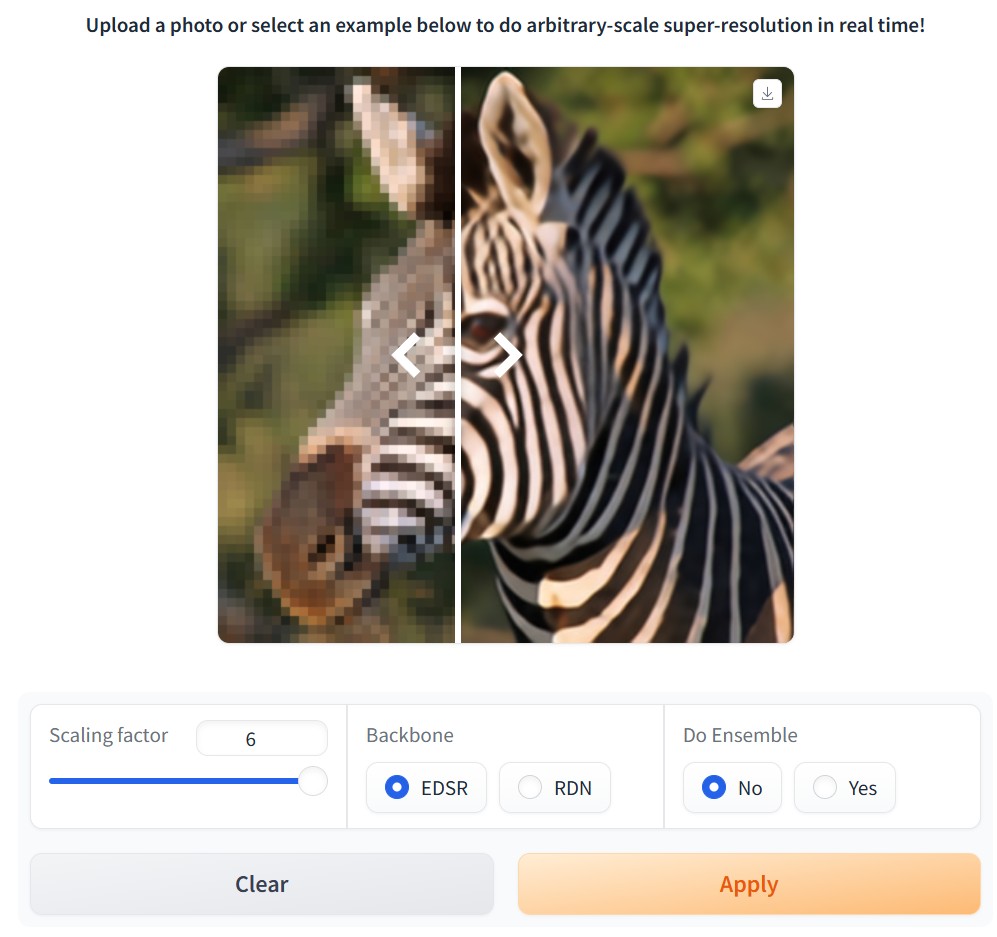
https://github.com/DachunKai/Ev-DeblurVSR
https://arxiv.org/pdf/2504.13042




3Dprinting (178) A.I. (846) animation (350) blender (210) colour (233) commercials (52) composition (153) cool (364) design (649) Featured (80) hardware (314) IOS (109) jokes (139) lighting (289) modeling (145) music (186) photogrammetry (192) photography (755) production (1291) python (94) quotes (497) reference (314) software (1356) trailers (307) ves (555) VR (221)
https://github.com/tencent/Hunyuan3D-2
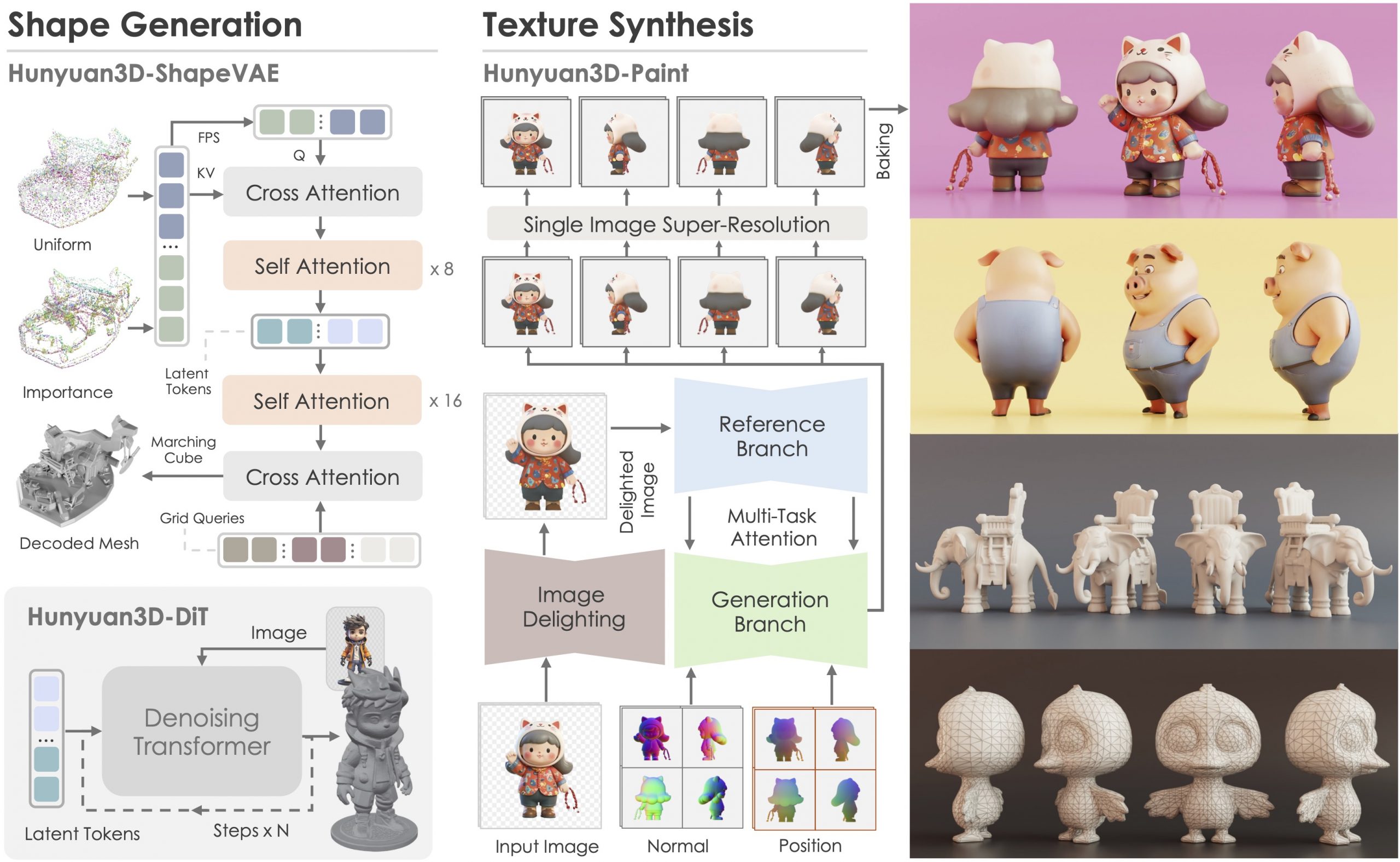

Hunyuan3D 2.0, an advanced large-scale 3D synthesis system for generating high-resolution textured 3D assets. This system includes two foundation components: a large-scale shape generation model – Hunyuan3D-DiT, and a large-scale texture synthesis model – Hunyuan3D-Paint.
The shape generative model, built on a scalable flow-based diffusion transformer, aims to create geometry that properly aligns with a given condition image, laying a solid foundation for downstream applications. The texture synthesis model, benefiting from strong geometric and diffusion priors, produces high-resolution and vibrant texture maps for either generated or hand-crafted meshes. Furthermore, we build Hunyuan3D-Studio – a versatile, user-friendly production platform that simplifies the re-creation process of 3D assets.
It allows both professional and amateur users to manipulate or even animate their meshes efficiently. We systematically evaluate our models, showing that Hunyuan3D 2.0 outperforms previous state-of-the-art models, including the open-source models and closed-source models in geometry details, condition alignment, texture quality, and e.t.c.
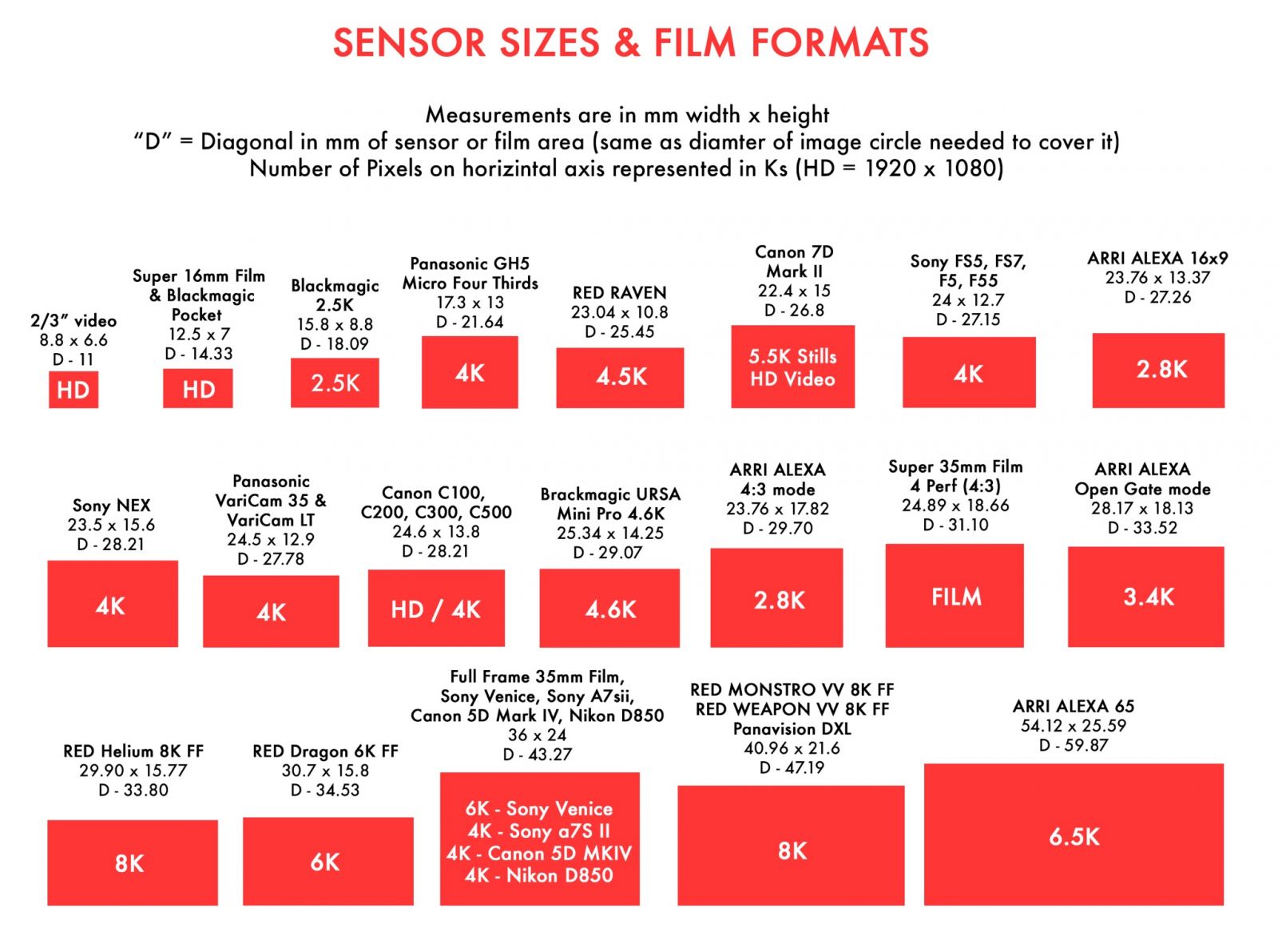
Based on the new Blackmagic URSA Cine platform, the new Blackmagic URSA Cine Immersive model features a fixed, custom lens system with a sensor that features 8160 x 7200 resolution per eye with pixel level synchronization. It has an extremely wide 16 stops of dynamic range, and shoots at 90 fps stereoscopic into a Blackmagic RAW Immersive file. The new Blackmagic RAW Immersive file format is an enhanced version of Blackmagic RAW that’s been designed to make immersive video simple to use through the post production workflow.





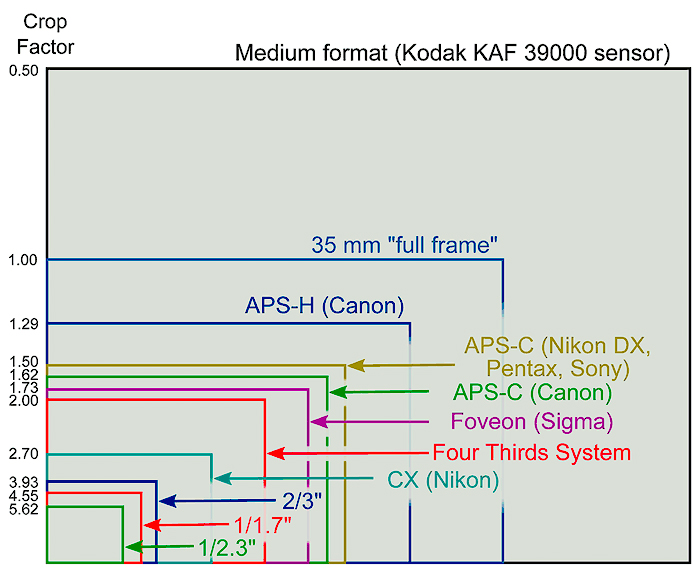
| Resolution – Aspect Ratio | 4:03 | 16:09 | 16:10 | 3:02 | 5:03 | 5:04 |
| CGA | 320 x 200 | |||||
| QVGA | 320 x 240 | |||||
| VGA (SD, Standard Definition) | 640 x 480 | |||||
| NTSC | 720 x 480 | |||||
| WVGA | 854 x 450 | |||||
| WVGA | 800 x 480 | |||||
| PAL | 768 x 576 | |||||
| SVGA | 800 x 600 | |||||
| XGA | 1024 x 768 | |||||
| not named | 1152 x 768 | |||||
| HD 720 (720P, High Definition) | 1280 x 720 | |||||
| WXGA | 1280 x 800 | |||||
| WXGA | 1280 x 768 | |||||
| SXGA | 1280 x 1024 | |||||
| not named (768P, HD, High Definition) | 1366 x 768 | |||||
| not named | 1440 x 960 | |||||
| SXGA+ | 1400 x 1050 | |||||
| WSXGA | 1680 x 1050 | |||||
| UXGA (2MP) | 1600 x 1200 | |||||
| HD1080 (1080P, Full HD) | 1920 x 1080 | |||||
| WUXGA | 1920 x 1200 | |||||
| 2K | 2048 x (any) | |||||
| QWXGA | 2048 x 1152 | |||||
| QXGA (3MP) | 2048 x 1536 | |||||
| WQXGA | 2560 x 1600 | |||||
| QHD (Quad HD) | 2560 x 1440 | |||||
| QSXGA (5MP) | 2560 x 2048 | |||||
| 4K UHD (4K, Ultra HD, Ultra-High Definition) | 3840 x 2160 | |||||
| QUXGA+ | 3840 x 2400 | |||||
| IMAX 3D | 4096 x 3072 | |||||
| 8K UHD (8K, 8K Ultra HD, UHDTV) | 7680 x 4320 | |||||
| 10K (10240×4320, 10K HD) | 10240 x (any) | |||||
| 16K (Quad UHD, 16K UHD, 8640P) | 15360 x 8640 |

https://www.discovery.com/science/mexapixels-in-human-eye
About 576 megapixels for the entire field of view.
Consider a view in front of you that is 90 degrees by 90 degrees, like looking through an open window at a scene. The number of pixels would be:
90 degrees * 60 arc-minutes/degree * 1/0.3 * 90 * 60 * 1/0.3 = 324,000,000 pixels (324 megapixels).
At any one moment, you actually do not perceive that many pixels, but your eye moves around the scene to see all the detail you want. But the human eye really sees a larger field of view, close to 180 degrees. Let’s be conservative and use 120 degrees for the field of view. Then we would see:
120 * 120 * 60 * 60 / (0.3 * 0.3) = 576 megapixels.
Or.
7 megapixels for the 2 degree focus arc… + 1 megapixel for the rest.
https://clarkvision.com/articles/eye-resolution.html
Details in the post
When collecting hdri make sure the data supports basic metadata, such as:
In image processing, computer graphics, and photography, high dynamic range imaging (HDRI or just HDR) is a set of techniques that allow a greater dynamic range of luminances (a Photometry measure of the luminous intensity per unit area of light travelling in a given direction. It describes the amount of light that passes through or is emitted from a particular area, and falls within a given solid angle) between the lightest and darkest areas of an image than standard digital imaging techniques or photographic methods. This wider dynamic range allows HDR images to represent more accurately the wide range of intensity levels found in real scenes ranging from direct sunlight to faint starlight and to the deepest shadows.
The two main sources of HDR imagery are computer renderings and merging of multiple photographs, which in turn are known as low dynamic range (LDR) or standard dynamic range (SDR) images. Tone Mapping (Look-up) techniques, which reduce overall contrast to facilitate display of HDR images on devices with lower dynamic range, can be applied to produce images with preserved or exaggerated local contrast for artistic effect. Photography
In photography, dynamic range is measured in Exposure Values (in photography, exposure value denotes all combinations of camera shutter speed and relative aperture that give the same exposure. The concept was developed in Germany in the 1950s) differences or stops, between the brightest and darkest parts of the image that show detail. An increase of one EV or one stop is a doubling of the amount of light.
The human response to brightness is well approximated by a Steven’s power law, which over a reasonable range is close to logarithmic, as described by the Weber�Fechner law, which is one reason that logarithmic measures of light intensity are often used as well.
HDR is short for High Dynamic Range. It’s a term used to describe an image which contains a greater exposure range than the “black” to “white” that 8 or 16-bit integer formats (JPEG, TIFF, PNG) can describe. Whereas these Low Dynamic Range images (LDR) can hold perhaps 8 to 10 f-stops of image information, HDR images can describe beyond 30 stops and stored in 32 bit images.

Sourcetree and GitHub Desktop are both free, GUI-based Git clients aimed at simplifying version control for developers. While they share the same core purpose—making Git more accessible—they differ in features, UI design, integration options, and target audiences.
| Feature | Sourcetree | GitHub Desktop |
|---|---|---|
| Branch Visualization | Detailed graph view with drag-and-drop for rebasing/merging | Linear graph, simpler but less configurable |
| Staging & Commit | File-by-file staging, inline diff view | All-or-nothing staging, side-by-side diff |
| Interactive Rebase | Full support via UI | Basic support via command line only |
| Conflict Resolution | Built-in merge tool integration (DiffMerge, Beyond Compare) | Contextual conflict editor with choice panels |
| Submodule Management | Native submodule support | Limited; requires CLI |
| Custom Actions / Hooks | Define custom actions (e.g., launch scripts) | No UI for custom Git hooks |
| Git Flow / Hg Flow | Built-in support | None |
| Performance | Can lag on very large repos | Generally snappier on medium-sized repos |
| Memory Footprint | Higher RAM usage | Lightweight |
| Platform Integration | Atlassian Bitbucket, Jira | Deep GitHub.com / Enterprise integration |
| Learning Curve | Steeper for beginners | Beginner-friendly |
Pros:
Cons:
Pros:
Cons:
Choose Sourcetree if you:
Choose GitHub Desktop if you:







COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.