Arminas created this using Juggernaut Xl model and QR Code Monster SDXL ControlNet.
His pipeline: Static Images – Forge UI. Upscaled with Leonardo AI universal upscaler. Animated with Runway ML and Minimax. Video upscale – Topaz Video AI. Composited in Adobe Premiere.
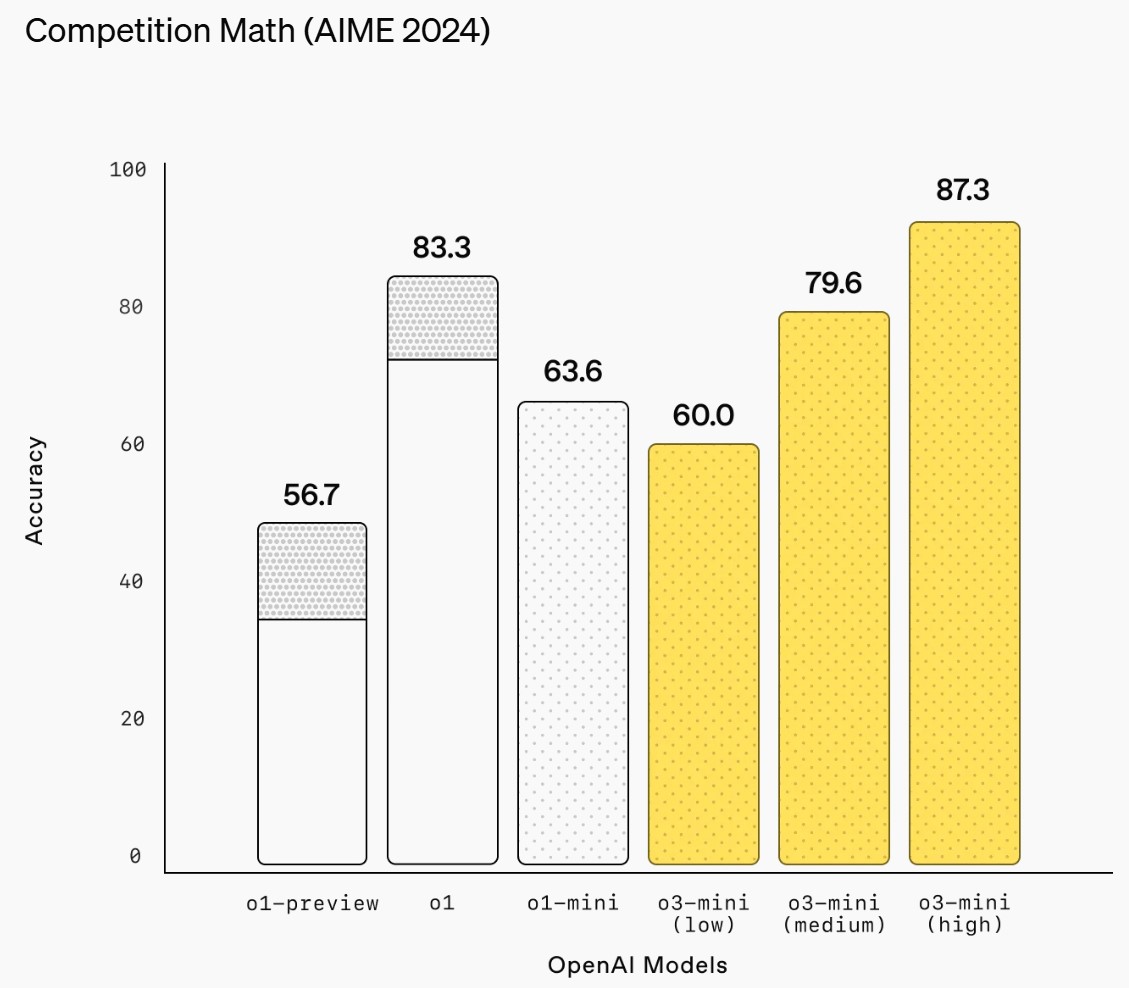
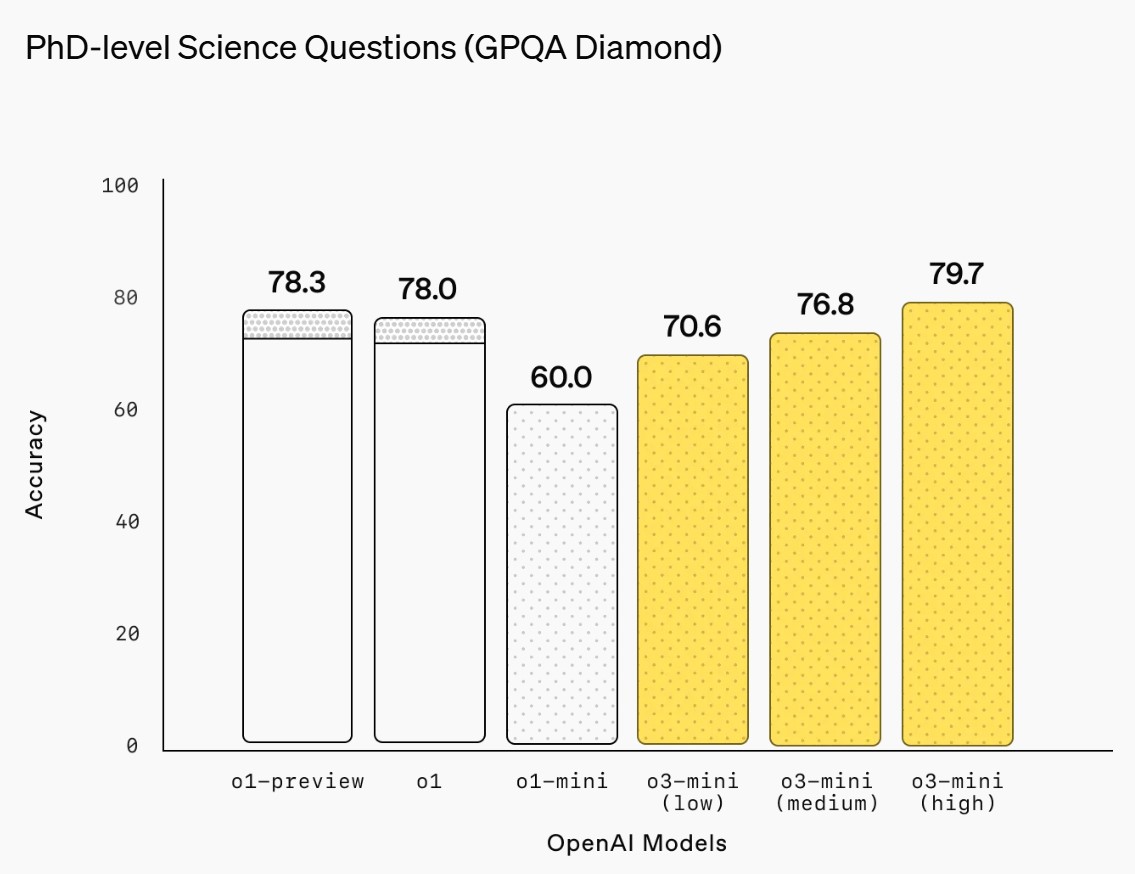
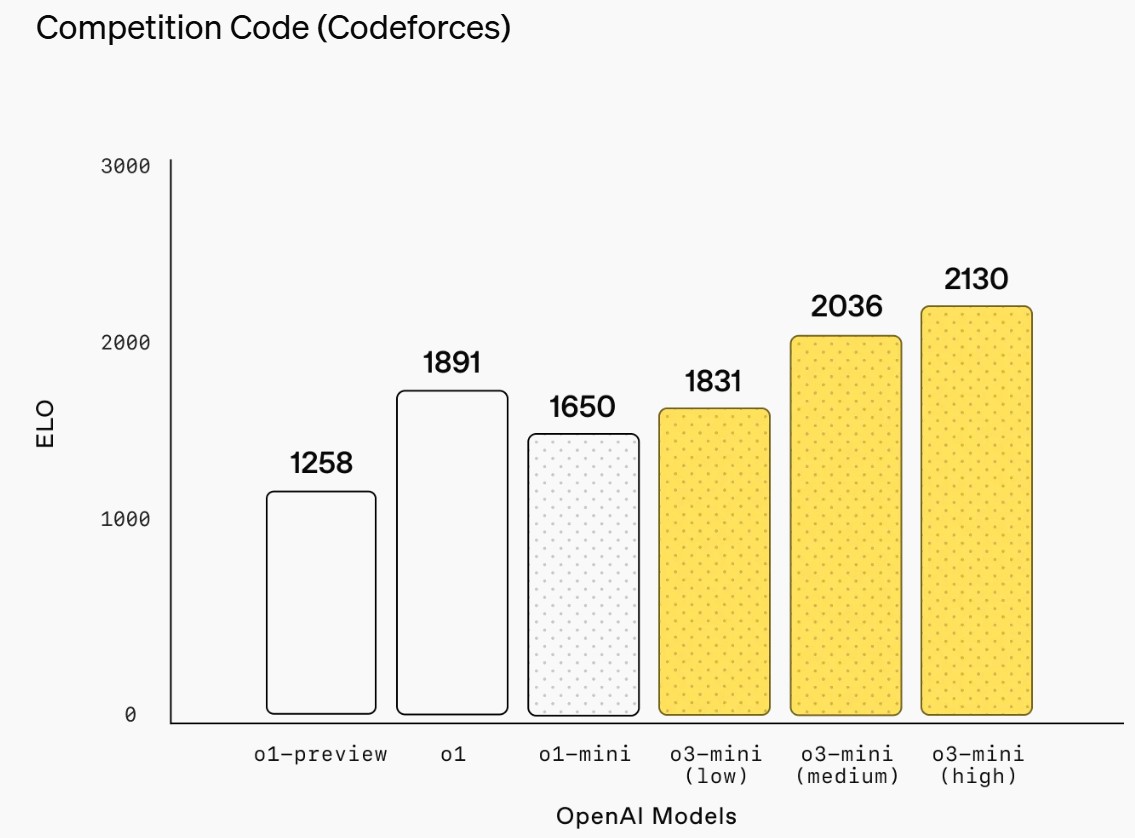
o3-mini does not support vision capabilities, so developers should continue using OpenAI o1 for visual reasoning tasks.
ChatGPT Plus, Team, and Pro users can access OpenAI o3-mini starting today, with Enterprise access coming in February. o3-mini will replace OpenAI o1-mini in the model picker, offering higher rate limits and lower latency, making it a compelling choice for coding, STEM, and logical problem-solving tasks.
As part of this upgrade, we’re tripling the rate limit for Plus and Team users from 50 messages per day with o1-mini to 150 messages per day with o3-mini.
Starting today, free plan users can also try OpenAI o3-mini by selecting ‘Reason’ in the message composer or by regenerating a response. This marks the first time a reasoning model has been made available to free users in ChatGPT.
Planning with partial observation is a central challenge in embodied AI. A majority of prior works have tackled this challenge by developing agents that physically explore their environment to update their beliefs about the world state. However, humans can imagine unseen parts of the world through a mental exploration and revise their beliefs with imagined observations. Such updated beliefs can allow them to make more informed decisions at the current step, without having to physically explore the world first. To achieve this human-like ability, we introduce the Generative World Explorer (Genex), a video generation model that allows an agent to mentally explore a large-scale 3D world (e.g., urban scenes) and acquire imagined observations to update its belief about the world .
🔸 Gaussian Splats: imagine throwing thousands of tiny ellipsoidal paint drops. They overlap, blend, and create a smooth, photorealistic look. Fast, great for visualization, but less structured for measurements.
🔸 Point Clouds: every dot is a measured hit. LiDAR or photogrammetry gives us millions of them forming a constellation of reality. Amazing for accuracy, but they don’t connect the dots out of the box.
🔸 Meshes: take those points, connect them into triangles, and you get very realistic surfaces. Strong for 3D analysis, simulation as continues watertight models.
“Simon Willison created a Datasette browser to explore WebVid-10M, one of the two datasets used to train the video generation model, and quickly learned that all 10.7 million video clips were scraped from Shutterstock, watermarks and all.”
“In addition to the Shutterstock clips, Meta also used 10 million video clips from this 100M video dataset from Microsoft Research Asia. It’s not mentioned on their GitHub, but if you dig into the paper, you learn that every clip came from over 3 million YouTube videos.”
“It’s become standard practice for technology companies working with AI to commercially use datasets and models collected and trained by non-commercial research entities like universities or non-profits.”
“Like with the artists, photographers, and other creators found in the 2.3 billion images that trained Stable Diffusion, I can’t help but wonder how the creators of those 3 million YouTube videos feel about Meta using their work to train their new model.”