


COMPOSITION
DESIGN
COLOR
-
HDR and Color
Read more: HDR and Colorhttps://www.soundandvision.com/content/nits-and-bits-hdr-and-color
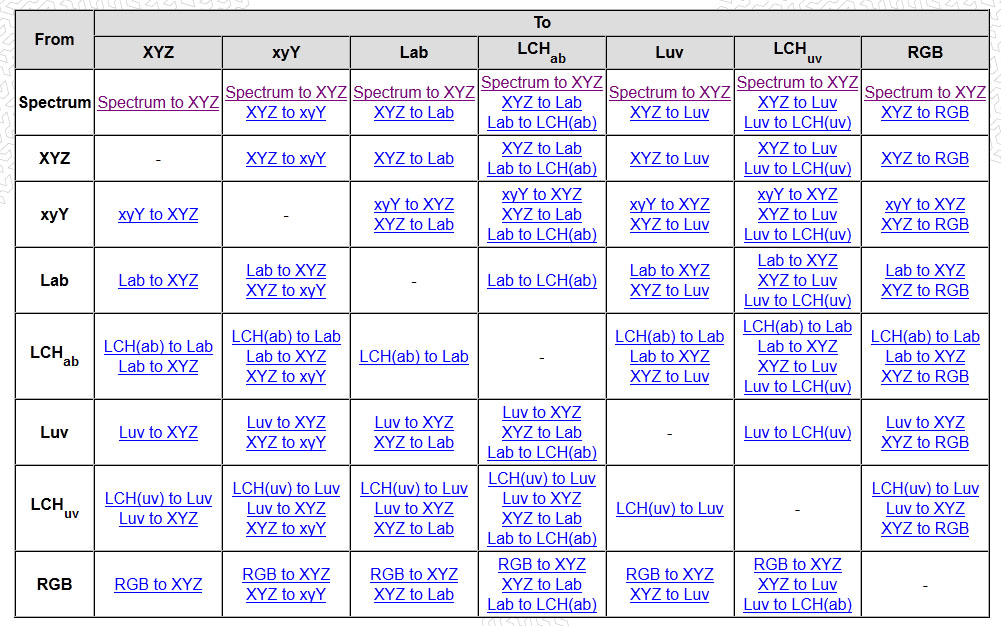
In HD we often refer to the range of available colors as a color gamut. Such a color gamut is typically plotted on a two-dimensional diagram, called a CIE chart, as shown in at the top of this blog. Each color is characterized by its x/y coordinates.

Good enough for government work, perhaps. But for HDR, with its higher luminance levels and wider color, the gamut becomes three-dimensional.

For HDR the color gamut therefore becomes a characteristic we now call the color volume. It isn’t easy to show color volume on a two-dimensional medium like the printed page or a computer screen, but one method is shown below. As the luminance becomes higher, the picture eventually turns to white. As it becomes darker, it fades to black. The traditional color gamut shown on the CIE chart is simply a slice through this color volume at a selected luminance level, such as 50%.
Three different color volumes—we still refer to them as color gamuts though their third dimension is important—are currently the most significant. The first is BT.709 (sometimes referred to as Rec.709), the color gamut used for pre-UHD/HDR formats, including standard HD.
The largest is known as BT.2020; it encompasses (roughly) the range of colors visible to the human eye (though ET might find it insufficient!).
Between these two is the color gamut used in digital cinema, known as DCI-P3.

sRGB

D65

-
Victor Perez – The Color Management Handbook for Visual Effects Artists
Read more: Victor Perez – The Color Management Handbook for Visual Effects ArtistsDigital Color Principles, Color Management Fundamentals & ACES Workflows













LIGHTING
-
Composition – 5 tips for creating perfect cinematic lighting and making your work look stunning
Read more: Composition – 5 tips for creating perfect cinematic lighting and making your work look stunning
http://www.diyphotography.net/5-tips-creating-perfect-cinematic-lighting-making-work-look-stunning/
1. Learn the rules of lighting
2. Learn when to break the rules
3. Make your key light larger
4. Reverse keying
5. Always be backlighting
-
Unity 3D resources
Read more: Unity 3D resources
http://answers.unity3d.com/questions/12321/how-can-i-start-learning-unity-fast-list-of-tutori.html
If you have no previous experience with Unity, start with these six video tutorials which give a quick overview of the Unity interface and some important features http://unity3d.com/support/documentation/video/
-
Romain Chauliac – LightIt a lighting script for Maya and Arnold
Read more: Romain Chauliac – LightIt a lighting script for Maya and ArnoldLightIt is a script for Maya and Arnold that will help you and improve your lighting workflow.
Thanks to preset studio lighting components (lights, backdrop…), high quality studio scenes and HDRI library manager.
https://www.artstation.com/artwork/393emJ
-
Photography basics: Color Temperature and White Balance
Read more: Photography basics: Color Temperature and White Balance

Color Temperature of a light source describes the spectrum of light which is radiated from a theoretical “blackbody” (an ideal physical body that absorbs all radiation and incident light – neither reflecting it nor allowing it to pass through) with a given surface temperature.
https://en.wikipedia.org/wiki/Color_temperature
Or. Most simply it is a method of describing the color characteristics of light through a numerical value that corresponds to the color emitted by a light source, measured in degrees of Kelvin (K) on a scale from 1,000 to 10,000.
More accurately. The color temperature of a light source is the temperature of an ideal backbody that radiates light of comparable hue to that of the light source.
(more…)










COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
