



BREAKING NEWS
LATEST POSTS
-
Seaweed APT – Diffusion Adversarial Post-Training for One-Step Video Generation
https://cdn.seaweed-apt.com/assets/showreel/seaweed-apt.mp4
This demonstrate large-scale text-to-video generation with a single neural function evaluation (1NFE) by using our proposed adversarial post-training technique. Our model generates 2 seconds of 1280×720 24fps videos in real-time

-
Pyper – a flexible framework for concurrent and parallel data-processing in Python
Pyper is a flexible framework for concurrent and parallel data-processing, based on functional programming patterns.
https://github.com/pyper-dev/pyper

-
Jacob Bartlett – Apple is Killing Swift
https://blog.jacobstechtavern.com/p/apple-is-killing-swift
Jacob Bartlett argues that Swift, once envisioned as a simple and composable programming language by its creator Chris Lattner, has become overly complex due to Apple’s governance. Bartlett highlights that Swift now contains 217 reserved keywords, deviating from its original goal of simplicity. He contrasts Swift’s governance model, where Apple serves as the project lead and arbiter, with other languages like Python and Rust, which have more community-driven or balanced governance structures. Bartlett suggests that Apple’s control has led to Swift’s current state, moving away from Lattner’s initial vision.

-
Don’t Splat your Gaussians – Volumetric Ray-Traced Primitives for Modeling and Rendering Scattering and Emissive Media
https://arcanous98.github.io/projectPages/gaussianVolumes.html
We propose a compact and efficient alternative to existing volumetric representations for rendering such as voxel grids.

-
IPAdapter – Text Compatible Image Prompt Adapter for Text-to-Image Image-to-Image Diffusion Models and ComfyUI implementation
github.com/tencent-ailab/IP-Adapter
The IPAdapter are very powerful models for image-to-image conditioning. The subject or even just the style of the reference image(s) can be easily transferred to a generation. Think of it as a 1-image lora. They are an effective and lightweight adapter to achieve image prompt capability for the pre-trained text-to-image diffusion models. An IP-Adapter with only 22M parameters can achieve comparable or even better performance to a fine-tuned image prompt model.
Once the IP-Adapter is trained, it can be directly reusable on custom models fine-tuned from the same base model.The IP-Adapter is fully compatible with existing controllable tools, e.g., ControlNet and T2I-Adapter.

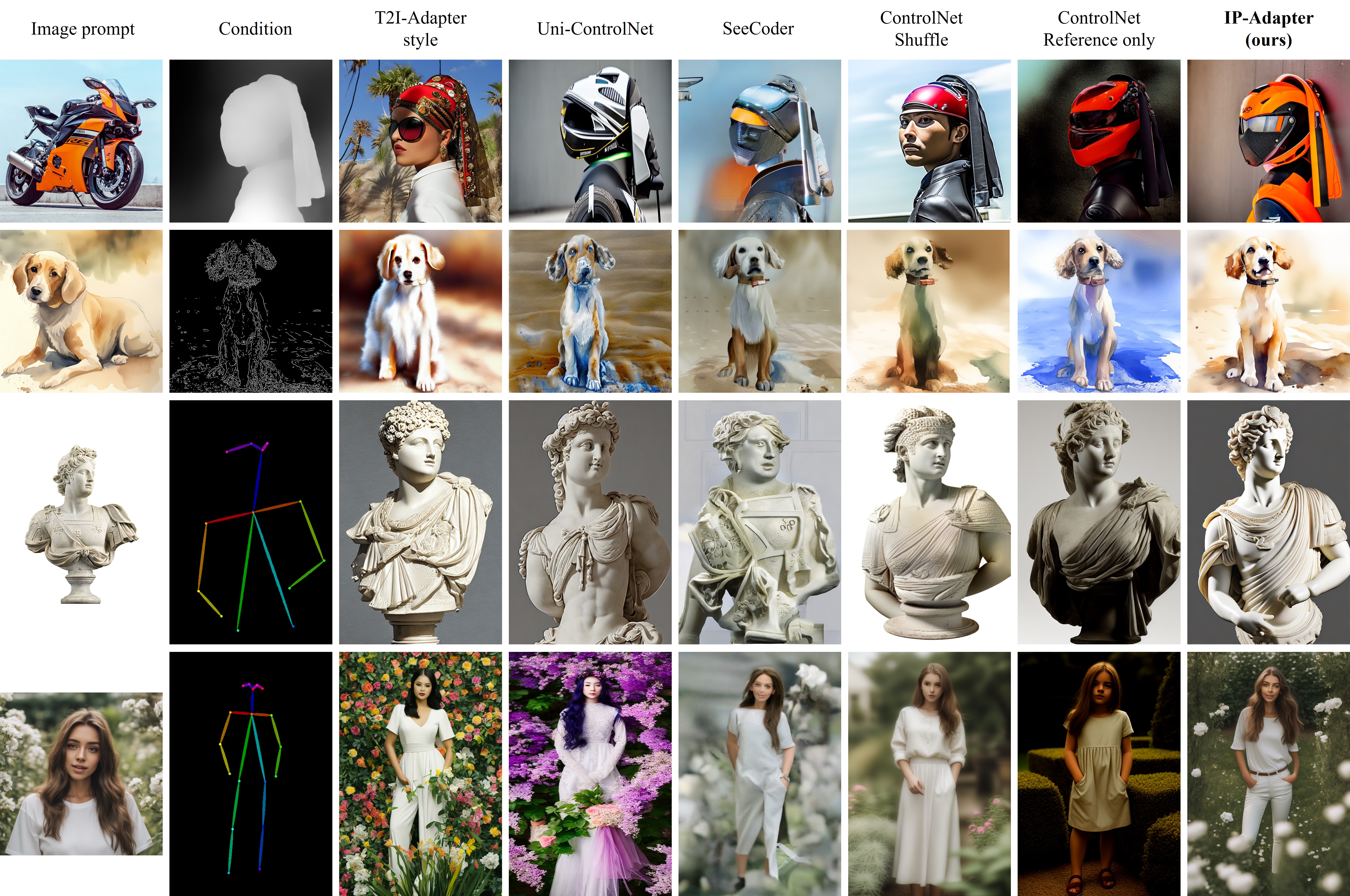
-
SPAR3D – Stable Point-Aware Reconstruction of 3D Objects from Single Images
SPAR3D is a fast single-image 3D reconstructor with intermediate point cloud generation, which allows for interactive user edits and achieves state-of-the-art performance.
https://github.com/Stability-AI/stable-point-aware-3d
https://stability.ai/news/stable-point-aware-3d?utm_source=x&utm_medium=social&utm_campaign=SPAR3D

-
MiniMax-01 goes open source
MiniMax is thrilled to announce the release of the MiniMax-01 series, featuring two groundbreaking models:
MiniMax-Text-01: A foundational language model.
MiniMax-VL-01: A visual multi-modal model.Both models are now open-source, paving the way for innovation and accessibility in AI development!
🔑 Key Innovations
1. Lightning Attention Architecture: Combines 7/8 Lightning Attention with 1/8 Softmax Attention, delivering unparalleled performance.
2. Massive Scale with MoE (Mixture of Experts): 456B parameters with 32 experts and 45.9B activated parameters.
3. 4M-Token Context Window: Processes up to 4 million tokens, 20–32x the capacity of leading models, redefining what’s possible in long-context AI applications.💡 Why MiniMax-01 Matters
1. Innovative Architecture for Top-Tier Performance
The MiniMax-01 series introduces the Lightning Attention mechanism, a bold alternative to traditional Transformer architectures, delivering unmatched efficiency and scalability.2. 4M Ultra-Long Context: Ushering in the AI Agent Era
With the ability to handle 4 million tokens, MiniMax-01 is designed to lead the next wave of agent-based applications, where extended context handling and sustained memory are critical.3. Unbeatable Cost-Effectiveness
Through proprietary architectural innovations and infrastructure optimization, we’re offering the most competitive pricing in the industry:
$0.2 per million input tokens
$1.1 per million output tokens🌟 Experience the Future of AI Today
We believe MiniMax-01 is poised to transform AI applications across industries. Whether you’re building next-gen AI agents, tackling ultra-long context tasks, or exploring new frontiers in AI, MiniMax-01 is here to empower your vision.✅ Try it now for free: hailuo.ai
📄 Read the technical paper: filecdn.minimax.chat/_Arxiv_MiniMax_01_Report.pdf
🌐 Learn more: minimaxi.com/en/news/minimax-01-series-2
💡API Platform: intl.minimaxi.com/












FEATURED POSTS




-
Photography basics: Lumens vs Candelas (candle) vs Lux vs FootCandle vs Watts vs Irradiance vs Illuminance
https://www.translatorscafe.com/unit-converter/en-US/illumination/1-11/

The power output of a light source is measured using the unit of watts W. This is a direct measure to calculate how much power the light is going to drain from your socket and it is not relatable to the light brightness itself.
The amount of energy emitted from it per second. That energy comes out in a form of photons which we can crudely represent with rays of light coming out of the source. The higher the power the more rays emitted from the source in a unit of time.
Not all energy emitted is visible to the human eye, so we often rely on photometric measurements, which takes in account the sensitivity of human eye to different wavelenghts


Details in the post
(more…)


