



BREAKING NEWS
LATEST POSTS
-
ByteDance Seedream 4.0 – Super‑fast, 4K, multi image support
https://seed.bytedance.com/en/seedream4_0
➤ Super‑fast, high‑resolution results : resolutions up to 4K, producing a 2K image in less than 1.8 seconds, all while maintining sharpness and realism.
➤ At 4K, cost as low as 0.03 $ per generation.
➤ Natural‑language editing – You can instruct the model to “remove the people in the background,” “add a helmet” or “replace this with that,” and it executes without needing complicated prompts.
➤ Multi‑image input and output – It can combine multiple images, transfer styles and produce storyboards or series with consistent characters and themes.

-
OpenAI Backs Critterz, an AI-Made Animated Feature Film
https://www.wsj.com/tech/ai/openai-backs-ai-made-animated-feature-film-389f70b0
Film, called ‘Critterz,’ aims to debut at Cannes Film Festival and will leverage startup’s AI tools and resources.
“Critterz,” about forest creatures who go on an adventure after their village is disrupted by a stranger, is the brainchild of Chad Nelson, a creative specialist at OpenAI. Nelson started sketching out the characters three years ago while trying to make a short film with what was then OpenAI’s new DALL-E image-generation tool.
-
AI and the Law: Anthropic to Pay $1.5 Billion to Settle Book Piracy Class Action Lawsuit
https://variety.com/2025/digital/news/anthropic-class-action-settlement-billion-1236509571
The settlement amounts to about $3,000 per book and is believed to be the largest ever recovery in a U.S. copyright case, according to the plaintiffs’ attorneys.

-
Sir Peter Jackson’s Wētā FX records $140m loss in two years, amid staff layoffs
https://www.thepost.co.nz/business/360813799/weta-fx-posts-59m-loss-amid-industry-headwinds
Wētā FX, Sir Peter Jackson’s largest business has posted a $59.3 million loss for the year to March 31, an improvement on an $83m loss last year.

-
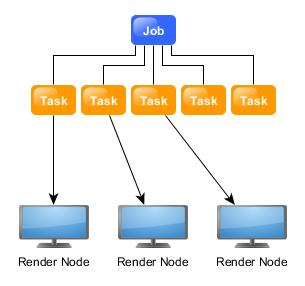
ComfyUI Thinkbox Deadline plugin
Submit ComfyUI workflows to Thinkbox Deadline render farm.
Features
- Submit ComfyUI workflows directly to Deadline
- Batch rendering with seed variation
- Real-time progress monitoring via Deadline Monitor
- Configurable pools, groups, and priorities
https://github.com/doubletwisted/ComfyUI-Deadline-Plugin
https://docs.thinkboxsoftware.com/products/deadline/latest/1_User%20Manual/manual/overview.html
Deadline 10 is a cross-platform render farm management tool for Windows, Linux, and macOS. It gives users control of their rendering resources and can be used on-premises, in the cloud, or both. It handles asset syncing to the cloud, manages data transfers, and supports tagging for cost tracking purposes.
Deadline 10’s Remote Connection Server allows for communication over HTTPS, improving performance and scalability. Where supported, users can use usage-based licensing to supplement their existing fixed pool of software licenses when rendering through Deadline 10.
-
Google’s Nano Banana AI: Free Tool for 3D Architecture Models
https://landscapearchitecture.store/blogs/news/nano-banana-ai-free-tool-for-3d-architecture-models



How to Use Nano Banana AI for Architecture- Go to Google AI Studio.
- Log in with your Gmail and select Gemini 2.5 (Nano Banana).
- Upload a photo — either from your laptop or a Google Street View screenshot.
- Paste this example prompt:
“Use the provided architectural photo as reference. Generate a high-fidelity 3D building model in the look of a 3D-printed architecture model.” - Wait a few seconds, and your 3D architecture model will be ready.
Pro tip: If you want more accuracy, upload two images — a street photo for the facade and an aerial view for the roof/top.








FEATURED POSTS

-
Generative Detail Enhancement for Physically Based Materials
https://arxiv.org/html/2502.13994v1
https://arxiv.org/pdf/2502.13994
A tool for enhancing the detail of physically based materials using an off-the-shelf diffusion model and inverse rendering.

-
About color: What is a LUT
http://www.lightillusion.com/luts.html
https://www.shutterstock.com/blog/how-use-luts-color-grading
A LUT (Lookup Table) is essentially the modifier between two images, the original image and the displayed image, based on a mathematical formula. Basically conversion matrices of different complexities. There are different types of LUTS – viewing, transform, calibration, 1D and 3D.


-
AnimationXpress.com interviews Daniele Tosti for TheCgCareer.com channel

You’ve been in the VFX Industry for over a decade. Tell us about your journey.
It all started with my older brother giving me a Commodore64 personal computer as a gift back in the late 80′. I realised then I could create something directly from my imagination using this new digital media format. And, eventually, make a living in the process.
That led me to start my professional career in 1990. From live TV to games to animation. All the way to live action VFX in the recent years.I really never stopped to crave to create art since those early days. And I have been incredibly fortunate to work with really great talent along the way, which made my journey so much more effective.
What inspired you to pursue VFX as a career?
An incredible combination of opportunities, really. The opportunity to express myself as an artist and earn money in the process. The opportunity to learn about how the world around us works and how best solve problems. The opportunity to share my time with other talented people with similar passions. The opportunity to grow and adapt to new challenges. The opportunity to develop something that was never done before. A perfect storm of creativity that fed my continuous curiosity about life and genuinely drove my inspiration.
Tell us about the projects you’ve particularly enjoyed working on in your career
(more…)



{kind=link}
-
Ethan Roffler interviews CG Supervisor Daniele Tosti
Ethan Roffler
I recently had the honor of interviewing this VFX genius and gained great insight into what it takes to work in the entertainment industry. Keep in mind, these questions are coming from an artist’s perspective but can be applied to any creative individual looking for some wisdom from a professional. So grab a drink, sit back, and enjoy this fun and insightful conversation.
Ethan
To start, I just wanted to say thank you so much for taking the time for this interview!Daniele
My pleasure.
When I started my career I struggled to find help. Even people in the industry at the time were not that helpful. Because of that, I decided very early on that I was going to do exactly the opposite. I spend most of my weekends talking or helping students. ;)Ethan
(more…)
That’s awesome! I have also come across the same struggle! Just a heads up, this will probably be the most informal interview you’ll ever have haha! Okay, so let’s start with a small introduction!