


COMPOSITION
DESIGN
-
The illusion of sex 2009
Read more: The illusion of sex 2009
Richard Russell Harvard University, USA
In the Illusion of Sex, two faces are perceived as male and female.
However, both faces are actually versions of the same androgynous face.
One face was created by increasing the contrast of the androgynous face, while the other face was created by decreasing the contrast. The face with more contrast is perceived as female, while the face with less contrast is perceived as male. The Illusion of Sex demonstrates that contrast is an important cue for perceiving the sex of a face, with greater contrast appearing feminine, and lesser contrast appearing masculine.
Russell, R. (2009) A sex difference in facial pigmentation and its exaggeration by cosmetics. Perception, (38)1211-1219.




















COLOR
-
Gamma correction
Read more: Gamma correction

http://www.normankoren.com/makingfineprints1A.html#Gammabox
https://en.wikipedia.org/wiki/Gamma_correction
http://www.photoscientia.co.uk/Gamma.htm
https://www.w3.org/Graphics/Color/sRGB.html
http://www.eizoglobal.com/library/basics/lcd_display_gamma/index.html
https://forum.reallusion.com/PrintTopic308094.aspx
Basically, gamma is the relationship between the brightness of a pixel as it appears on the screen, and the numerical value of that pixel. Generally Gamma is just about defining relationships.
Three main types:
– Image Gamma encoded in images
– Display Gammas encoded in hardware and/or viewing time
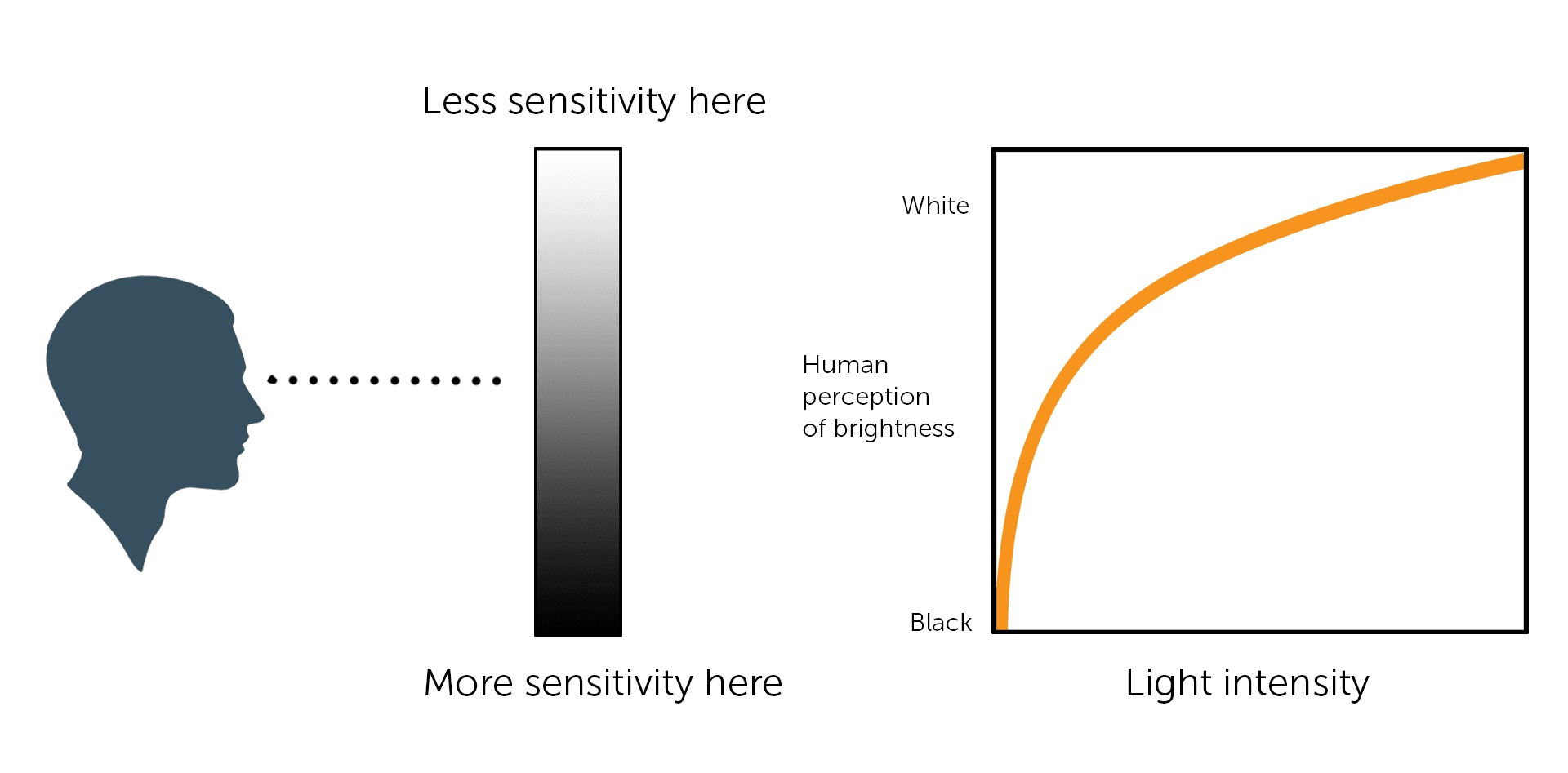
– System or Viewing Gamma which is the net effect of all gammas when you look back at a final image. In theory this should flatten back to 1.0 gamma.Our eyes, different camera or video recorder devices do not correctly capture luminance. (they are not linear)
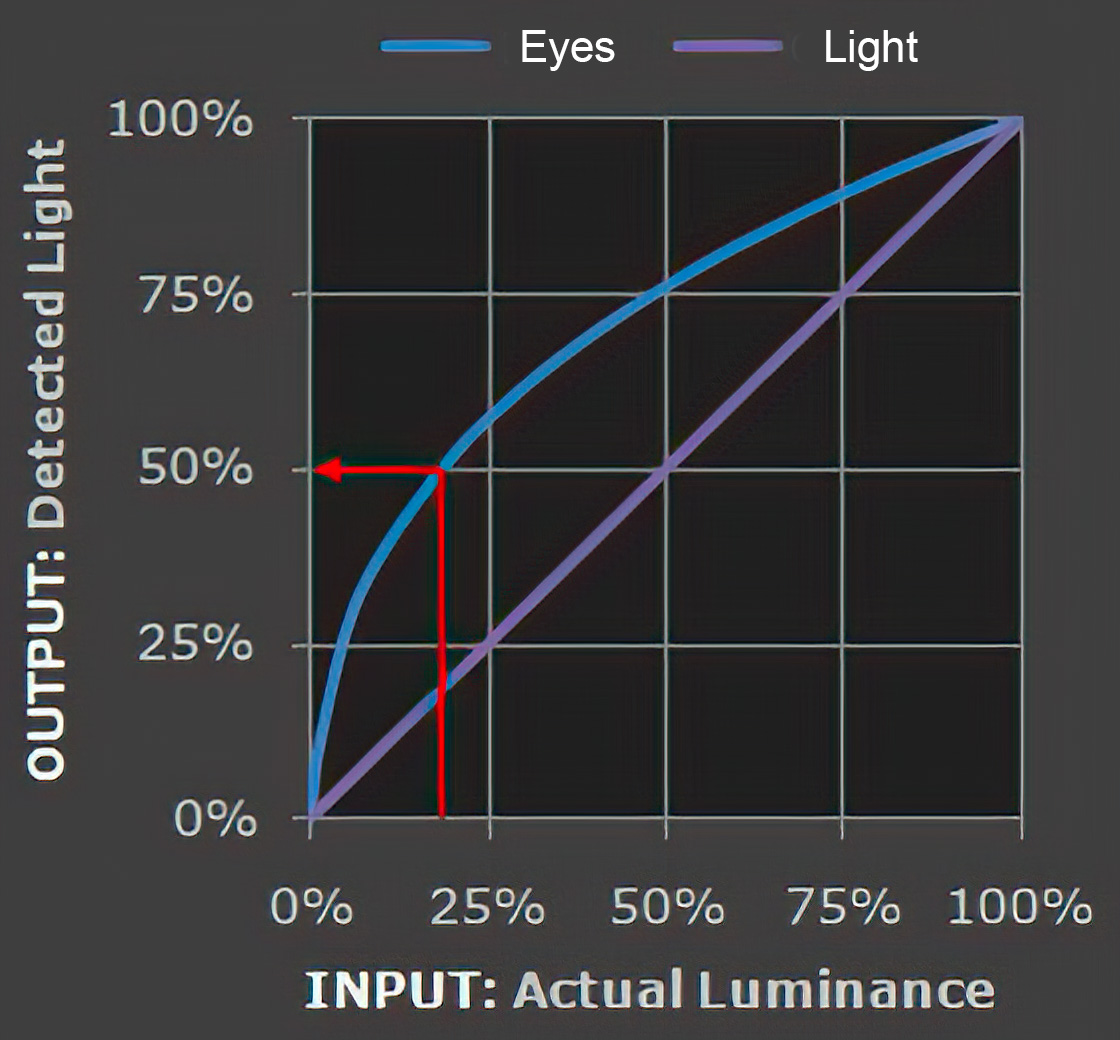
Different display devices (monitor, phone screen, TV) do not display luminance correctly neither. So, one needs to correct them, therefore the gamma correction function.The human perception of brightness, under common illumination conditions (not pitch black nor blindingly bright), follows an approximate power function (note: no relation to the gamma function), with greater sensitivity to relative differences between darker tones than between lighter ones, consistent with the Stevens’ power law for brightness perception. If images are not gamma-encoded, they allocate too many bits or too much bandwidth to highlights that humans cannot differentiate, and too few bits or too little bandwidth to shadow values that humans are sensitive to and would require more bits/bandwidth to maintain the same visual quality.
https://blog.amerlux.com/4-things-architects-should-know-about-lumens-vs-perceived-brightness/
cones manage color receptivity, rods determine how large our pupils should be. The larger (more dilated) our pupils are, the more light enters our eyes. In dark situations, our rods dilate our pupils so we can see better. This impacts how we perceive brightness.
https://www.cambridgeincolour.com/tutorials/gamma-correction.htm
A gamma encoded image has to have “gamma correction” applied when it is viewed — which effectively converts it back into light from the original scene. In other words, the purpose of gamma encoding is for recording the image — not for displaying the image. Fortunately this second step (the “display gamma”) is automatically performed by your monitor and video card. The following diagram illustrates how all of this fits together:
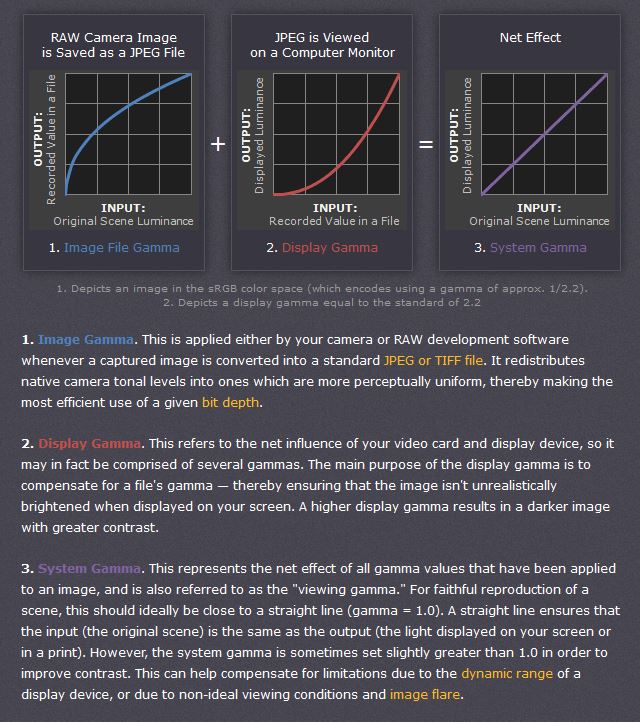
Display gamma
The display gamma can be a little confusing because this term is often used interchangeably with gamma correction, since it corrects for the file gamma. This is the gamma that you are controlling when you perform monitor calibration and adjust your contrast setting. Fortunately, the industry has converged on a standard display gamma of 2.2, so one doesn’t need to worry about the pros/cons of different values.Gamma encoding of images is used to optimize the usage of bits when encoding an image, or bandwidth used to transport an image, by taking advantage of the non-linear manner in which humans perceive light and color. Human response to luminance is also biased. Especially sensible to dark areas.
Thus, the human visual system has a non-linear response to the power of the incoming light, so a fixed increase in power will not have a fixed increase in perceived brightness.
We perceive a value as half bright when it is actually 18% of the original intensity not 50%. As such, our perception is not linear.You probably already know that a pixel can have any ‘value’ of Red, Green, and Blue between 0 and 255, and you would therefore think that a pixel value of 127 would appear as half of the maximum possible brightness, and that a value of 64 would represent one-quarter brightness, and so on. Well, that’s just not the case.
Pixar Color Management
https://renderman.pixar.com/color-management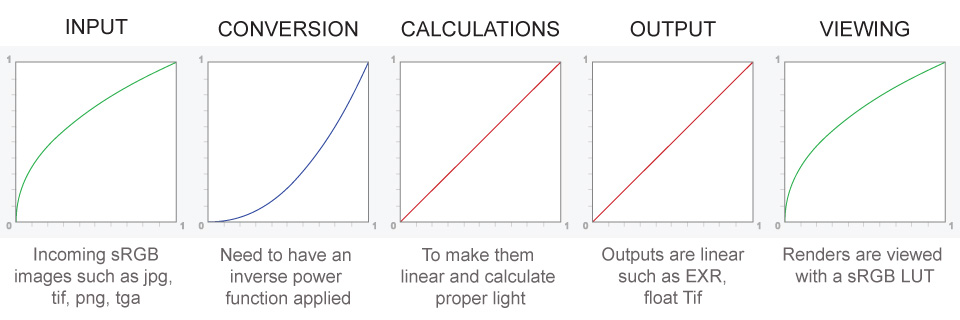
– Why do we need linear gamma?
Because light works linearly and therefore only works properly when it lights linear values.– Why do we need to view in sRGB?
Because the resulting linear image in not suitable for viewing, but contains all the proper data. Pixar’s IT viewer can compensate by showing the rendered image through a sRGB look up table (LUT), which is identical to what will be the final image after the sRGB gamma curve is applied in post.This would be simple enough if every software would play by the same rules, but they don’t. In fact, the default gamma workflow for many 3D software is incorrect. This is where the knowledge of a proper imaging workflow comes in to save the day.
Cathode-ray tubes have a peculiar relationship between the voltage applied to them, and the amount of light emitted. It isn’t linear, and in fact it follows what’s called by mathematicians and other geeks, a ‘power law’ (a number raised to a power). The numerical value of that power is what we call the gamma of the monitor or system.
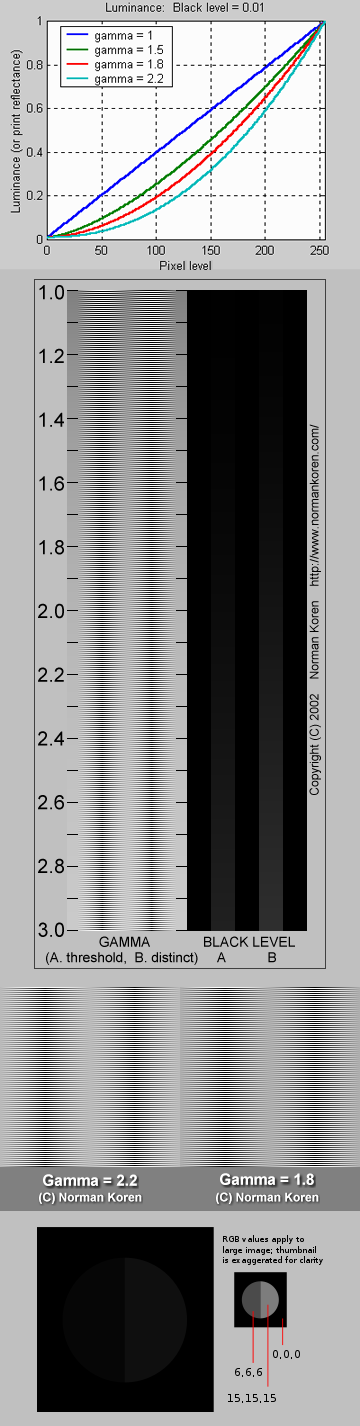
Thus. Gamma describes the nonlinear relationship between the pixel levels in your computer and the luminance of your monitor (the light energy it emits) or the reflectance of your prints. The equation is,
Luminance = C * value^gamma + black level
– C is set by the monitor Contrast control.
– Value is the pixel level normalized to a maximum of 1. For an 8 bit monitor with pixel levels 0 – 255, value = (pixel level)/255.
– Black level is set by the (misnamed) monitor Brightness control. The relationship is linear if gamma = 1. The chart illustrates the relationship for gamma = 1, 1.5, 1.8 and 2.2 with C = 1 and black level = 0.
Gamma affects middle tones; it has no effect on black or white. If gamma is set too high, middle tones appear too dark. Conversely, if it’s set too low, middle tones appear too light.
The native gamma of monitors– the relationship between grid voltage and luminance– is typically around 2.5, though it can vary considerably. This is well above any of the display standards, so you must be aware of gamma and correct it.
A display gamma of 2.2 is the de facto standard for the Windows operating system and the Internet-standard sRGB color space.
The old standard for Mcintosh and prepress file interchange is 1.8. It is now 2.2 as well.
Video cameras have gammas of approximately 0.45– the inverse of 2.2. The viewing or system gamma is the product of the gammas of all the devices in the system– the image acquisition device (film+scanner or digital camera), color lookup table (LUT), and monitor. System gamma is typically between 1.1 and 1.5. Viewing flare and other factor make images look flat at system gamma = 1.0.
Most laptop LCD screens are poorly suited for critical image editing because gamma is extremely sensitive to viewing angle.
More about screens
https://www.cambridgeincolour.com/tutorials/gamma-correction.htm
CRT Monitors. Due to an odd bit of engineering luck, the native gamma of a CRT is 2.5 — almost the inverse of our eyes. Values from a gamma-encoded file could therefore be sent straight to the screen and they would automatically be corrected and appear nearly OK. However, a small gamma correction of ~1/1.1 needs to be applied to achieve an overall display gamma of 2.2. This is usually already set by the manufacturer’s default settings, but can also be set during monitor calibration.
LCD Monitors. LCD monitors weren’t so fortunate; ensuring an overall display gamma of 2.2 often requires substantial corrections, and they are also much less consistent than CRT’s. LCDs therefore require something called a look-up table (LUT) in order to ensure that input values are depicted using the intended display gamma (amongst other things). See the tutorial on monitor calibration: look-up tables for more on this topic.
About black level (brightness). Your monitor’s brightness control (which should actually be called black level) can be adjusted using the mostly black pattern on the right side of the chart. This pattern contains two dark gray vertical bars, A and B, which increase in luminance with increasing gamma. (If you can’t see them, your black level is way low.) The left bar (A) should be just above the threshold of visibility opposite your chosen gamma (2.2 or 1.8)– it should be invisible where gamma is lower by about 0.3. The right bar (B) should be distinctly visible: brighter than (A), but still very dark. This chart is only for monitors; it doesn’t work on printed media.
The 1.8 and 2.2 gray patterns at the bottom of the image represent a test of monitor quality and calibration. If your monitor is functioning properly and calibrated to gamma = 2.2 or 1.8, the corresponding pattern will appear smooth neutral gray when viewed from a distance. Any waviness, irregularity, or color banding indicates incorrect monitor calibration or poor performance.
Another test to see whether one’s computer monitor is properly hardware adjusted and can display shadow detail in sRGB images properly, they should see the left half of the circle in the large black square very faintly but the right half should be clearly visible. If not, one can adjust their monitor’s contrast and/or brightness setting. This alters the monitor’s perceived gamma. The image is best viewed against a black background.
This procedure is not suitable for calibrating or print-proofing a monitor. It can be useful for making a monitor display sRGB images approximately correctly, on systems in which profiles are not used (for example, the Firefox browser prior to version 3.0 and many others) or in systems that assume untagged source images are in the sRGB colorspace.
On some operating systems running the X Window System, one can set the gamma correction factor (applied to the existing gamma value) by issuing the command xgamma -gamma 0.9 for setting gamma correction factor to 0.9, and xgamma for querying current value of that factor (the default is 1.0). In OS X systems, the gamma and other related screen calibrations are made through the System Preference
https://www.kinematicsoup.com/news/2016/6/15/gamma-and-linear-space-what-they-are-how-they-differ
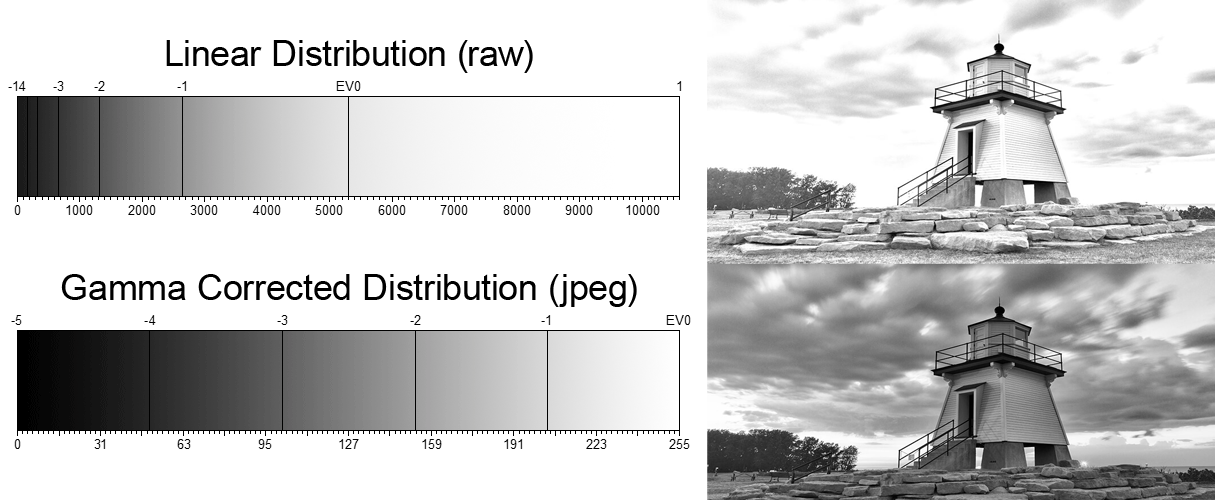
Linear color space means that numerical intensity values correspond proportionally to their perceived intensity. This means that the colors can be added and multiplied correctly. A color space without that property is called ”non-linear”. Below is an example where an intensity value is doubled in a linear and a non-linear color space. While the corresponding numerical values in linear space are correct, in the non-linear space (gamma = 0.45, more on this later) we can’t simply double the value to get the correct intensity.
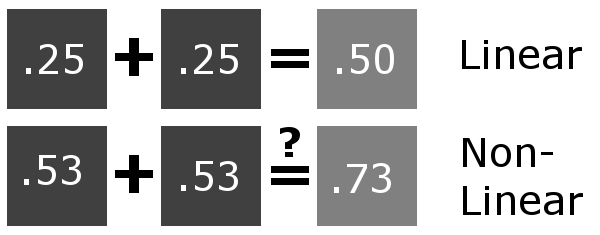
The need for gamma arises for two main reasons: The first is that screens have been built with a non-linear response to intensity. The other is that the human eye can tell the difference between darker shades better than lighter shades. This means that when images are compressed to save space, we want to have greater accuracy for dark intensities at the expense of lighter intensities. Both of these problems are resolved using gamma correction, which is to say the intensity of every pixel in an image is put through a power function. Specifically, gamma is the name given to the power applied to the image.
CRT screens, simply by how they work, apply a gamma of around 2.2, and modern LCD screens are designed to mimic that behavior. A gamma of 2.2, the reciprocal of 0.45, when applied to the brightened images will darken them, leaving the original image.
-
Paul Debevec, Chloe LeGendre, Lukas Lepicovsky – Jointly Optimizing Color Rendition and In-Camera Backgrounds in an RGB Virtual Production Stage
Read more: Paul Debevec, Chloe LeGendre, Lukas Lepicovsky – Jointly Optimizing Color Rendition and In-Camera Backgrounds in an RGB Virtual Production Stagehttps://arxiv.org/pdf/2205.12403.pdf
RGB LEDs vs RGBWP (RGB + lime + phospor converted amber) LEDs
Local copy:
-
Is a MacBeth Colour Rendition Chart the Safest Way to Calibrate a Camera?
Read more: Is a MacBeth Colour Rendition Chart the Safest Way to Calibrate a Camera?www.colour-science.org/posts/the-colorchecker-considered-mostly-harmless/
“Unless you have all the relevant spectral measurements, a colour rendition chart should not be used to perform colour-correction of camera imagery but only for white balancing and relative exposure adjustments.”
“Using a colour rendition chart for colour-correction might dramatically increase error if the scene light source spectrum is different from the illuminant used to compute the colour rendition chart’s reference values.”
“other factors make using a colour rendition chart unsuitable for camera calibration:
– Uncontrolled geometry of the colour rendition chart with the incident illumination and the camera.
– Unknown sample reflectances and ageing as the colour of the samples vary with time.
– Low samples count.
– Camera noise and flare.
– Etc…“Those issues are well understood in the VFX industry, and when receiving plates, we almost exclusively use colour rendition charts to white balance and perform relative exposure adjustments, i.e. plate neutralisation.”
-
Björn Ottosson – OKHSV and OKHSL – Two new color spaces for color picking
Read more: Björn Ottosson – OKHSV and OKHSL – Two new color spaces for color pickinghttps://bottosson.github.io/misc/colorpicker
https://bottosson.github.io/posts/colorpicker/
https://www.smashingmagazine.com/2024/10/interview-bjorn-ottosson-creator-oklab-color-space/
One problem with sRGB is that in a gradient between blue and white, it becomes a bit purple in the middle of the transition. That’s because sRGB really isn’t created to mimic how the eye sees colors; rather, it is based on how CRT monitors work. That means it works with certain frequencies of red, green, and blue, and also the non-linear coding called gamma. It’s a miracle it works as well as it does, but it’s not connected to color perception. When using those tools, you sometimes get surprising results, like purple in the gradient.

There were also attempts to create simple models matching human perception based on XYZ, but as it turned out, it’s not possible to model all color vision that way. Perception of color is incredibly complex and depends, among other things, on whether it is dark or light in the room and the background color it is against. When you look at a photograph, it also depends on what you think the color of the light source is. The dress is a typical example of color vision being very context-dependent. It is almost impossible to model this perfectly.
I based Oklab on two other color spaces, CIECAM16 and IPT. I used the lightness and saturation prediction from CIECAM16, which is a color appearance model, as a target. I actually wanted to use the datasets used to create CIECAM16, but I couldn’t find them.
IPT was designed to have better hue uniformity. In experiments, they asked people to match light and dark colors, saturated and unsaturated colors, which resulted in a dataset for which colors, subjectively, have the same hue. IPT has a few other issues but is the basis for hue in Oklab.
In the Munsell color system, colors are described with three parameters, designed to match the perceived appearance of colors: Hue, Chroma and Value. The parameters are designed to be independent and each have a uniform scale. This results in a color solid with an irregular shape. The parameters are designed to be independent and each have a uniform scale. This results in a color solid with an irregular shape. Modern color spaces and models, such as CIELAB, Cam16 and Björn Ottosson own Oklab, are very similar in their construction.

By far the most used color spaces today for color picking are HSL and HSV, two representations introduced in the classic 1978 paper “Color Spaces for Computer Graphics”. HSL and HSV designed to roughly correlate with perceptual color properties while being very simple and cheap to compute.
Today HSL and HSV are most commonly used together with the sRGB color space.

One of the main advantages of HSL and HSV over the different Lab color spaces is that they map the sRGB gamut to a cylinder. This makes them easy to use since all parameters can be changed independently, without the risk of creating colors outside of the target gamut.

The main drawback on the other hand is that their properties don’t match human perception particularly well.
Reconciling these conflicting goals perfectly isn’t possible, but given that HSV and HSL don’t use anything derived from experiments relating to human perception, creating something that makes a better tradeoff does not seem unreasonable.
With this new lightness estimate, we are ready to look into the construction of Okhsv and Okhsl.


-
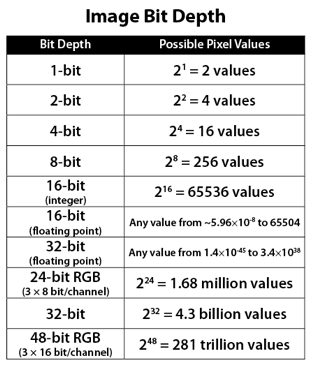
Image rendering bit depth
Read more: Image rendering bit depthThe terms 8-bit, 16-bit, 16-bit float, and 32-bit refer to different data formats used to store and represent image information, as bits per pixel.
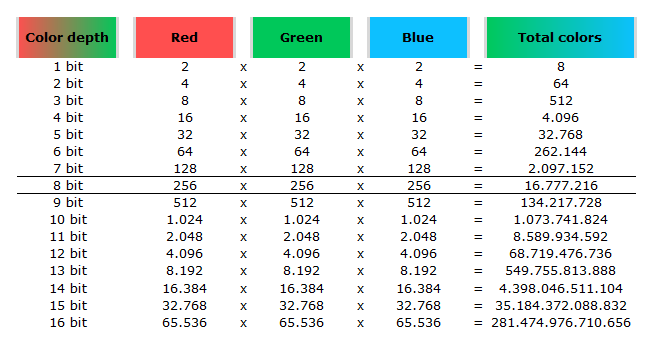
https://en.wikipedia.org/wiki/Color_depth
In color technology, color depth also known as bit depth, is either the number of bits used to indicate the color of a single pixel, OR the number of bits used for each color component of a single pixel.
When referring to a pixel, the concept can be defined as bits per pixel (bpp).
When referring to a color component, the concept can be defined as bits per component, bits per channel, bits per color (all three abbreviated bpc), and also bits per pixel component, bits per color channel or bits per sample (bps). Modern standards tend to use bits per component, but historical lower-depth systems used bits per pixel more often.
Color depth is only one aspect of color representation, expressing the precision with which the amount of each primary can be expressed; the other aspect is how broad a range of colors can be expressed (the gamut). The definition of both color precision and gamut is accomplished with a color encoding specification which assigns a digital code value to a location in a color space.

Here’s a simple explanation of each.
8-bit images (i.e. 24 bits per pixel for a color image) are considered Low Dynamic Range.
They can store around 5 stops of light and each pixel carry a value from 0 (black) to 255 (white).
As a comparison, DSLR cameras can capture ~12-15 stops of light and they use RAW files to store the information.16-bit: This format is commonly referred to as “half-precision.” It uses 16 bits of data to represent color values for each pixel. With 16 bits, you can have 65,536 discrete levels of color, allowing for relatively high precision and smooth gradients. However, it has a limited dynamic range, meaning it cannot accurately represent extremely bright or dark values. It is commonly used for regular images and textures.
16-bit float: This format is an extension of the 16-bit format but uses floating-point numbers instead of fixed integers. Floating-point numbers allow for more precise calculations and a larger dynamic range. In this case, the 16 bits are used to store both the color value and the exponent, which controls the range of values that can be represented. The 16-bit float format provides better accuracy and a wider dynamic range than regular 16-bit, making it useful for high-dynamic-range imaging (HDRI) and computations that require more precision.
32-bit: (i.e. 96 bits per pixel for a color image) are considered High Dynamic Range. This format, also known as “full-precision” or “float,” uses 32 bits to represent color values and offers the highest precision and dynamic range among the three options. With 32 bits, you have a significantly larger number of discrete levels, allowing for extremely accurate color representation, smooth gradients, and a wide range of brightness values. It is commonly used for professional rendering, visual effects, and scientific applications where maximum precision is required.
Bits and HDR coverage
High Dynamic Range (HDR) images are designed to capture a wide range of luminance values, from the darkest shadows to the brightest highlights, in order to reproduce a scene with more accuracy and detail. The bit depth of an image refers to the number of bits used to represent each pixel’s color information. When comparing 32-bit float and 16-bit float HDR images, the drop in accuracy primarily relates to the precision of the color information.
A 32-bit float HDR image offers a higher level of precision compared to a 16-bit float HDR image. In a 32-bit float format, each color channel (red, green, and blue) is represented by 32 bits, allowing for a larger range of values to be stored. This increased precision enables the image to retain more details and subtleties in color and luminance.
On the other hand, a 16-bit float HDR image utilizes 16 bits per color channel, resulting in a reduced range of values that can be represented. This lower precision leads to a loss of fine details and color nuances, especially in highly contrasted areas of the image where there are significant differences in luminance.
The drop in accuracy between 32-bit and 16-bit float HDR images becomes more noticeable as the exposure range of the scene increases. Exposure range refers to the span between the darkest and brightest areas of an image. In scenes with a limited exposure range, where the luminance differences are relatively small, the loss of accuracy may not be as prominent or perceptible. These images usually are around 8-10 exposure levels.
However, in scenes with a wide exposure range, such as a landscape with deep shadows and bright highlights, the reduced precision of a 16-bit float HDR image can result in visible artifacts like color banding, posterization, and loss of detail in both shadows and highlights. The image may exhibit abrupt transitions between tones or colors, which can appear unnatural and less realistic.
To provide a rough estimate, it is often observed that exposure values beyond approximately ±6 to ±8 stops from the middle gray (18% reflectance) may be more prone to accuracy issues in a 16-bit float format. This range may vary depending on the specific implementation and encoding scheme used.
To summarize, the drop in accuracy between 32-bit and 16-bit float HDR images is mainly related to the reduced precision of color information. This decrease in precision becomes more apparent in scenes with a wide exposure range, affecting the representation of fine details and leading to visible artifacts in the image.
In practice, this means that exposure values beyond a certain range will experience a loss of accuracy and detail when stored in a 16-bit float format. The exact range at which this loss occurs depends on the encoding scheme and the specific implementation. However, in general, extremely bright or extremely dark values that fall outside the representable range may be subject to quantization errors, resulting in loss of detail, banding, or other artifacts.
HDRs used for lighting purposes are usually slightly convolved to improve on sampling speed and removing specular artefacts. To that extent, 16 bit float HDRIs tend to me most used in CG cycles.

-
Light and Matter : The 2018 theory of Physically-Based Rendering and Shading by Allegorithmic
Read more: Light and Matter : The 2018 theory of Physically-Based Rendering and Shading by Allegorithmicacademy.substance3d.com/courses/the-pbr-guide-part-1
academy.substance3d.com/courses/the-pbr-guide-part-2

 Local copy:
Local copy:













LIGHTING
-
What’s the Difference Between Ray Casting, Ray Tracing, Path Tracing and Rasterization? Physical light tracing…
Read more: What’s the Difference Between Ray Casting, Ray Tracing, Path Tracing and Rasterization? Physical light tracing…RASTERIZATION
Rasterisation (or rasterization) is the task of taking the information described in a vector graphics format OR the vertices of triangles making 3D shapes and converting them into a raster image (a series of pixels, dots or lines, which, when displayed together, create the image which was represented via shapes), or in other words “rasterizing” vectors or 3D models onto a 2D plane for display on a computer screen.For each triangle of a 3D shape, you project the corners of the triangle on the virtual screen with some math (projective geometry). Then you have the position of the 3 corners of the triangle on the pixel screen. Those 3 points have texture coordinates, so you know where in the texture are the 3 corners. The cost is proportional to the number of triangles, and is only a little bit affected by the screen resolution.
In computer graphics, a raster graphics or bitmap image is a dot matrix data structure that represents a generally rectangular grid of pixels (points of color), viewable via a monitor, paper, or other display medium.
With rasterization, objects on the screen are created from a mesh of virtual triangles, or polygons, that create 3D models of objects. A lot of information is associated with each vertex, including its position in space, as well as information about color, texture and its “normal,” which is used to determine the way the surface of an object is facing.
Computers then convert the triangles of the 3D models into pixels, or dots, on a 2D screen. Each pixel can be assigned an initial color value from the data stored in the triangle vertices.
Further pixel processing or “shading,” including changing pixel color based on how lights in the scene hit the pixel, and applying one or more textures to the pixel, combine to generate the final color applied to a pixel.
The main advantage of rasterization is its speed. However, rasterization is simply the process of computing the mapping from scene geometry to pixels and does not prescribe a particular way to compute the color of those pixels. So it cannot take shading, especially the physical light, into account and it cannot promise to get a photorealistic output. That’s a big limitation of rasterization.
There are also multiple problems:
If you have two triangles one is behind the other, you will draw twice all the pixels. you only keep the pixel from the triangle that is closer to you (Z-buffer), but you still do the work twice.
The borders of your triangles are jagged as it is hard to know if a pixel is in the triangle or out. You can do some smoothing on those, that is anti-aliasing.
You have to handle every triangles (including the ones behind you) and then see that they do not touch the screen at all. (we have techniques to mitigate this where we only look at triangles that are in the field of view)
Transparency is hard to handle (you can’t just do an average of the color of overlapping transparent triangles, you have to do it in the right order)



RAY CASTING
It is almost the exact reverse of rasterization: you start from the virtual screen instead of the vector or 3D shapes, and you project a ray, starting from each pixel of the screen, until it intersect with a triangle.The cost is directly correlated to the number of pixels in the screen and you need a really cheap way of finding the first triangle that intersect a ray. In the end, it is more expensive than rasterization but it will, by design, ignore the triangles that are out of the field of view.
You can use it to continue after the first triangle it hit, to take a little bit of the color of the next one, etc… This is useful to handle the border of the triangle cleanly (less jagged) and to handle transparency correctly.
RAYTRACING



Same idea as ray casting except once you hit a triangle you reflect on it and go into a different direction. The number of reflection you allow is the “depth” of your ray tracing. The color of the pixel can be calculated, based off the light source and all the polygons it had to reflect off of to get to that screen pixel.The easiest way to think of ray tracing is to look around you, right now. The objects you’re seeing are illuminated by beams of light. Now turn that around and follow the path of those beams backwards from your eye to the objects that light interacts with. That’s ray tracing.
Ray tracing is eye-oriented process that needs walking through each pixel looking for what object should be shown there, which is also can be described as a technique that follows a beam of light (in pixels) from a set point and simulates how it reacts when it encounters objects.
Compared with rasterization, ray tracing is hard to be implemented in real time, since even one ray can be traced and processed without much trouble, but after one ray bounces off an object, it can turn into 10 rays, and those 10 can turn into 100, 1000…The increase is exponential, and the the calculation for all these rays will be time consuming.
Historically, computer hardware hasn’t been fast enough to use these techniques in real time, such as in video games. Moviemakers can take as long as they like to render a single frame, so they do it offline in render farms. Video games have only a fraction of a second. As a result, most real-time graphics rely on the another technique called rasterization.

PATH TRACING
Path tracing can be used to solve more complex lighting situations.
Path tracing is a type of ray tracing. When using path tracing for rendering, the rays only produce a single ray per bounce. The rays do not follow a defined line per bounce (to a light, for example), but rather shoot off in a random direction. The path tracing algorithm then takes a random sampling of all of the rays to create the final image. This results in sampling a variety of different types of lighting.When a ray hits a surface it doesn’t trace a path to every light source, instead it bounces the ray off the surface and keeps bouncing it until it hits a light source or exhausts some bounce limit.
It then calculates the amount of light transferred all the way to the pixel, including any color information gathered from surfaces along the way.
It then averages out the values calculated from all the paths that were traced into the scene to get the final pixel color value.It requires a ton of computing power and if you don’t send out enough rays per pixel or don’t trace the paths far enough into the scene then you end up with a very spotty image as many pixels fail to find any light sources from their rays. So when you increase the the samples per pixel, you can see the image quality becomes better and better.
Ray tracing tends to be more efficient than path tracing. Basically, the render time of a ray tracer depends on the number of polygons in the scene. The more polygons you have, the longer it will take.
Meanwhile, the rendering time of a path tracer can be indifferent to the number of polygons, but it is related to light situation: If you add a light, transparency, translucence, or other shader effects, the path tracer will slow down considerably.
blogs.nvidia.com/blog/2018/03/19/whats-difference-between-ray-tracing-rasterization/
https://en.wikipedia.org/wiki/Rasterisation
https://www.quora.com/Whats-the-difference-between-ray-tracing-and-path-tracing
-
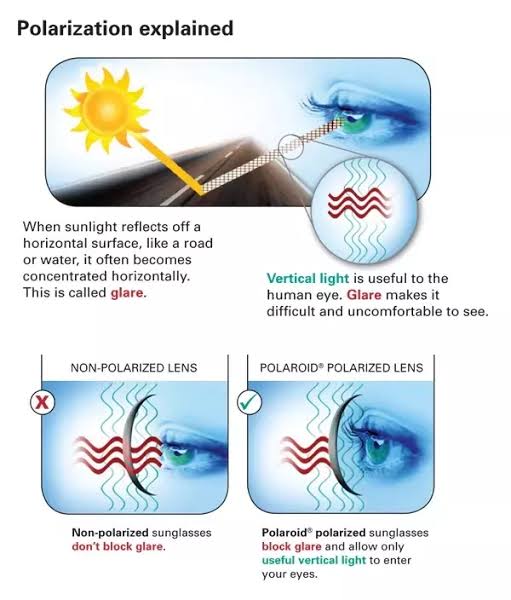
Polarised vs unpolarized filtering
Read more: Polarised vs unpolarized filteringA light wave that is vibrating in more than one plane is referred to as unpolarized light. …
Polarized light waves are light waves in which the vibrations occur in a single plane. The process of transforming unpolarized light into polarized light is known as polarization.

en.wikipedia.org/wiki/Polarizing_filter_(photography)
The most common use of polarized technology is to reduce lighting complexity on the subject.
Details such as glare and hard edges are not removed, but greatly reduced.This method is usually used in VFX to capture raw images with the least amount of specular diffusion or pollution, thus allowing artists to infer detail back through typical shading and rendering techniques and on demand.
Light reflected from a non-metallic surface becomes polarized; this effect is maximum at Brewster’s angle, about 56° from the vertical for common glass.
A polarizer rotated to pass only light polarized in the direction perpendicular to the reflected light will absorb much of it. This absorption allows glare reflected from, for example, a body of water or a road to be reduced. Reflections from shiny surfaces (e.g. vegetation, sweaty skin, water surfaces, glass) are also reduced. This allows the natural color and detail of what is beneath to come through. Reflections from a window into a dark interior can be much reduced, allowing it to be seen through. (The same effects are available for vision by using polarizing sunglasses.)

www.physicsclassroom.com/class/light/u12l1e.cfm
Some of the light coming from the sky is polarized (bees use this phenomenon for navigation). The electrons in the air molecules cause a scattering of sunlight in all directions. This explains why the sky is not dark during the day. But when looked at from the sides, the light emitted from a specific electron is totally polarized.[3] Hence, a picture taken in a direction at 90 degrees from the sun can take advantage of this polarization.

Use of a polarizing filter, in the correct direction, will filter out the polarized component of skylight, darkening the sky; the landscape below it, and clouds, will be less affected, giving a photograph with a darker and more dramatic sky, and emphasizing the clouds.

There are two types of polarizing filters readily available, linear and “circular”, which have exactly the same effect photographically. But the metering and auto-focus sensors in certain cameras, including virtually all auto-focus SLRs, will not work properly with linear polarizers because the beam splitters used to split off the light for focusing and metering are polarization-dependent.
Polarizing filters reduce the light passed through to the film or sensor by about one to three stops (2–8×) depending on how much of the light is polarized at the filter angle selected. Auto-exposure cameras will adjust for this by widening the aperture, lengthening the time the shutter is open, and/or increasing the ASA/ISO speed of the camera.
www.adorama.com/alc/nd-filter-vs-polarizer-what%25e2%2580%2599s-the-difference
Neutral Density (ND) filters help control image exposure by reducing the light that enters the camera so that you can have more control of your depth of field and shutter speed. Polarizers or polarizing filters work in a similar way, but the difference is that they selectively let light waves of a certain polarization pass through. This effect helps create more vivid colors in an image, as well as manage glare and reflections from water surfaces. Both are regarded as some of the best filters for landscape and travel photography as they reduce the dynamic range in high-contrast images, thus enabling photographers to capture more realistic and dramatic sceneries.
shopfelixgray.com/blog/polarized-vs-non-polarized-sunglasses/
www.eyebuydirect.com/blog/difference-polarized-nonpolarized-sunglasses/
-
Light and Matter : The 2018 theory of Physically-Based Rendering and Shading by Allegorithmic
Read more: Light and Matter : The 2018 theory of Physically-Based Rendering and Shading by Allegorithmicacademy.substance3d.com/courses/the-pbr-guide-part-1
academy.substance3d.com/courses/the-pbr-guide-part-2
Local copy:
-
Vahan Sosoyan MakeHDR – an OpenFX open source plug-in for merging multiple LDR images into a single HDRI
Read more: Vahan Sosoyan MakeHDR – an OpenFX open source plug-in for merging multiple LDR images into a single HDRIhttps://github.com/Sosoyan/make-hdr
Feature notes
- Merge up to 16 inputs with 8, 10 or 12 bit depth processing
- User friendly logarithmic Tone Mapping controls within the tool
- Advanced controls such as Sampling rate and Smoothness
Available at cross platform on Linux, MacOS and Windows Works consistent in compositing applications like Nuke, Fusion, Natron.
NOTE: The goal is to clean the initial individual brackets before or at merging time as much as possible.
This means:- keeping original shooting metadata
- de-fringing
- removing aberration (through camera lens data or automatically)
- at 32 bit
- in ACEScg (or ACES) wherever possible














COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
