The settlement amounts to about $3,000 per book and is believed to be the largest ever recovery in a U.S. copyright case, according to the plaintiffs’ attorneys.
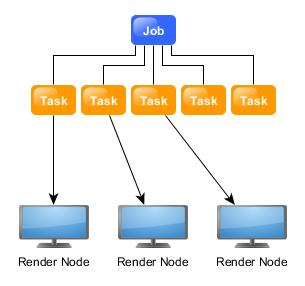
Deadline 10 is a cross-platform render farm management tool for Windows, Linux, and macOS. It gives users control of their rendering resources and can be used on-premises, in the cloud, or both. It handles asset syncing to the cloud, manages data transfers, and supports tagging for cost tracking purposes.
Deadline 10’s Remote Connection Server allows for communication over HTTPS, improving performance and scalability. Where supported, users can use usage-based licensing to supplement their existing fixed pool of software licenses when rendering through Deadline 10.
Log in with your Gmail and select Gemini 2.5 (Nano Banana).
Upload a photo — either from your laptop or a Google Street View screenshot.
Paste this example prompt: “Use the provided architectural photo as reference. Generate a high-fidelity 3D building model in the look of a 3D-printed architecture model.”
Wait a few seconds, and your 3D architecture model will be ready.
Pro tip: If you want more accuracy, upload two images — a street photo for the facade and an aerial view for the roof/top.
Blender is switching from OpenGL to Vulkan as its default graphics backend, starting significantly with Blender 4.5, to achieve better performance and prepare for future features like real-time ray tracing and global illumination. To enable this switch, go to Edit > Preferences > System and set the “Backend” option to “Vulkan,” then restart Blender. This change offers substantial benefits, including faster startup times, improved viewport responsiveness, and more efficient handling of complex scenes by better utilizing your CPU and GPU resources.
Why the Switch to Vulkan?
Modern Graphics API: Vulkan is a newer, lower-level, and more efficient API that provides developers with greater control over hardware, unlike the older, higher-level OpenGL.
Performance Boost: This change significantly improves performance in various areas, such as viewport rendering, material loading, and overall UI responsiveness, especially in complex scenes with many textures.
Better Resource Utilization: Vulkan distributes work more effectively across the CPU and reduces driver overhead, allowing Blender to make better use of your computer’s power.
Future-Proofing: The Vulkan backend paves the way for advanced features like real-time ray tracing and global illumination in future versions of Blender.
Given sparse-view videos, Diffuman4D (1) generates 4D-consistent multi-view videos conditioned on these inputs, and (2) reconstructs a high-fidelity 4DGS model of the human performance using both the input and the generated videos.
Truly Infinite Videos This isn’t a gimmick. You can generate incredibly long videos without frying your VRAM. Perfect for podcasts, presentations, or full-on virtual influencers.
More Than Just Lips This is the best part. It doesn’t just sync the mouth; it generates realistic head movements, body posture, and facial expressions that match the audio’s emotion. It makes characters feel alive.
Keeps Everything Consistent It preserves the character’s identity, the background, and even camera movements from your original video, so everything looks seamless.
Completely Open Source & Ready for Business The code, the weights, and the paper are all out there for you to use. Best of all, it’s released under an Apache 2.0 license, which means you are free to use what you create for commercial projects!
You’ve been in the VFX Industry for over a decade. Tell us about your journey.
It all started with my older brother giving me a Commodore64 personal computer as a gift back in the late 80′. I realised then I could create something directly from my imagination using this new digital media format. And, eventually, make a living in the process. That led me to start my professional career in 1990. From live TV to games to animation. All the way to live action VFX in the recent years.
I really never stopped to crave to create art since those early days. And I have been incredibly fortunate to work with really great talent along the way, which made my journey so much more effective.
What inspired you to pursue VFX as a career?
An incredible combination of opportunities, really. The opportunity to express myself as an artist and earn money in the process. The opportunity to learn about how the world around us works and how best solve problems. The opportunity to share my time with other talented people with similar passions. The opportunity to grow and adapt to new challenges. The opportunity to develop something that was never done before. A perfect storm of creativity that fed my continuous curiosity about life and genuinely drove my inspiration.
Tell us about the projects you’ve particularly enjoyed working on in your career
Colour is an open-source Python package providing a comprehensive number of algorithms and datasets for colour science. It is freely available under the BSD-3-Clause terms.