



BREAKING NEWS
LATEST POSTS
-
RigAnything – Template-Free Autoregressive Rigging for Diverse 3D Assets
https://www.liuisabella.com/RigAnything
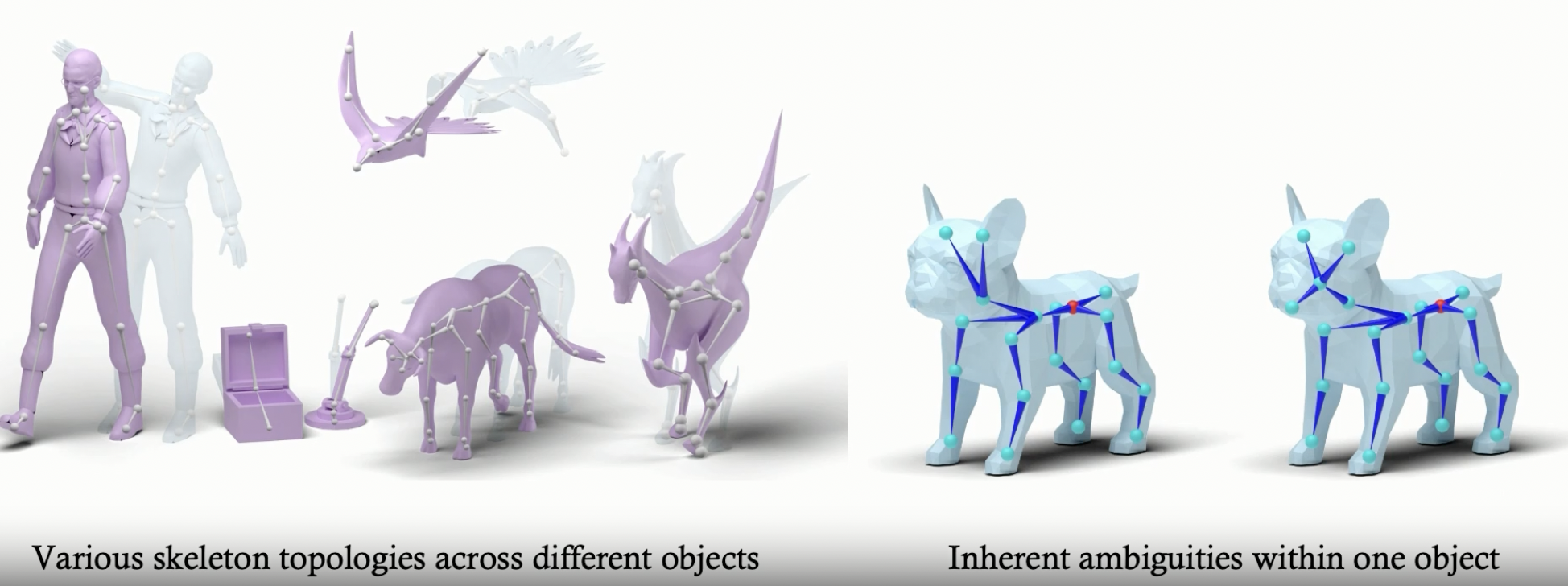
RigAnything was developed through a collaboration between UC San Diego, Adobe Research, and Hillbot Inc. It addresses one of 3D animation’s most persistent challenges: automatic rigging.
- Template-Free Autoregressive Rigging. A transformer-based model that sequentially generates skeletons without predefined templates, enabling automatic rigging across diverse 3D assets through probabilistic joint prediction and skinning weight assignment.
- Support Arbitrary Input Pose. Generates high-quality skeletons for shapes in any pose through online joint pose augmentation during training, eliminating the common rest-pose requirement of existing methods and enabling broader real-world applications.
- Fast Rigging Speed. Achieves 20x faster performance than existing template-based methods, completing rigging in under 2 seconds per shape.
-
Skywork SkyReels – All-in-one open source AI video creation based on Hynyuan
https://github.com/SkyworkAI/SkyReels-V1
All-in-one AI platform for video creation, including voiceover, lipsync, SFX, and editing. One click turn text to video & image to video. Turns idea into stunning video in minutes. Check Pricing Details. Start For Free. All-In-One Platform.
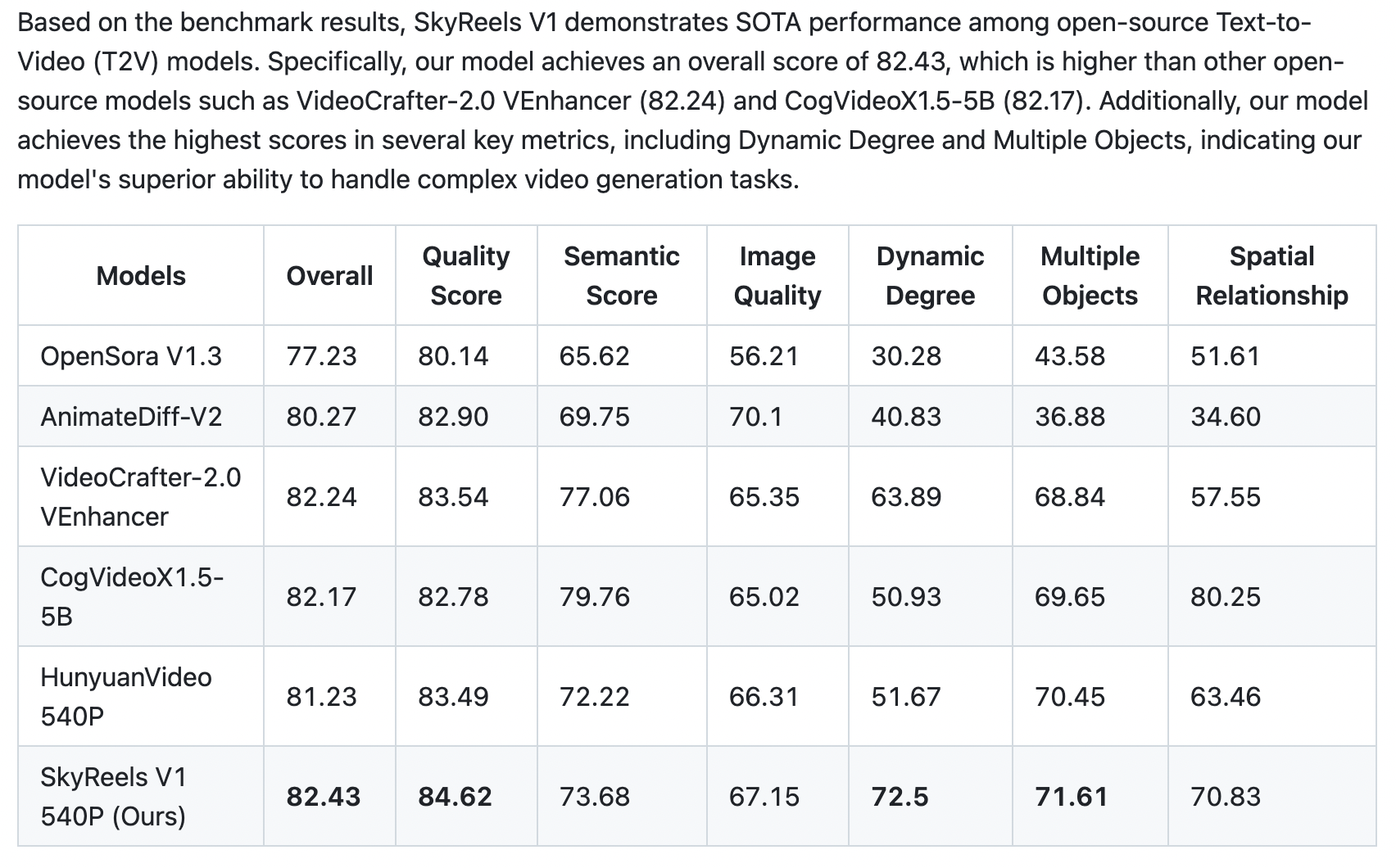
SkyReels-V1 is purpose-built for AI short video production based on Hynyuan. It achieves cinematic-grade micro-expression performances with 33 nuanced facial expressions and 400+ natural body movements that can be freely combined. The model integrates film-quality lighting aesthetics, generating visually stunning compositions and textures through text-to-video or image-to-video conversion – outperforming all existing open-source models across key metrics.

-
Shanhai based StepFun – Open source Step-Video-T2V
https://huggingface.co/stepfun-ai/stepvideo-t2v
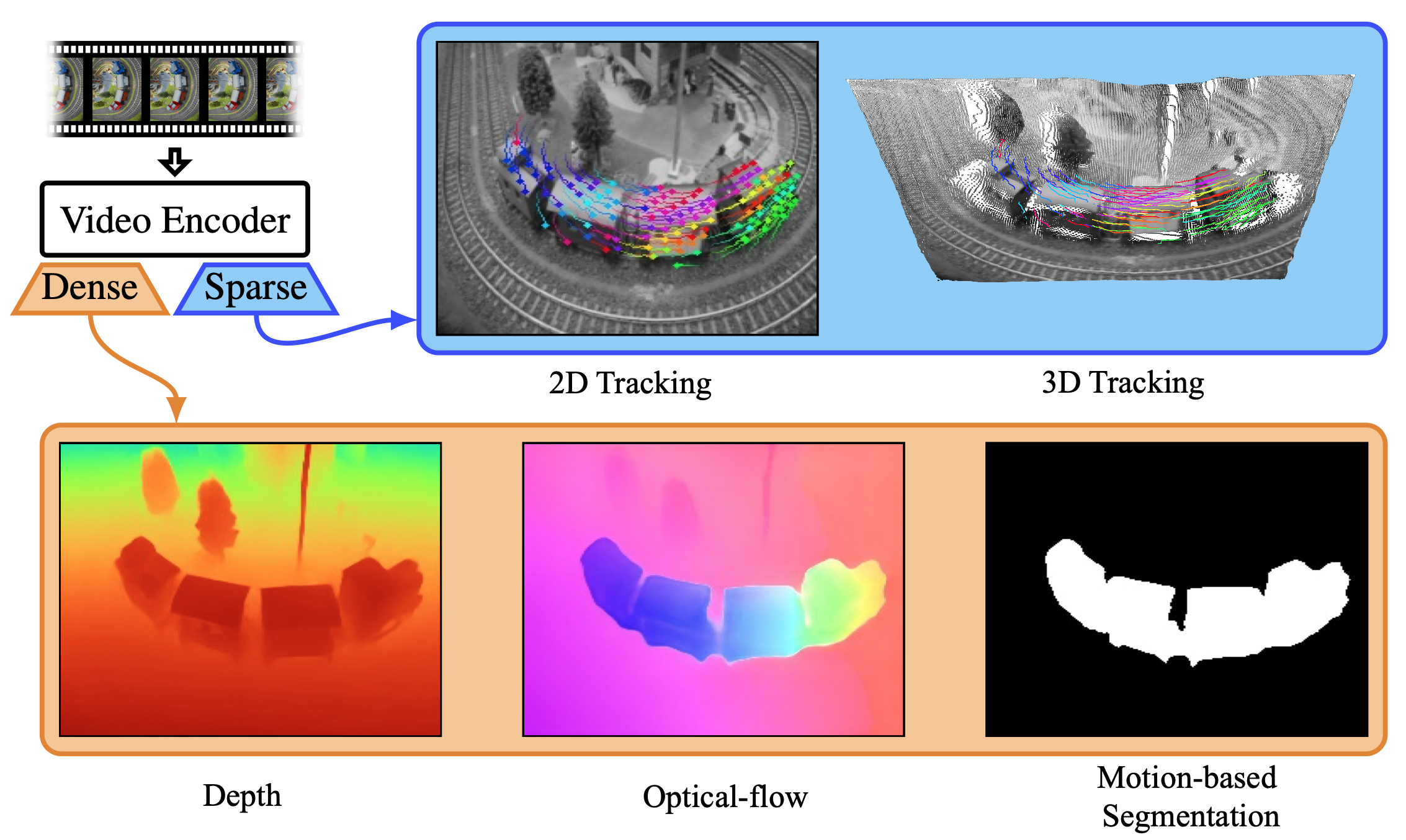
The model generates videos up to 204 frames, using a high-compression Video-VAE (16×16 spatial, 8x temporal). It processes English and Chinese prompts via bilingual text encoders. A 3D full-attention DiT, trained with Flow Matching, denoises latent frames conditioned on text and timesteps. A video-based DPO further reduces artifacts, enhancing realism and smoothness.











FEATURED POSTS





-
GretagMacbeth Color Checker Numeric Values and Middle Gray
The human eye perceives half scene brightness not as the linear 50% of the present energy (linear nature values) but as 18% of the overall brightness. We are biased to perceive more information in the dark and contrast areas. A Macbeth chart helps with calibrating back into a photographic capture into this “human perspective” of the world.
https://en.wikipedia.org/wiki/Middle_gray
In photography, painting, and other visual arts, middle gray or middle grey is a tone that is perceptually about halfway between black and white on a lightness scale in photography and printing, it is typically defined as 18% reflectance in visible light

Light meters, cameras, and pictures are often calibrated using an 18% gray card[4][5][6] or a color reference card such as a ColorChecker. On the assumption that 18% is similar to the average reflectance of a scene, a grey card can be used to estimate the required exposure of the film.
https://en.wikipedia.org/wiki/ColorChecker
(more…)


-
Mania Carta – Photorealistic Characters Made in Blender
Maniacarta is an Artist based in Tokyo, her Artworks are unique and she strive to create the best characters that have soul in the World.
https://80.lv/articles/marvelous-photorealistic-characters-made-in-blender-by-mania-carta/
https://www.instagram.com/mania_carta/




