



BREAKING NEWS
LATEST POSTS
-
Seaweed APT – Diffusion Adversarial Post-Training for One-Step Video Generation
https://cdn.seaweed-apt.com/assets/showreel/seaweed-apt.mp4
This demonstrate large-scale text-to-video generation with a single neural function evaluation (1NFE) by using our proposed adversarial post-training technique. Our model generates 2 seconds of 1280×720 24fps videos in real-time

-
Pyper – a flexible framework for concurrent and parallel data-processing in Python
Pyper is a flexible framework for concurrent and parallel data-processing, based on functional programming patterns.
https://github.com/pyper-dev/pyper

-
Jacob Bartlett – Apple is Killing Swift
https://blog.jacobstechtavern.com/p/apple-is-killing-swift
Jacob Bartlett argues that Swift, once envisioned as a simple and composable programming language by its creator Chris Lattner, has become overly complex due to Apple’s governance. Bartlett highlights that Swift now contains 217 reserved keywords, deviating from its original goal of simplicity. He contrasts Swift’s governance model, where Apple serves as the project lead and arbiter, with other languages like Python and Rust, which have more community-driven or balanced governance structures. Bartlett suggests that Apple’s control has led to Swift’s current state, moving away from Lattner’s initial vision.

-
Don’t Splat your Gaussians – Volumetric Ray-Traced Primitives for Modeling and Rendering Scattering and Emissive Media
https://arcanous98.github.io/projectPages/gaussianVolumes.html
We propose a compact and efficient alternative to existing volumetric representations for rendering such as voxel grids.

-
IPAdapter – Text Compatible Image Prompt Adapter for Text-to-Image Image-to-Image Diffusion Models and ComfyUI implementation
github.com/tencent-ailab/IP-Adapter
The IPAdapter are very powerful models for image-to-image conditioning. The subject or even just the style of the reference image(s) can be easily transferred to a generation. Think of it as a 1-image lora. They are an effective and lightweight adapter to achieve image prompt capability for the pre-trained text-to-image diffusion models. An IP-Adapter with only 22M parameters can achieve comparable or even better performance to a fine-tuned image prompt model.
Once the IP-Adapter is trained, it can be directly reusable on custom models fine-tuned from the same base model.The IP-Adapter is fully compatible with existing controllable tools, e.g., ControlNet and T2I-Adapter.

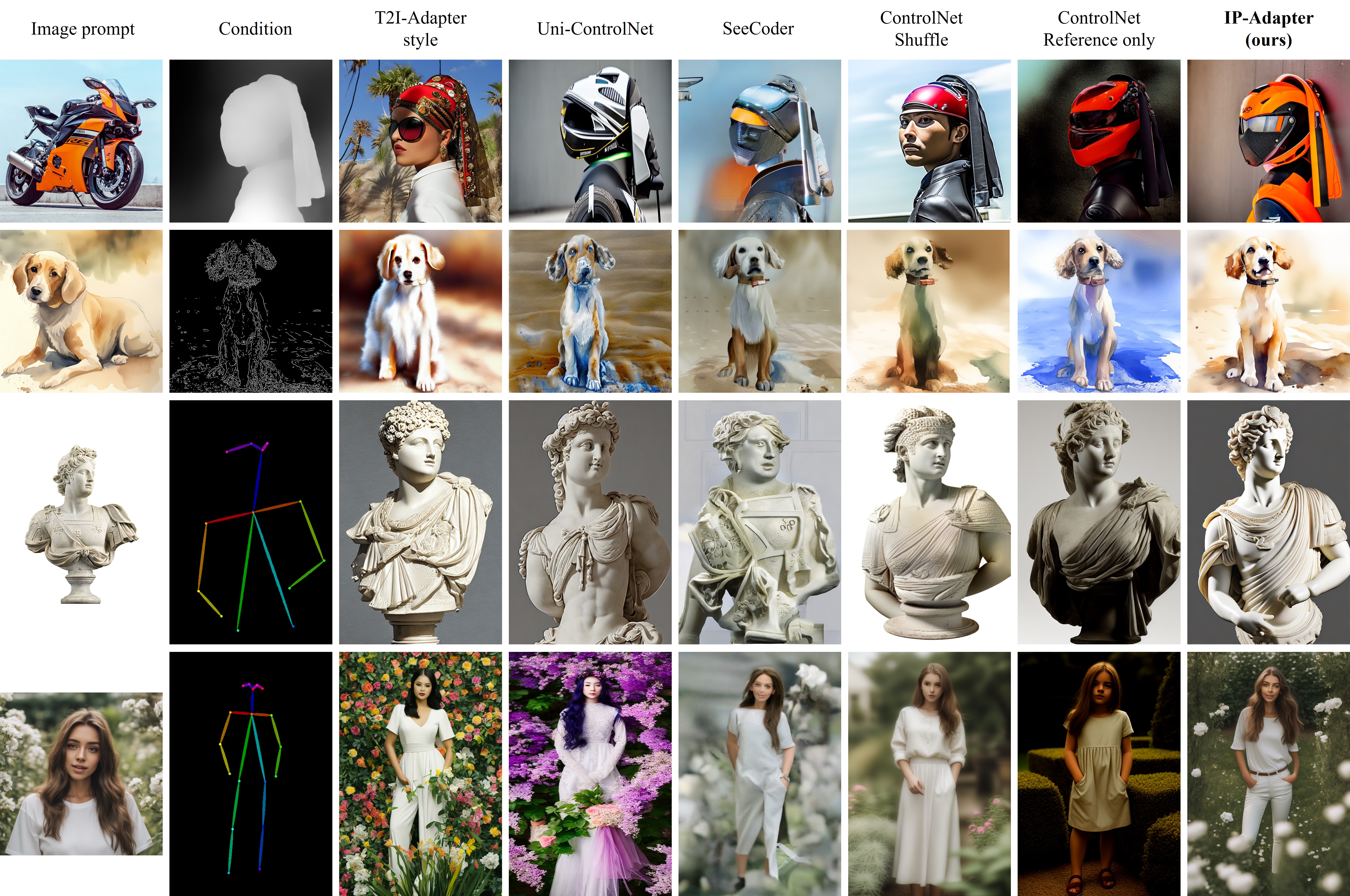
-
SPAR3D – Stable Point-Aware Reconstruction of 3D Objects from Single Images
SPAR3D is a fast single-image 3D reconstructor with intermediate point cloud generation, which allows for interactive user edits and achieves state-of-the-art performance.
https://github.com/Stability-AI/stable-point-aware-3d
https://stability.ai/news/stable-point-aware-3d?utm_source=x&utm_medium=social&utm_campaign=SPAR3D

-
MiniMax-01 goes open source
MiniMax is thrilled to announce the release of the MiniMax-01 series, featuring two groundbreaking models:
MiniMax-Text-01: A foundational language model.
MiniMax-VL-01: A visual multi-modal model.Both models are now open-source, paving the way for innovation and accessibility in AI development!
🔑 Key Innovations
1. Lightning Attention Architecture: Combines 7/8 Lightning Attention with 1/8 Softmax Attention, delivering unparalleled performance.
2. Massive Scale with MoE (Mixture of Experts): 456B parameters with 32 experts and 45.9B activated parameters.
3. 4M-Token Context Window: Processes up to 4 million tokens, 20–32x the capacity of leading models, redefining what’s possible in long-context AI applications.💡 Why MiniMax-01 Matters
1. Innovative Architecture for Top-Tier Performance
The MiniMax-01 series introduces the Lightning Attention mechanism, a bold alternative to traditional Transformer architectures, delivering unmatched efficiency and scalability.2. 4M Ultra-Long Context: Ushering in the AI Agent Era
With the ability to handle 4 million tokens, MiniMax-01 is designed to lead the next wave of agent-based applications, where extended context handling and sustained memory are critical.3. Unbeatable Cost-Effectiveness
Through proprietary architectural innovations and infrastructure optimization, we’re offering the most competitive pricing in the industry:
$0.2 per million input tokens
$1.1 per million output tokens🌟 Experience the Future of AI Today
We believe MiniMax-01 is poised to transform AI applications across industries. Whether you’re building next-gen AI agents, tackling ultra-long context tasks, or exploring new frontiers in AI, MiniMax-01 is here to empower your vision.✅ Try it now for free: hailuo.ai
📄 Read the technical paper: filecdn.minimax.chat/_Arxiv_MiniMax_01_Report.pdf
🌐 Learn more: minimaxi.com/en/news/minimax-01-series-2
💡API Platform: intl.minimaxi.com/












FEATURED POSTS


-
The Public Domain Is Working Again — No Thanks To Disney
www.cartoonbrew.com/law/the-public-domain-is-working-again-no-thanks-to-disney-169658.html
The law protects new works from unauthorized copying while allowing artists free rein on older works.
The Copyright Act of 1909 used to govern copyrights. Under that law, a creator had a copyright on his creation for 28 years from “publication,” which could then be renewed for another 28 years. Thus, after 56 years, a work would enter the public domain.
However, the Congress passed the Copyright Act of 1976, extending copyright protection for works made for hire to 75 years from publication.
Then again, in 1998, Congress passed the Sonny Bono Copyright Term Extension Act (derided as the “Mickey Mouse Protection Act” by some observers due to the Walt Disney Company’s intensive lobbying efforts), which added another twenty years to the term of copyright.
it is because Snow White was in the public domain that it was chosen to be Disney’s first animated feature.
Ironically, much of Disney’s legislative lobbying over the last several decades has been focused on preventing this same opportunity to other artists and filmmakers.The battle in the coming years will be to prevent further extensions to copyright law that benefit corporations at the expense of creators and society as a whole.
-
Tencent Hunyuan3D 2.1 goes Open Source and adds MV (Multi-view) and MV Mini
https://huggingface.co/tencent/Hunyuan3D-2mv
https://huggingface.co/tencent/Hunyuan3D-2mini
https://github.com/Tencent/Hunyuan3D-2
Tencent just made Hunyuan3D 2.1 open-source.
This is the first fully open-source, production-ready PBR 3D generative model with cinema-grade quality.
https://github.com/Tencent-Hunyuan/Hunyuan3D-2.1
What makes it special?
• Advanced PBR material synthesis brings realistic materials like leather, bronze, and more to life with stunning light interactions.
• Complete access to model weights, training/inference code, data pipelines.
• Optimized to run on accessible hardware.
• Built for real-world applications with professional-grade output quality.
They’re making it accessible to everyone:
• Complete open-source ecosystem with full documentation.
• Ready-to-use model weights and training infrastructure.
• Live demo available for instant testing.
• Comprehensive GitHub repository with implementation details.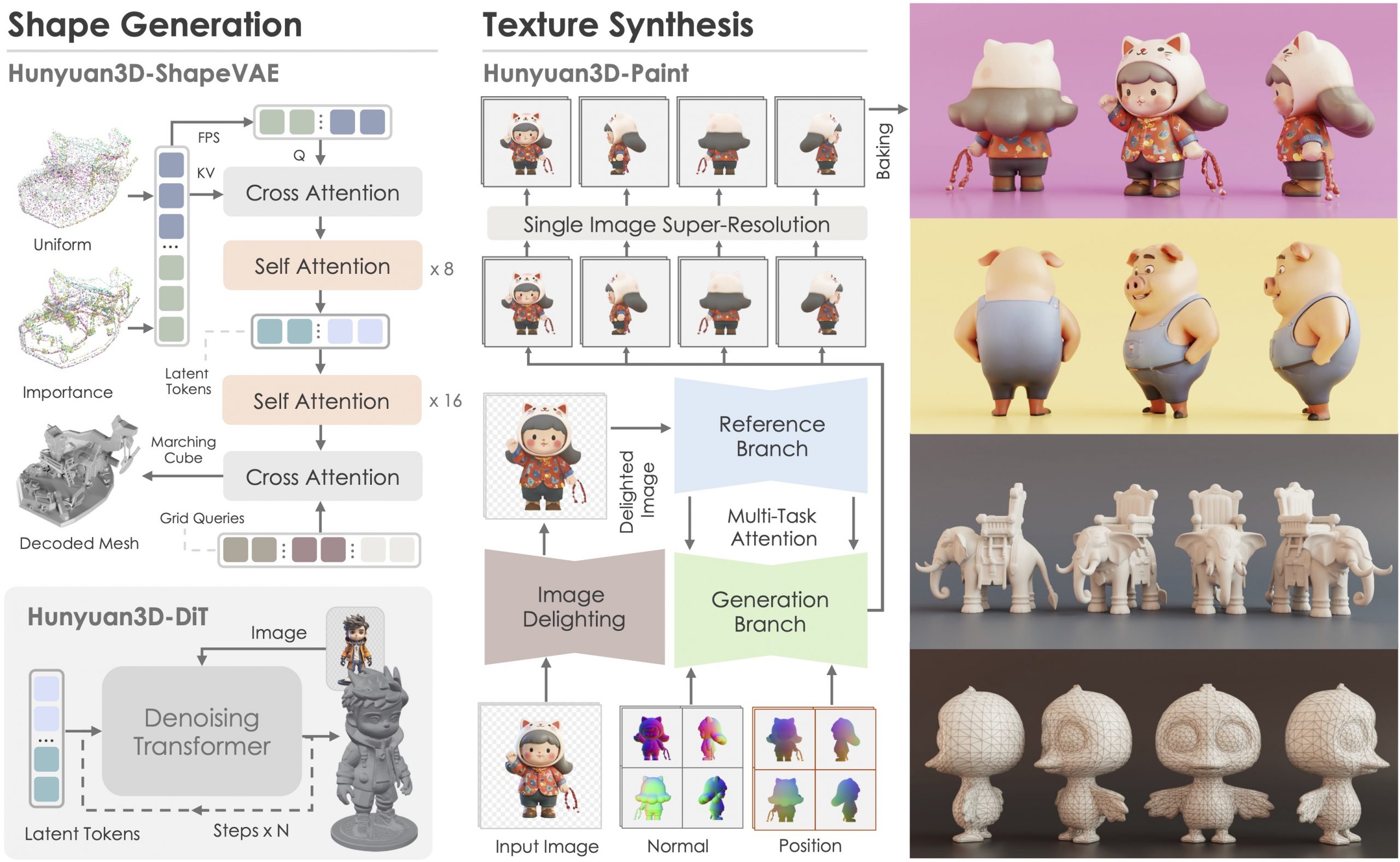



-
3D Lighting Tutorial by Amaan Kram
http://www.amaanakram.com/lightingT/part1.htm
The goals of lighting in 3D computer graphics are more or less the same as those of real world lighting.
Lighting serves a basic function of bringing out, or pushing back the shapes of objects visible from the camera’s view.
It gives a two-dimensional image on the monitor an illusion of the third dimension-depth.But it does not just stop there. It gives an image its personality, its character. A scene lit in different ways can give a feeling of happiness, of sorrow, of fear etc., and it can do so in dramatic or subtle ways. Along with personality and character, lighting fills a scene with emotion that is directly transmitted to the viewer.
Trying to simulate a real environment in an artificial one can be a daunting task. But even if you make your 3D rendering look absolutely photo-realistic, it doesn’t guarantee that the image carries enough emotion to elicit a “wow” from the people viewing it.
Making 3D renderings photo-realistic can be hard. Putting deep emotions in them can be even harder. However, if you plan out your lighting strategy for the mood and emotion that you want your rendering to express, you make the process easier for yourself.
Each light source can be broken down in to 4 distinct components and analyzed accordingly.
· Intensity
· Direction
· Color
· SizeThe overall thrust of this writing is to produce photo-realistic images by applying good lighting techniques.
