


-
Hashem Alghaili’s Kira Vale – A Short AI Film on Human Cloning
https://www.instagram.com/reel/DL5klF-x6O8
My new AI-assisted short film is here. Kira explores human cloning and the search for identity in today’s world.
It took nearly 600 prompts, 12 days (during my free time), and a $500 budget to bring this project to life. The entire film was created by one person using a range of AI tools, all listed at the end.
Enjoy.
~ Hashem
-
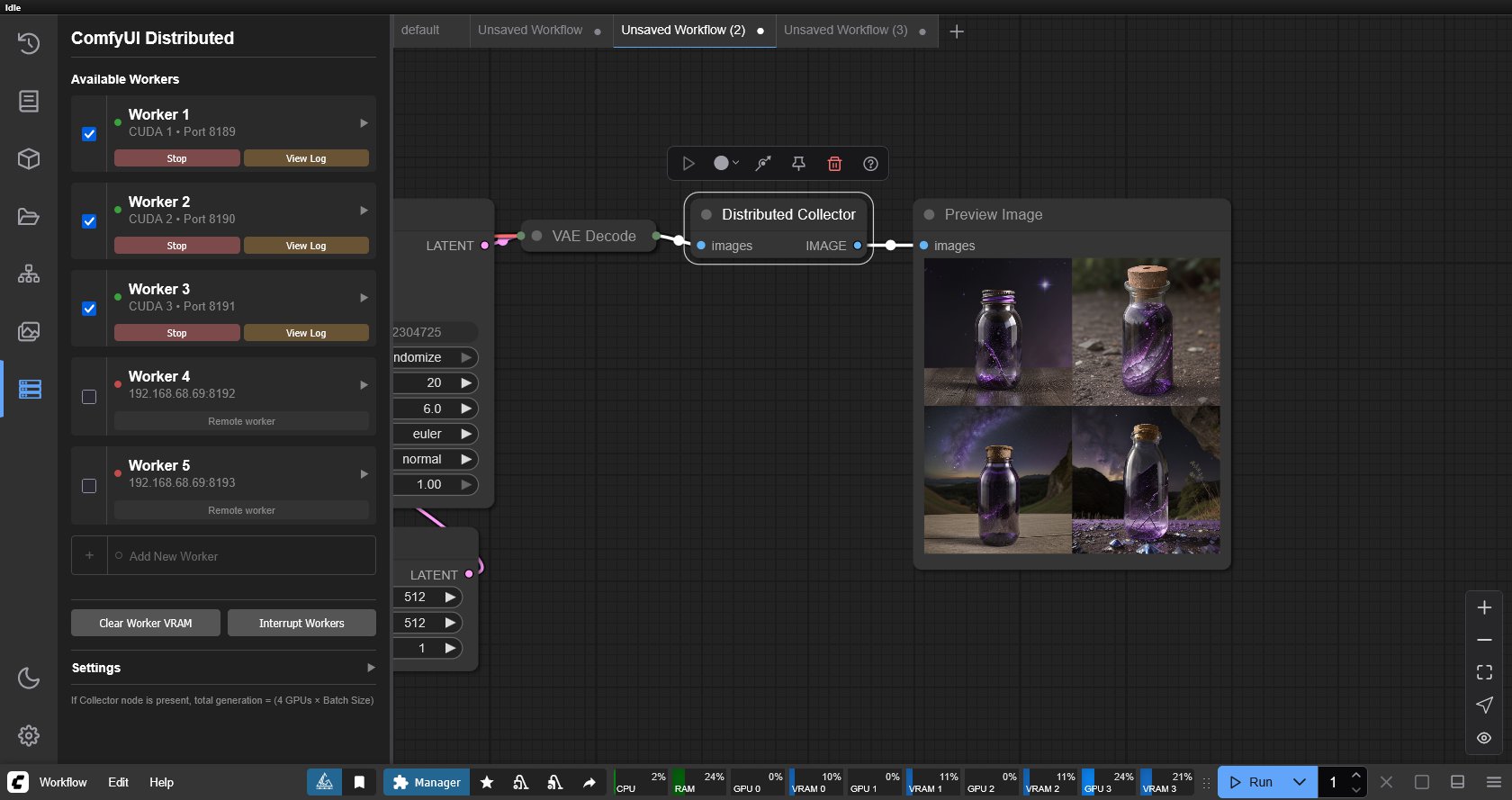
ComfyUI-Distributed – Parallel and distributed processing across multiple GPUs and machines
https://github.com/robertvoy/ComfyUI-Distributed
Key FeaturesParallel Workflow Processing
- Parallel Generation – Run the same workflow on multiple GPUs simultaneously with different seeds
- Automatic Load Balancing – Distribute workflow execution across available workers
- Batch Acceleration – Generate multiple variations faster by using all your GPUs
Distributed Upscaling- True Distributed Processing – Split large upscaling tasks into tiles processed across multiple GPUs
- Tile-based Upscaling – Intelligent work distribution for Ultimate SD Upscale
Management & Monitoring- Automatic Worker Management – Launch and monitor workers from the UI
- Network Support – Use GPUs across different machines on your network
- Real-time Monitoring – Track worker status and performance from the UI
- Easy Configuration – JSON-based configuration with UI controls
- Memory Management – Built-in VRAM clearing









COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
STOP FCC – SAVE THE FREE NET
-
Photography basics: Shutter angle and shutter speed and motion blur
-
Photography basics: Color Temperature and White Balance
-
Ethan Roffler interviews CG Supervisor Daniele Tosti
-
Cinematographers Blueprint 300dpi poster
-
Matt Gray – How to generate a profitable business
-
Matt Hallett – WAN 2.1 VACE Total Video Control in ComfyUI
-
Google – Artificial Intelligence free courses
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
