



BREAKING NEWS
LATEST POSTS
-
GIL To Become Optional in Python 3.13
GIL or Global Interpreter Lock can be disabled in Python version 3.13. This is currently experimental.
What is GIL? It is a mechanism used by the CPython interpreter to ensure that only one thread executes the Python bytecode at a time.
https://medium.com/@r_bilan/python-3-13-without-the-gil-a-game-changer-for-concurrency-5e035500f0da
Advantages of the GIL
- Simplicity of Implementation: The GIL simplifies memory management in CPython by preventing concurrent access to Python objects, which can help avoid race conditions and other threading issues.
- Ease of Use for Single-Threaded Programs: For applications that are single-threaded, the GIL eliminates the overhead associated with managing thread safety, allowing for straightforward and efficient code execution.
- Compatibility with C Extensions: The GIL allows C extensions to operate without needing to implement complex threading models, which simplifies the development of Python extensions that interface with C libraries.
- Performance for I/O-Bound Tasks: In I/O-bound applications, the GIL does not significantly hinder performance since threads can be switched out during I/O operations, allowing other threads to run.
Disadvantages of the GIL
- Limited Multithreading Performance: The GIL can severely restrict the performance of CPU-bound multithreaded applications, as it only allows one thread to execute Python bytecode at a time, leading to underutilization of multicore processors.
- Thread Management Complexity: Although the GIL simplifies memory management, it can complicate the design of concurrent applications, forcing developers to carefully manage threading issues or use multiprocessing instead.
- Hindrance to Parallel Processing: With the GIL enabled, achieving true parallelism in Python applications is challenging, making it difficult for developers to leverage multicore architectures effectively.
- Inefficiency in Context Switching: Frequent context switching due to the GIL can introduce overhead, especially in applications with many threads, leading to performance degradation.
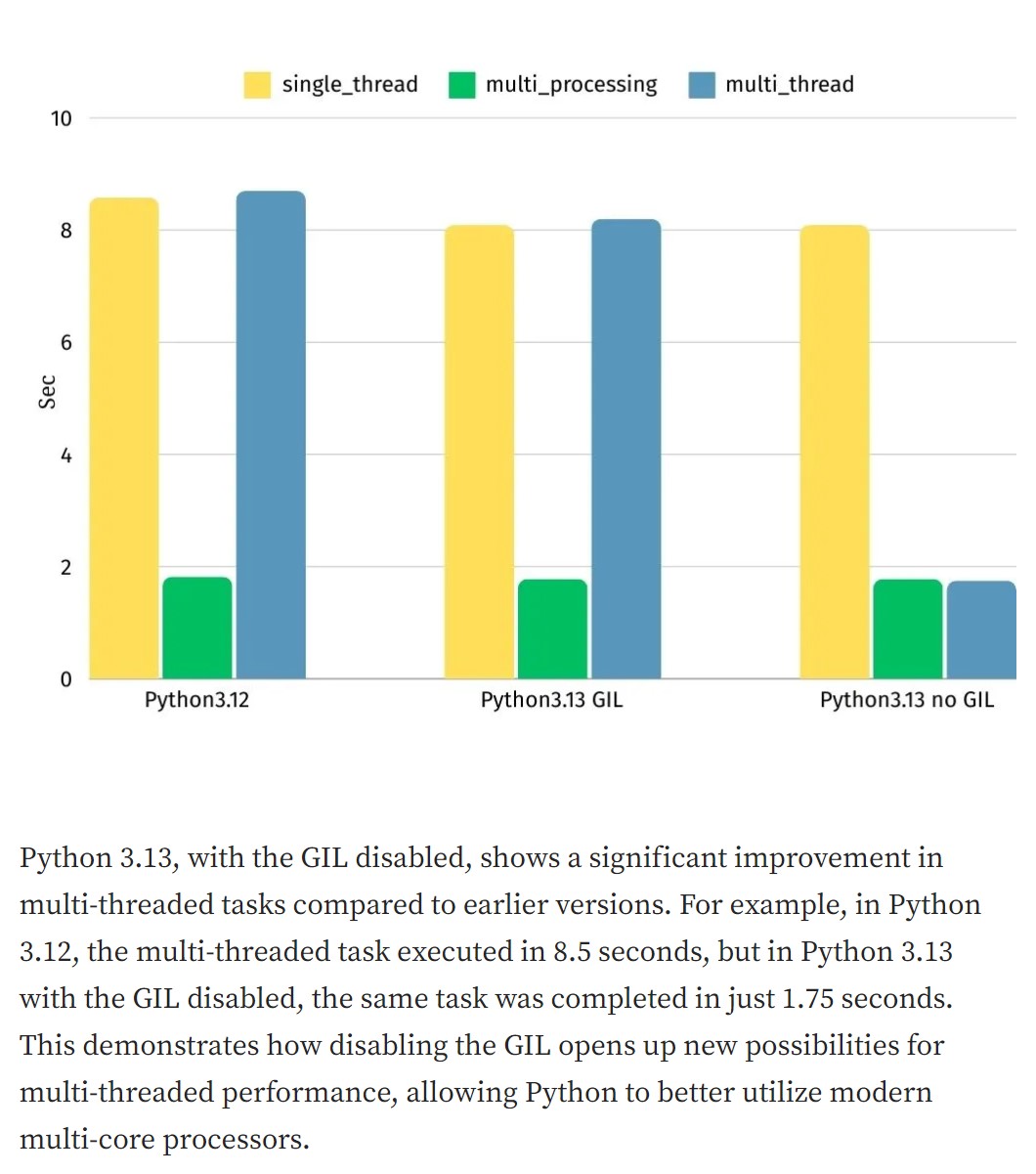
https://geekpython.in/gil-become-optional-in-python

-
Ben Gunsberger – AI generated podcast about AI using Google NotebookLM
Listen to the podcast in the post
“I just created a AI-Generated podcast by feeding an article I write into Google’s NotebookLM. If I hadn’t make it myself, I would have been 100% fooled into thinking it was real people talking.”
-
Apple releases Depth Pro – An open source AI model that rewrites the rules of 3D vision
The model is fast, producing a 2.25-megapixel depth map in 0.3 seconds on a standard GPU.
https://github.com/apple/ml-depth-pro
https://arxiv.org/pdf/2410.02073


-
Anders Langlands – Render Color Spaces
https://www.colour-science.org/anders-langlands/
This page compares images rendered in Arnold using spectral rendering and different sets of colourspace primaries: Rec.709, Rec.2020, ACES and DCI-P3. The SPD data for the GretagMacbeth Color Checker are the measurements of Noburu Ohta, taken from Mansencal, Mauderer and Parsons (2014) colour-science.org.

-
Björn Ottosson – How software gets color wrong
https://bottosson.github.io/posts/colorwrong/
Most software around us today are decent at accurately displaying colors. Processing of colors is another story unfortunately, and is often done badly.
To understand what the problem is, let’s start with an example of three ways of blending green and magenta:
- Perceptual blend – A smooth transition using a model designed to mimic human perception of color. The blending is done so that the perceived brightness and color varies smoothly and evenly.
- Linear blend – A model for blending color based on how light behaves physically. This type of blending can occur in many ways naturally, for example when colors are blended together by focus blur in a camera or when viewing a pattern of two colors at a distance.
- sRGB blend – This is how colors would normally be blended in computer software, using sRGB to represent the colors.

Let’s look at some more examples of blending of colors, to see how these problems surface more practically. The examples use strong colors since then the differences are more pronounced. This is using the same three ways of blending colors as the first example.

Instead of making it as easy as possible to work with color, most software make it unnecessarily hard, by doing image processing with representations not designed for it. Approximating the physical behavior of light with linear RGB models is one easy thing to do, but more work is needed to create image representations tailored for image processing and human perception.
Also see:
-
EVER (Exact Volumetric Ellipsoid Rendering) – Gaussian splatting alternative
https://radiancefields.com/how-ever-(exact-volumetric-ellipsoid-rendering)-does-this-work
https://half-potato.gitlab.io/posts/ever/
Unlike previous methods like Gaussian Splatting, EVER leverages ellipsoids instead of Gaussians and uses Ray Tracing instead of Rasterization. This shift eliminates artifacts like popping and blending inconsistencies, offering sharper and more accurate renderings.

-
The Rise and Fall of Adobe – The better, alternative software list to a criminal company

Best alternatives to Adobe:
https://github.com/KenneyNL/Adobe-Alternatives
- Affinity (Photo and illustration editing) https://affinity.serif.com/
- DaVinci Resolve (video editing): https://www.blackmagicdesign.com/au/products/davinciresolve/
- Clip Studio Paint (illustration): https://www.clipstudio.net/en/
- Toon Boom (animation): https://www.toonboom.com/
-
Microsoft is discontinuing its HoloLens headsets
https://www.theverge.com/2024/10/1/24259369/microsoft-hololens-2-discontinuation-support
Software support for the original HoloLens headset will end on December 10th.
Microsoft’s struggles with HoloLens have been apparent over the past two years.







FEATURED POSTS

-
AI and the Law – Laurence Van Elegem : The era of gigantic AI models like GPT-4 is coming to an end
https://www.linkedin.com/feed/update/urn:li:activity:7061987804548870144
Sam Altman, CEO of OpenAI, dropped a 💣 at a recent MIT event, declaring that the era of gigantic AI models like GPT-4 is coming to an end. He believes that future progress in AI needs new ideas, not just bigger models.
So why is that revolutionary? Well, this is how OpenAI’s LLMs (the models that ‘feed’ chatbots like ChatGPT & Google Bard) grew exponentially over the years:
➡️GPT-2 (2019): 1.5 billion parameters
➡️GPT-3 (2020): 175 billion parameters
➡️GPT-4: (2023): amount undisclosed – but likely trillions of parametersThat kind of parameter growth is no longer tenable, feels Altman.
Why?:
➡️RETURNS: scaling up model size comes with diminishing returns.
➡️PHYSICAL LIMITS: there’s a limit to how many & how quickly data centers can be built.
➡️COST: ChatGPT cost over over 100 million dollars to develop.What is he NOT saying? That access to data is becoming damned hard & expensive. So if you have a model that keeps needing more data to become better, that’s a problem.
Why is it becoming harder and more expensive to access data?
🎨Copyright conundrums: Getty Images, individual artists like Sarah Andersen, Kelly McKernan & Karloa Otiz are suing AI companies over unauthorized use of their content. Universal Music asked Spotify & Apple Music to stop AI companies from accessing their songs for training.
🔐Privacy matters & regulation: Italy banned ChatGPT over privacy concerns (now back after changes). Germany, France, Ireland, Canada, and Spain remain suspicious. Samsung even warned employees not to use AI tools like ChatGPT for security reasons.
💸Data monetization: Twitter, Reddit, Stack Overflow & others want AI companies to pay up for training on their data. Contrary to most artists, Grimes is allowing anyone to use her voice for AI-generated songs … for a 50% profit share.
🕸️Web3’s impact: If Web3 fulfills its promise, users could store data in personal vaults or cryptocurrency wallets, making it harder for LLMs to access the data they crave.
🌎Geopolitics: it’s increasingly difficult for data to cross country borders. Just think about China and TikTok.
😷Data contamination: We have this huge amount of ‘new’ – and sometimes hallucinated – data that is being generated by generative AI chatbots. What will happen if we feed that data back into their LLMs?
No wonder that people like Sam Altman are looking for ways to make the models better without having to use more data. If you want to know more, check our brand new Radar podcast episode (link in the comments), where I talked about this & more with Steven Van Belleghem, Peter Hinssen, Pascal Coppens & Julie Vens – De Vos. We also discussed Twitter, TikTok, Walmart, Amazon, Schmidt Futures, our Never Normal Tour with Mediafin in New York (link in the comments), the human energy crisis, Apple’s new high-yield savings account, the return of China, BYD, AI investment strategies, the power of proximity, the end of Buzzfeed news & much more.

-
The Perils of Technical Debt – Understanding Its Impact on Security, Usability, and Stability
In software development, “technical debt” is a term used to describe the accumulation of shortcuts, suboptimal solutions, and outdated code that occur as developers rush to meet deadlines or prioritize immediate goals over long-term maintainability. While this concept initially seems abstract, its consequences are concrete and can significantly affect the security, usability, and stability of software systems.
The Nature of Technical Debt
Technical debt arises when software engineers choose a less-than-ideal implementation in the interest of saving time or reducing upfront effort. Much like financial debt, these decisions come with an interest rate: over time, the cost of maintaining and updating the system increases, and more effort is required to fix problems that stem from earlier choices. In extreme cases, technical debt can slow development to a crawl, causing future updates or improvements to become far more difficult than they would have been with cleaner, more scalable code.
Impact on Security
One of the most significant threats posed by technical debt is the vulnerability it creates in terms of software security. Outdated code often lacks the latest security patches or is built on legacy systems that are no longer supported. Attackers can exploit these weaknesses, leading to data breaches, ransomware, or other forms of cybercrime. Furthermore, as systems grow more complex and the debt compounds, identifying and fixing vulnerabilities becomes increasingly challenging. Failing to address technical debt leaves an organization exposed to security risks that may only become apparent after a costly incident.
Impact on Usability
Technical debt also affects the user experience. Systems burdened by outdated code often become clunky and slow, leading to poor usability. Engineers may find themselves continuously patching minor issues rather than implementing larger, user-centric improvements. Over time, this results in a product that feels antiquated, is difficult to use, or lacks modern functionality. In a competitive market, poor usability can alienate users, causing a loss of confidence and driving them to alternative products or services.
Impact on Stability
Stability is another critical area impacted by technical debt. As developers add features or make updates to systems weighed down by previous quick fixes, they run the risk of introducing bugs or causing system crashes. The tangled, fragile nature of code laden with technical debt makes troubleshooting difficult and increases the likelihood of cascading failures. Over time, instability in the software can erode both the trust of users and the efficiency of the development team, as more resources are dedicated to resolving recurring issues rather than innovating or expanding the system’s capabilities.
The Long-Term Costs of Ignoring Technical Debt
While technical debt can provide short-term gains by speeding up initial development, the long-term costs are much higher. Unaddressed technical debt can lead to project delays, escalating maintenance costs, and an ever-widening gap between current code and modern best practices. The more technical debt accumulates, the harder and more expensive it becomes to address. For many companies, failing to pay down this debt eventually results in a critical juncture: either invest heavily in refactoring the codebase or face an expensive overhaul to rebuild from the ground up.
Conclusion
Technical debt is an unavoidable aspect of software development, but understanding its perils is essential for minimizing its impact on security, usability, and stability. By actively managing technical debt—whether through regular refactoring, code audits, or simply prioritizing long-term quality over short-term expedience—organizations can avoid the most dangerous consequences and ensure their software remains robust and reliable in an ever-changing technological landscape.
-
What’s the Difference Between Ray Casting, Ray Tracing, Path Tracing and Rasterization? Physical light tracing…
RASTERIZATION
Rasterisation (or rasterization) is the task of taking the information described in a vector graphics format OR the vertices of triangles making 3D shapes and converting them into a raster image (a series of pixels, dots or lines, which, when displayed together, create the image which was represented via shapes), or in other words “rasterizing” vectors or 3D models onto a 2D plane for display on a computer screen.For each triangle of a 3D shape, you project the corners of the triangle on the virtual screen with some math (projective geometry). Then you have the position of the 3 corners of the triangle on the pixel screen. Those 3 points have texture coordinates, so you know where in the texture are the 3 corners. The cost is proportional to the number of triangles, and is only a little bit affected by the screen resolution.
In computer graphics, a raster graphics or bitmap image is a dot matrix data structure that represents a generally rectangular grid of pixels (points of color), viewable via a monitor, paper, or other display medium.
With rasterization, objects on the screen are created from a mesh of virtual triangles, or polygons, that create 3D models of objects. A lot of information is associated with each vertex, including its position in space, as well as information about color, texture and its “normal,” which is used to determine the way the surface of an object is facing.
Computers then convert the triangles of the 3D models into pixels, or dots, on a 2D screen. Each pixel can be assigned an initial color value from the data stored in the triangle vertices.
Further pixel processing or “shading,” including changing pixel color based on how lights in the scene hit the pixel, and applying one or more textures to the pixel, combine to generate the final color applied to a pixel.
The main advantage of rasterization is its speed. However, rasterization is simply the process of computing the mapping from scene geometry to pixels and does not prescribe a particular way to compute the color of those pixels. So it cannot take shading, especially the physical light, into account and it cannot promise to get a photorealistic output. That’s a big limitation of rasterization.
There are also multiple problems:
If you have two triangles one is behind the other, you will draw twice all the pixels. you only keep the pixel from the triangle that is closer to you (Z-buffer), but you still do the work twice.
The borders of your triangles are jagged as it is hard to know if a pixel is in the triangle or out. You can do some smoothing on those, that is anti-aliasing.
You have to handle every triangles (including the ones behind you) and then see that they do not touch the screen at all. (we have techniques to mitigate this where we only look at triangles that are in the field of view)
Transparency is hard to handle (you can’t just do an average of the color of overlapping transparent triangles, you have to do it in the right order)




