



BREAKING NEWS
LATEST POSTS
-
Wyz Borrero – AI-generated “casting”
Guillermo del Toro and Ben Affleck, among others, have voiced concerns about the capabilities of generative AI in the creative industries. They believe that while AI can produce text, images, sound, and video that are technically proficient, it lacks the authentic emotional depth and creative intuition inherent in human artistry—qualities that define works like those of Shakespeare, Dalí, or Hitchcock.
Generative AI models are trained on vast datasets and excel at recognizing and replicating patterns. They can generate coherent narratives, mimic writing or artistic styles, and even compose poetry and music. However, they do not possess consciousness or genuine emotions. The “emotion” conveyed in AI-generated content is a reflection of learned patterns rather than true emotional experience.
Having extensively tested and used generative AI over the past four years, I observe that the rapid advancement of the field suggests many current limitations could be overcome in the future. As models become more sophisticated and training data expands, AI systems are increasingly capable of generating content that is coherent, contextually relevant, stylistically diverse, and can even evoke emotional responses.
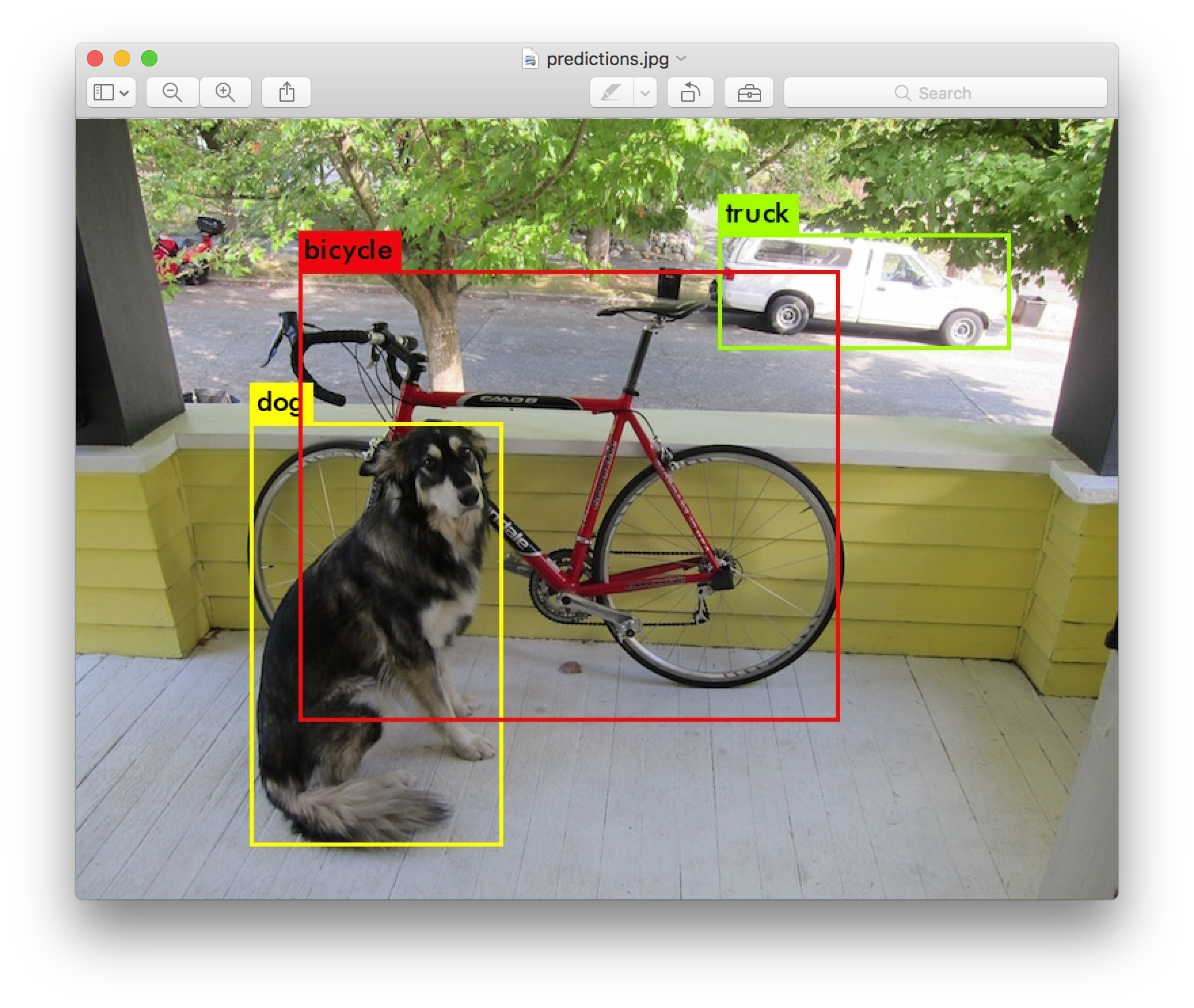
The following video is an AI-generated “casting” using a text-to-video model specifically prompted to test emotion, expressions, and microexpressions. This is only the beginning.












FEATURED POSTS

-
MiniMax-01 goes open source
MiniMax is thrilled to announce the release of the MiniMax-01 series, featuring two groundbreaking models:
MiniMax-Text-01: A foundational language model.
MiniMax-VL-01: A visual multi-modal model.Both models are now open-source, paving the way for innovation and accessibility in AI development!
🔑 Key Innovations
1. Lightning Attention Architecture: Combines 7/8 Lightning Attention with 1/8 Softmax Attention, delivering unparalleled performance.
2. Massive Scale with MoE (Mixture of Experts): 456B parameters with 32 experts and 45.9B activated parameters.
3. 4M-Token Context Window: Processes up to 4 million tokens, 20–32x the capacity of leading models, redefining what’s possible in long-context AI applications.💡 Why MiniMax-01 Matters
1. Innovative Architecture for Top-Tier Performance
The MiniMax-01 series introduces the Lightning Attention mechanism, a bold alternative to traditional Transformer architectures, delivering unmatched efficiency and scalability.2. 4M Ultra-Long Context: Ushering in the AI Agent Era
With the ability to handle 4 million tokens, MiniMax-01 is designed to lead the next wave of agent-based applications, where extended context handling and sustained memory are critical.3. Unbeatable Cost-Effectiveness
Through proprietary architectural innovations and infrastructure optimization, we’re offering the most competitive pricing in the industry:
$0.2 per million input tokens
$1.1 per million output tokens🌟 Experience the Future of AI Today
We believe MiniMax-01 is poised to transform AI applications across industries. Whether you’re building next-gen AI agents, tackling ultra-long context tasks, or exploring new frontiers in AI, MiniMax-01 is here to empower your vision.✅ Try it now for free: hailuo.ai
📄 Read the technical paper: filecdn.minimax.chat/_Arxiv_MiniMax_01_Report.pdf
🌐 Learn more: minimaxi.com/en/news/minimax-01-series-2
💡API Platform: intl.minimaxi.com/


-
VFX pipeline – Render Wall management topics
1: Introduction Title: Managing a VFX Facility’s Render Wall
- Briefly introduce the importance of managing a VFX facility’s render wall.
- Highlight how efficient management contributes to project timelines and overall productivity.
2: Daily Overview Title: Daily Management Routine
- Monitor Queues: Begin each day by reviewing render queues to assess workload and priorities.
- Resource Allocation: Allocate resources based on project demands and available hardware.
- Job Prioritization: Set rendering priorities according to project deadlines and importance.
- Queue Optimization: Adjust queue settings to maximize rendering efficiency.
3: Resource Allocation Title: Efficient Resource Management
- Hardware Utilization: Distribute rendering tasks across available machines for optimal resource usage.
- Balance Workloads: Avoid overloading specific machines while others remain underutilized.
- Consider Off-Peak Times: Schedule resource-intensive tasks during off-peak hours to enhance overall performance.
4: Job Prioritization Title: Prioritizing Rendering Tasks
- Deadline Sensitivity: Give higher priority to tasks with imminent deadlines to ensure timely delivery.
- Critical Shots: Identify shots crucial to the project’s narrative or visual impact for prioritization.
- Dependent Shots: Sequence shots that depend on others should be prioritized together.
5: Queue Optimization and Reporting Title: Streamlining Render Queues
- Dependency Management: Set up dependencies to ensure shots are rendered in the correct order.
- Error Handling: Implement automated error detection and requeueing mechanisms.
- Progress Tracking: Regularly monitor rendering progress and update stakeholders.
- Data Management: Archive completed renders and remove redundant data to free up storage.
- Reporting: Provide daily reports on rendering status, resource usage, and potential bottlenecks.
6: Conclusion Title: Enhancing VFX Workflow
- Effective management of a VFX facility’s render wall is essential for project success.
- Daily monitoring, resource allocation, job prioritization, queue optimization, and reporting are key components.
- A well-managed render wall ensures efficient production, timely delivery, and overall project success.



