consistent colors across different consumer devices (PCs, phones, webcams).
Rec. 709: Ensures consistent colors across video production and playback chains (cameras → editing → broadcast → TV).
What you’ll see
On your desktop or phone, images tagged sRGB will look “right” without extra tweaking.
On an HDTV or video-editing timeline, footage tagged Rec. 709 will display accurate contrast and hue on broadcast-grade monitors.
Physically-based shading means leaving behind phenomenological models, like the Phong shading model, which are simply built to “look good” subjectively without being based on physics in any real way, and moving to lighting and shading models that are derived from the laws of physics and/or from actual measurements of the real world, and rigorously obey physical constraints such as energy conservation.
For example, in many older rendering systems, shading models included separate controls for specular highlights from point lights and reflection of the environment via a cubemap. You could create a shader with the specular and the reflection set to wildly different values, even though those are both instances of the same physical process. In addition, you could set the specular to any arbitrary brightness, even if it would cause the surface to reflect more energy than it actually received.
In a physically-based system, both the point light specular and the environment reflection would be controlled by the same parameter, and the system would be set up to automatically adjust the brightness of both the specular and diffuse components to maintain overall energy conservation. Moreover you would want to set the specular brightness to a realistic value for the material you’re trying to simulate, based on measurements.
Physically-based lighting or shading includes physically-based BRDFs, which are usually based on microfacet theory, and physically correct light transport, which is based on the rendering equation (although heavily approximated in the case of real-time games).
It also includes the necessary changes in the art process to make use of these features. Switching to a physically-based system can cause some upsets for artists. First of all it requires full HDR lighting with a realistic level of brightness for light sources, the sky, etc. and this can take some getting used to for the lighting artists. It also requires texture/material artists to do some things differently (particularly for specular), and they can be frustrated by the apparent loss of control (e.g. locking together the specular highlight and environment reflection as mentioned above; artists will complain about this). They will need some time and guidance to adapt to the physically-based system.
On the plus side, once artists have adapted and gained trust in the physically-based system, they usually end up liking it better, because there are fewer parameters overall (less work for them to tweak). Also, materials created in one lighting environment generally look fine in other lighting environments too. This is unlike more ad-hoc models, where a set of material parameters might look good during daytime, but it comes out ridiculously glowy at night, or something like that.
Here are some resources to look at for physically-based lighting in games:
SIGGRAPH 2013 Physically Based Shading Course, particularly the background talk by Naty Hoffman at the beginning. You can also check out the previous incarnations of this course for more resources.
And of course, I would be remiss if I didn’t mention Physically-Based Rendering by Pharr and Humphreys, an amazing reference on this whole subject and well worth your time, although it focuses on offline rather than real-time rendering.
In general, when light interacts with matter, a complicated light-matter dynamic occurs. This interaction depends on the physical characteristics of the light as well as the physical composition and characteristics of the matter.
That is, some of the incident light is reflected, some of the light is transmitted, and another portion of the light is absorbed by the medium itself.
A BRDF describes how much light is reflected when light makes contact with a certain material. Similarly, a BTDF (Bi-directional Transmission Distribution Function) describes how much light is transmitted when light makes contact with a certain material
It is difficult to establish exactly how far one should go in elaborating the surface model. A truly complete representation of the reflective behavior of a surface might take into account such phenomena as polarization, scattering, fluorescence, and phosphorescence, all of which might vary with position on the surface. Therefore, the variables in this complete function would be:
incoming and outgoing angle incoming and outgoing wavelength incoming and outgoing polarization (both linear and circular) incoming and outgoing position (which might differ due to subsurface scattering) time delay between the incoming and outgoing light ray
import math,sys
def Exposure2Intensity(exposure):
exp = float(exposure)
result = math.pow(2,exp)
print(result)
Exposure2Intensity(0)
def Intensity2Exposure(intensity):
inarg = float(intensity)
if inarg == 0:
print("Exposure of zero intensity is undefined.")
return
if inarg < 1e-323:
inarg = max(inarg, 1e-323)
print("Exposure of negative intensities is undefined. Clamping to a very small value instead (1e-323)")
result = math.log(inarg, 2)
print(result)
Intensity2Exposure(0.1)
Why Exposure?
Exposure is a stop value that multiplies the intensity by 2 to the power of the stop. Increasing exposure by 1 results in double the amount of light.
Artists think in “stops.” Doubling or halving brightness is easy math and common in grading and look-dev. Exposure counts doublings in whole stops:
+1 stop = ×2 brightness
−1 stop = ×0.5 brightness
This gives perceptually even controls across both bright and dark values.
Why Intensity?
Intensity is linear. It’s what render engines and compositors expect when:
Summing values
Averaging pixels
Multiplying or filtering pixel data
Use intensity when you need the actual math on pixel/light data.
Formulas (from your Python)
Intensity from exposure: intensity = 2**exposure
Exposure from intensity: exposure = log₂(intensity)
Guardrails:
Intensity must be > 0 to compute exposure.
If intensity = 0 → exposure is undefined.
Clamp tiny values (e.g. 1e−323) before using log₂.
Use Exposure (stops) when…
You want artist-friendly sliders (−5…+5 stops)
Adjusting look-dev or grading in even stops
Matching plates with quick ±1 stop tweaks
Tweening brightness changes smoothly across ranges
Use Intensity (linear) when…
Storing raw pixel/light values
Multiplying textures or lights by a gain
Performing sums, averages, and filters
Feeding values to render engines expecting linear data
Examples
+2 stops → 2**2 = 4.0 (×4)
+1 stop → 2**1 = 2.0 (×2)
0 stop → 2**0 = 1.0 (×1)
−1 stop → 2**(−1) = 0.5 (×0.5)
−2 stops → 2**(−2) = 0.25 (×0.25)
Intensity 0.1 → exposure = log₂(0.1) ≈ −3.32
Rule of thumb
Think in stops (exposure) for controls and matching. Compute in linear (intensity) for rendering and math.
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.