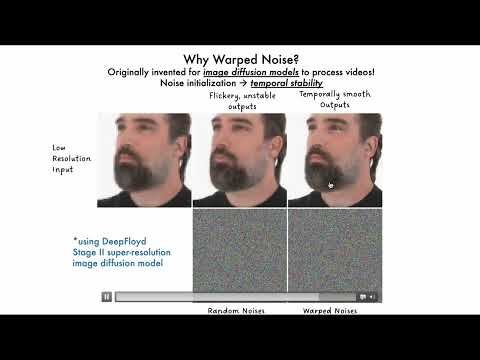
Given an input video and a simple user-provided text instruction describing the desired content, our method synthesizes dynamic objects or complex scene effects that naturally interact with the existing scene over time. The position, appearance, and motion of the new content are seamlessly integrated into the original footage while accounting for camera motion, occlusions, and interactions with other dynamic objects in the scene, resulting in a cohesive and realistic output video.
They propose an end-to-end multimodality-conditioned human video generation framework named OmniHuman, which can generate human videos based on a single human image and motion signals (e.g., audio only, video only, or a combination of audio and video). In OmniHuman, we introduce a multimodality motion conditioning mixed training strategy, allowing the model to benefit from data scaling up of mixed conditioning. This overcomes the issue that previous end-to-end approaches faced due to the scarcity of high-quality data. OmniHuman significantly outperforms existing methods, generating extremely realistic human videos based on weak signal inputs, especially audio. It supports image inputs of any aspect ratio, whether they are portraits, half-body, or full-body images, delivering more lifelike and high-quality results across various scenarios.
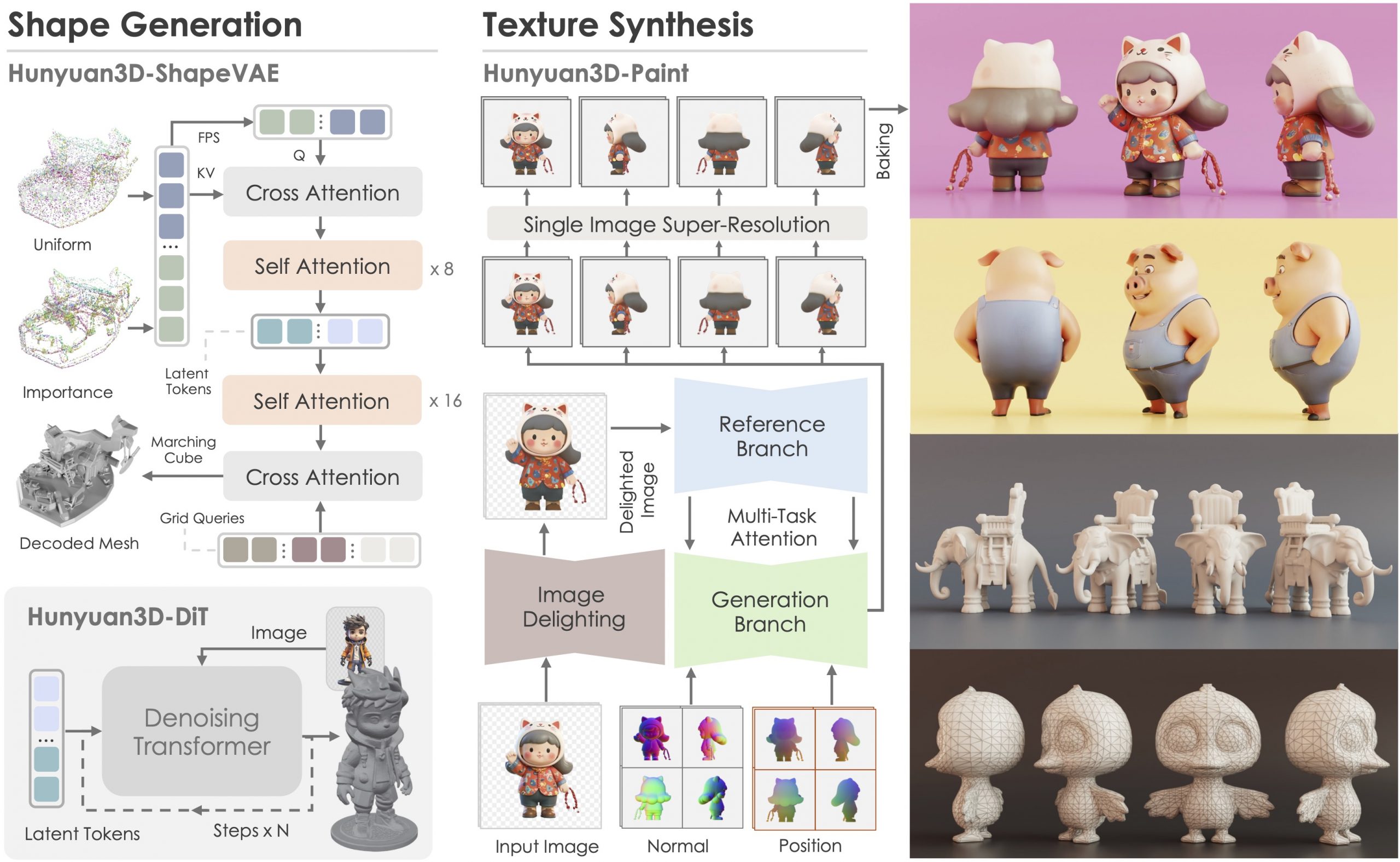
Hunyuan3D 2.0, an advanced large-scale 3D synthesis system for generating high-resolution textured 3D assets. This system includes two foundation components: a large-scale shape generation model – Hunyuan3D-DiT, and a large-scale texture synthesis model – Hunyuan3D-Paint.
The shape generative model, built on a scalable flow-based diffusion transformer, aims to create geometry that properly aligns with a given condition image, laying a solid foundation for downstream applications. The texture synthesis model, benefiting from strong geometric and diffusion priors, produces high-resolution and vibrant texture maps for either generated or hand-crafted meshes. Furthermore, we build Hunyuan3D-Studio – a versatile, user-friendly production platform that simplifies the re-creation process of 3D assets.
It allows both professional and amateur users to manipulate or even animate their meshes efficiently. We systematically evaluate our models, showing that Hunyuan3D 2.0 outperforms previous state-of-the-art models, including the open-source models and closed-source models in geometry details, condition alignment, texture quality, and e.t.c.
Invoke is a powerful, secure, and easy-to-deploy generative AI platform for professional studios to create visual media. Train models on your intellectual property, control every aspect of the production process, and maintain complete ownership of your data, in perpetuity.
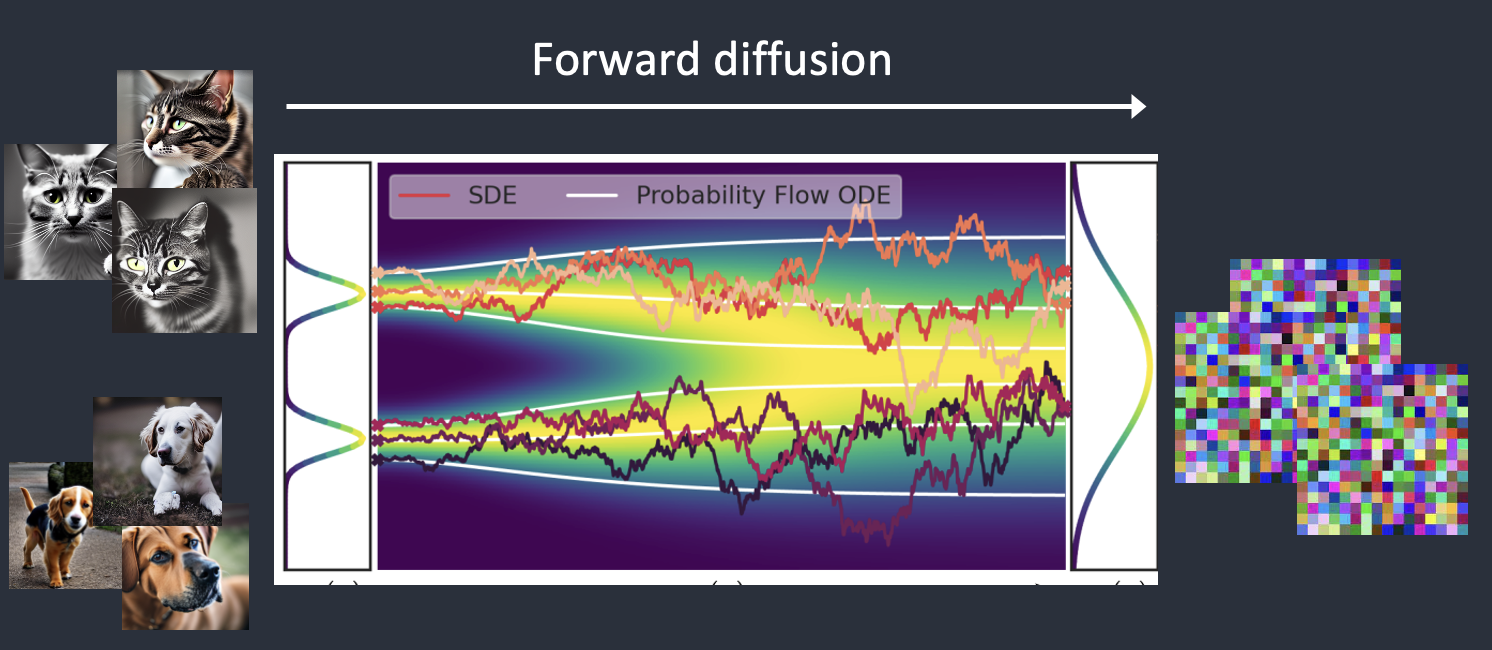
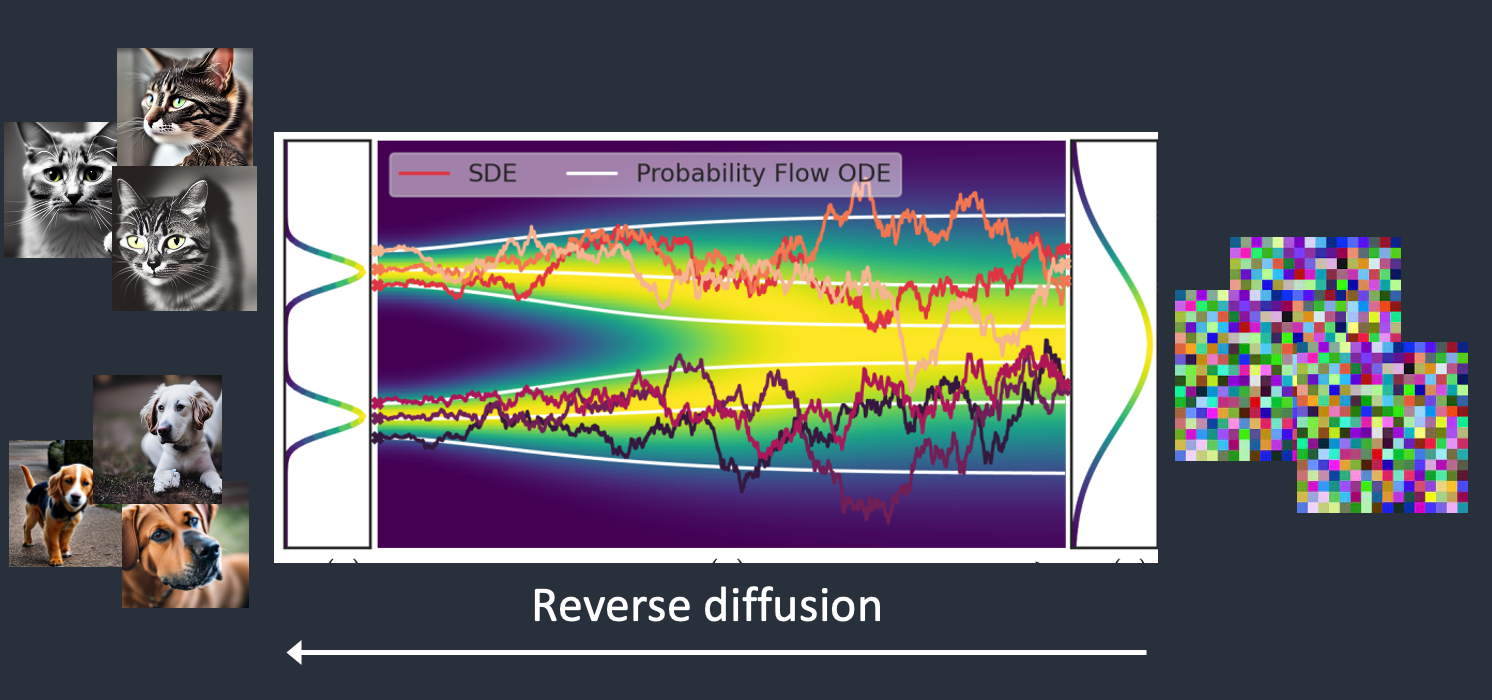
Stable Diffusion is a latent diffusion model that generates AI images from text. Instead of operating in the high-dimensional image space, it first compresses the image into the latent space.
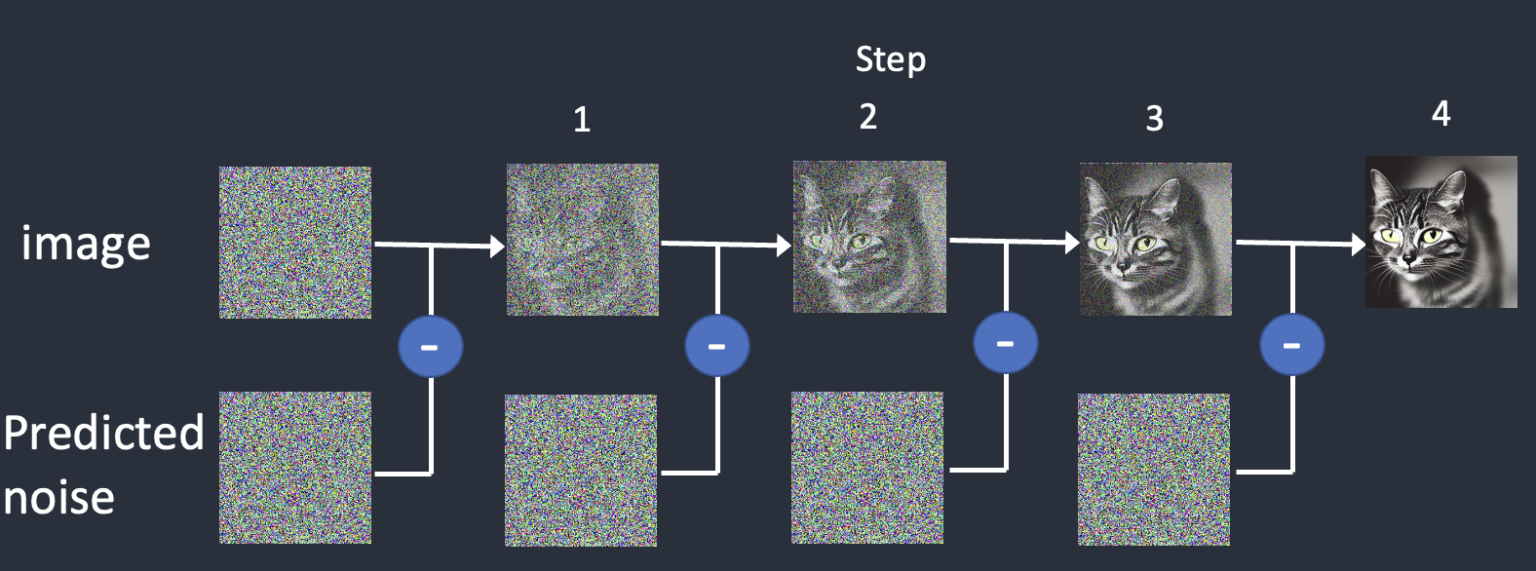
Stable Diffusion belongs to a class of deep learning models called diffusion models. They are generative models, meaning they are designed to generate new data similar to what they have seen in training. In the case of Stable Diffusion, the data are images.
Why is it called the diffusion model? Because its math looks very much like diffusion in physics. Let’s go through the idea.
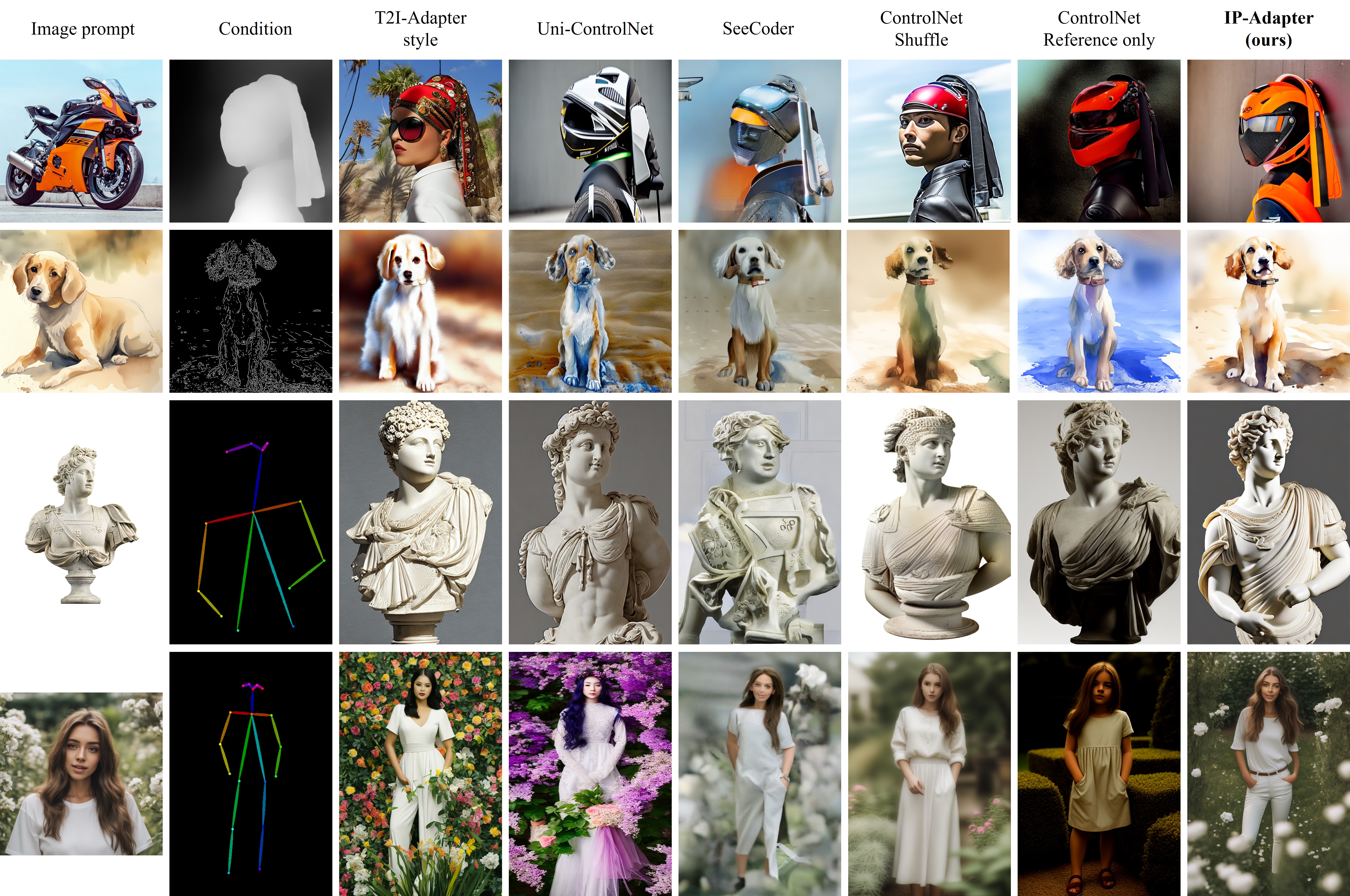
The IPAdapter are very powerful models for image-to-image conditioning. The subject or even just the style of the reference image(s) can be easily transferred to a generation. Think of it as a 1-image lora. They are an effective and lightweight adapter to achieve image prompt capability for the pre-trained text-to-image diffusion models. An IP-Adapter with only 22M parameters can achieve comparable or even better performance to a fine-tuned image prompt model.
Once the IP-Adapter is trained, it can be directly reusable on custom models fine-tuned from the same base model.
The IP-Adapter is fully compatible with existing controllable tools, e.g., ControlNet and T2I-Adapter.
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.