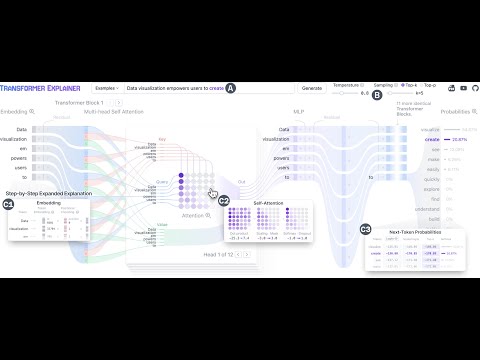
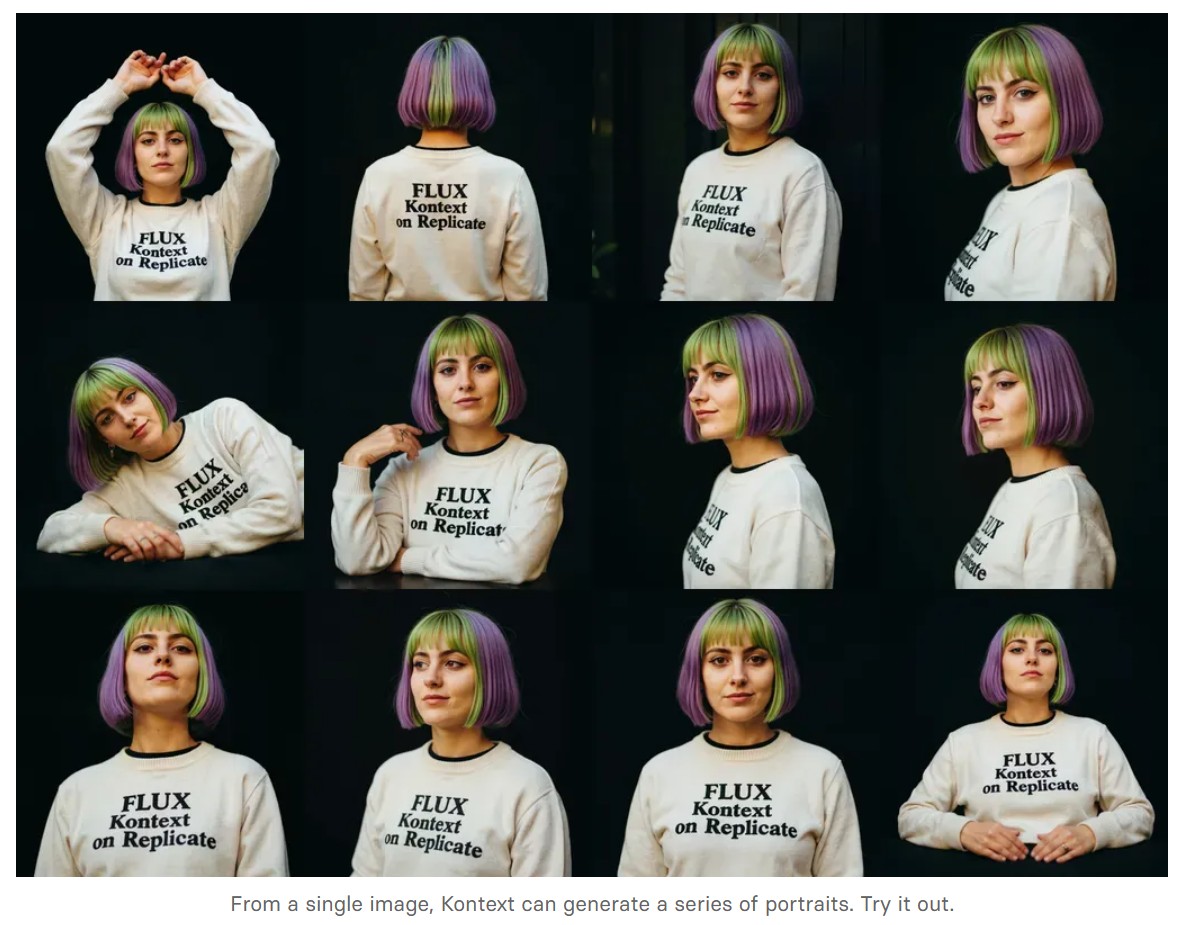Transformer Explainer is an interactive visualization tool designed to help anyone learn how Transformer-based models like GPT work. It runs a live GPT-2 model right in your browser, allowing you to experiment with your own text and observe in real time how internal components and operations of the Transformer work together to predict the next tokens. Try Transformer Explainer at http://poloclub.github.io/transformer-explainer
If you prompt for a 360° video in VEO (like literally write “360°” ) it can generate a Monoscopic 360 video, then the next step is to inject the right metadata in your file so you can play it as an actual 360 video. Once it’s saved with the right Metadata, it will be recognized as an actual 360/VR video, meaning you can just play it in VLC and drag your mouse to look around.
There are three models, two are available now, and a third open-weight version is coming soon:
FLUX.1 Kontext [pro]: State-of-the-art performance for image editing. High-quality outputs, great prompt following, and consistent results.
FLUX.1 Kontext [max]: A premium model that brings maximum performance, improved prompt adherence, and high-quality typography generation without compromise on speed.
Coming soon: FLUX.1 Kontext [dev]: An open-weight, guidance-distilled version of Kontext.
We’re so excited with what Kontext can do, we’ve created a collection of models on Replicate to give you ideas:
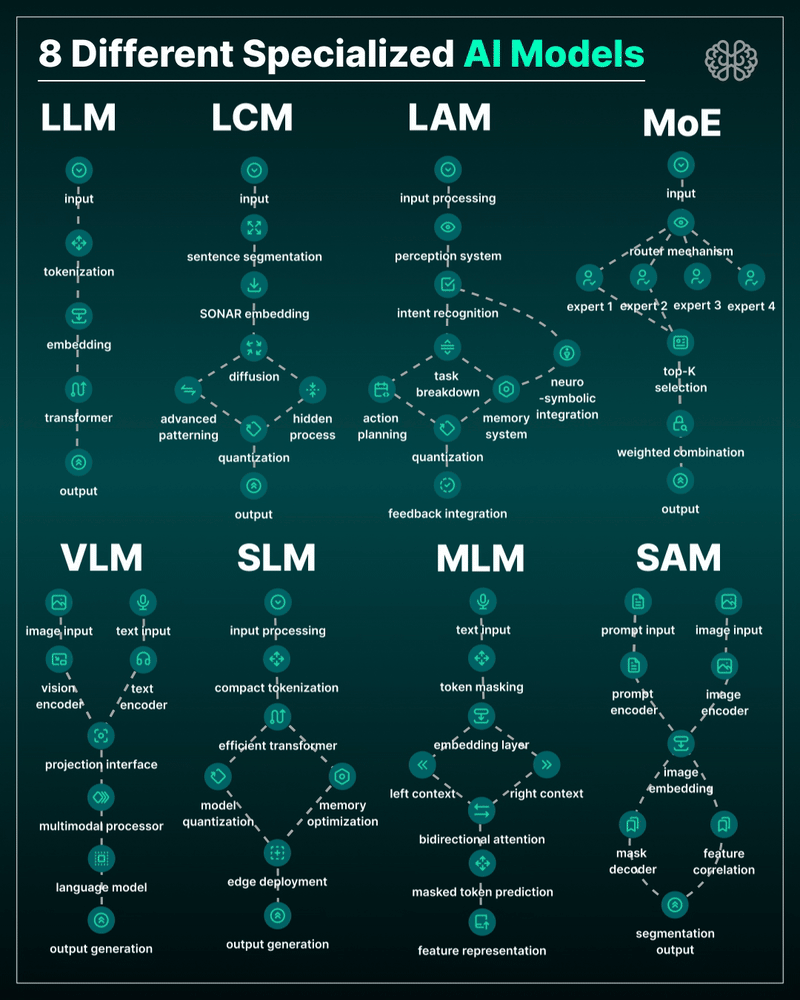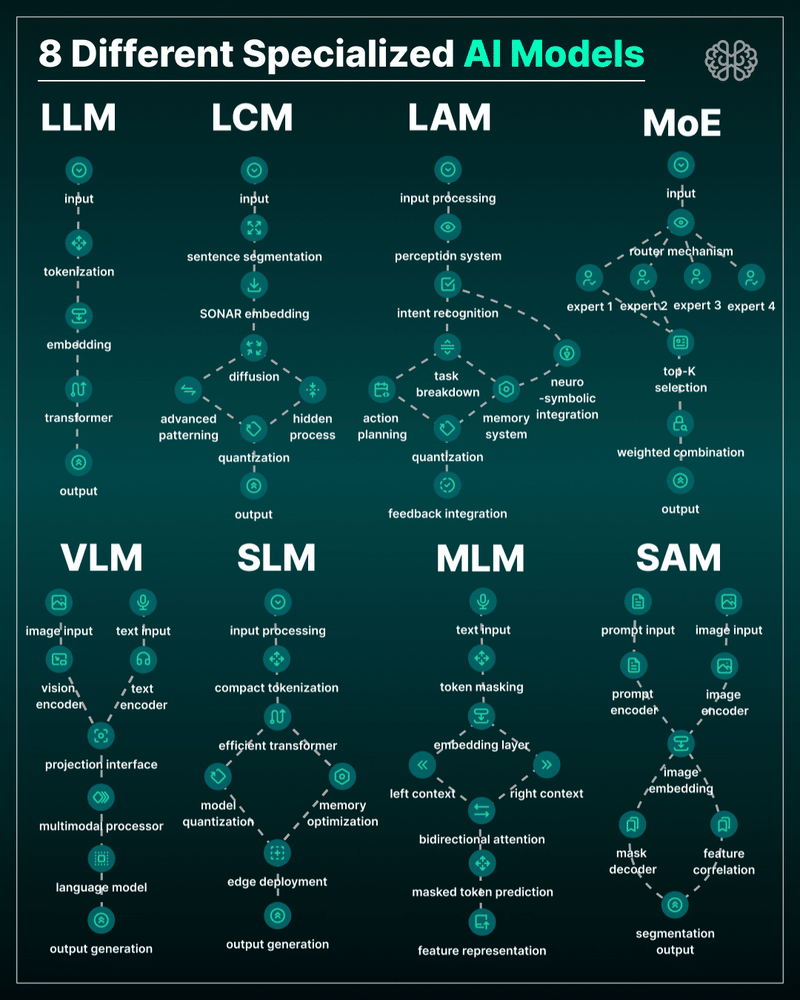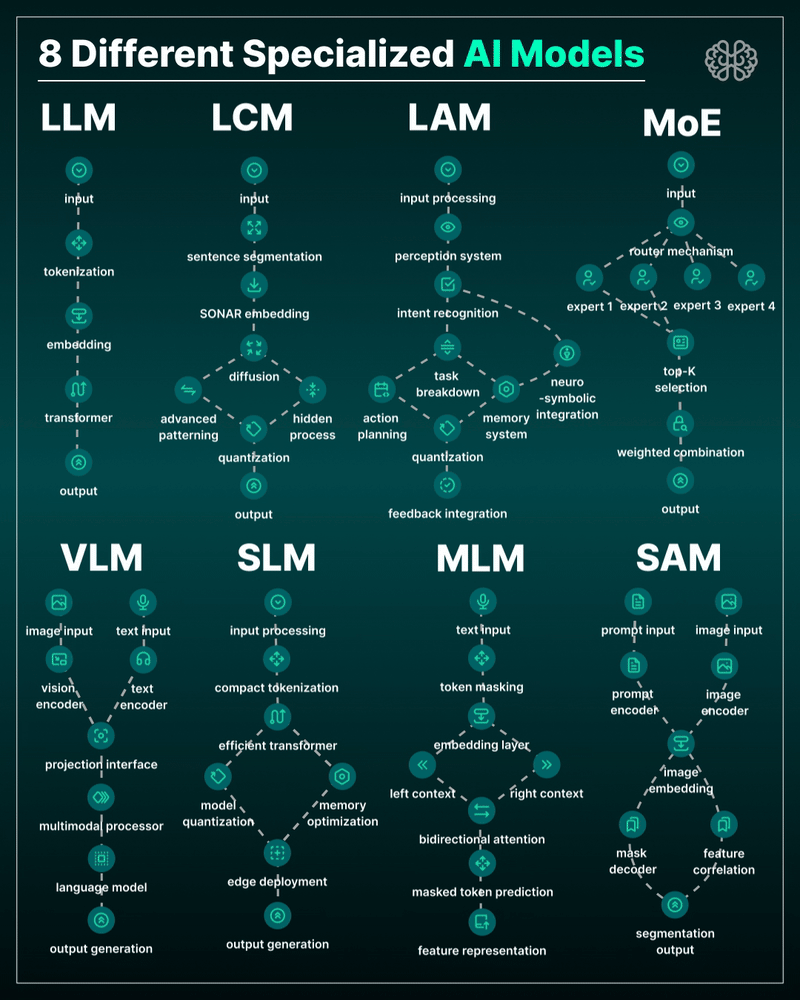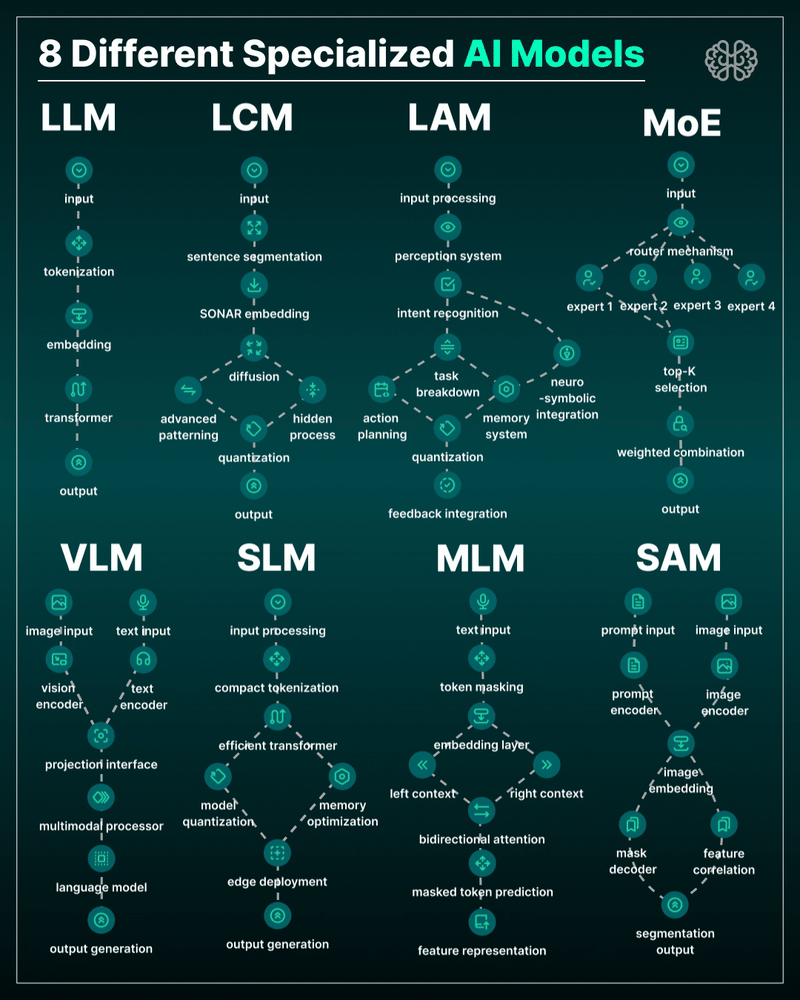
the 8 most important model types and what they’re actually built to do: ⬇️
1. 𝗟𝗟𝗠 – 𝗟𝗮𝗿𝗴𝗲 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹 → Your ChatGPT-style model. Handles text, predicts the next token, and powers 90% of GenAI hype. 🛠 Use case: content, code, convos.
2. 𝗟𝗖𝗠 – 𝗟𝗮𝘁𝗲𝗻𝘁 𝗖𝗼𝗻𝘀𝗶𝘀𝘁𝗲𝗻𝗰𝘆 𝗠𝗼𝗱𝗲𝗹 → Lightweight, diffusion-style models. Fast, quantized, and efficient — perfect for real-time or edge deployment. 🛠 Use case: image generation, optimized inference.
3. 𝗟𝗔𝗠 – 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗔𝗰𝘁𝗶𝗼𝗻 𝗠𝗼𝗱𝗲𝗹 → Where LLM meets planning. Adds memory, task breakdown, and intent recognition. 🛠 Use case: AI agents, tool use, step-by-step execution.
4. 𝗠𝗼𝗘 – 𝗠𝗶𝘅𝘁𝘂𝗿𝗲 𝗼𝗳 𝗘𝘅𝗽𝗲𝗿𝘁𝘀 → One model, many minds. Routes input to the right “expert” model slice — dynamic, scalable, efficient. 🛠 Use case: high-performance model serving at low compute cost.
5. 𝗩𝗟𝗠 – 𝗩𝗶𝘀𝗶𝗼𝗻 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹 → Multimodal beast. Combines image + text understanding via shared embeddings. 🛠 Use case: Gemini, GPT-4o, search, robotics, assistive tech.
6. 𝗦𝗟𝗠 – 𝗦𝗺𝗮𝗹𝗹 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹 → Tiny but mighty. Designed for edge use, fast inference, low latency, efficient memory. 🛠 Use case: on-device AI, chatbots, privacy-first GenAI.
7. 𝗠𝗟𝗠 – 𝗠𝗮𝘀𝗸𝗲𝗱 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹 → The OG foundation model. Predicts masked tokens using bidirectional context. 🛠 Use case: search, classification, embeddings, pretraining.
8. 𝗦𝗔𝗠 – 𝗦𝗲𝗴𝗺𝗲𝗻𝘁 𝗔𝗻𝘆𝘁𝗵𝗶𝗻𝗴 𝗠𝗼𝗱𝗲𝗹 → Vision model for pixel-level understanding. Highlights, segments, and understands *everything* in an image. 🛠 Use case: medical imaging, AR, robotics, visual agents.
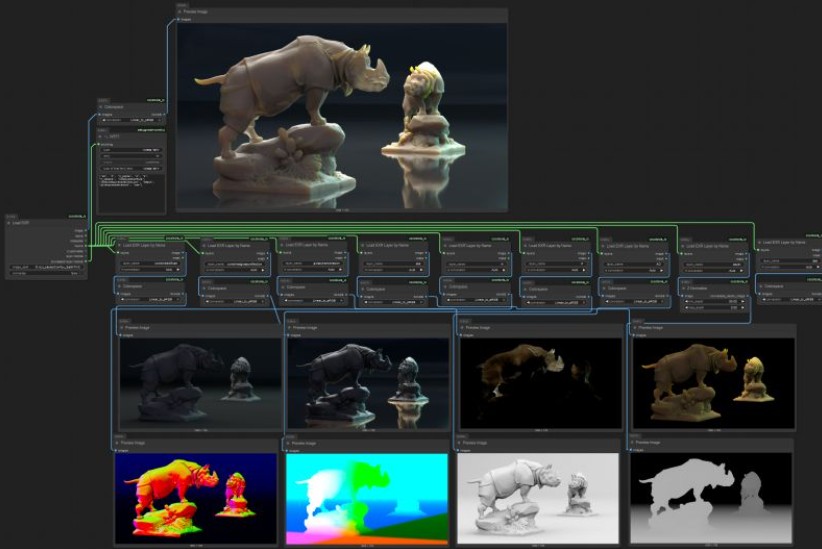
Finn Jäger has spent some time in making a sleeker tool for all you VFX nerds out there, it takes a HEIC iPhone still and exports a Multichannel EXR – the cool thing is it also converts it to acesCG and it merges the SDR base image with the gain map according to apples math hdr_rgb = sdr_rgb * (1.0 + (headroom – 1.0) * gainmap)
Note. The Median Cut algorithm is typically used for color quantization, which involves reducing the number of colors in an image while preserving its visual quality. It doesn’t directly provide a way to identify the brightest areas in an image. However, if you’re interested in identifying the brightest areas, you might want to look into other methods like thresholding, histogram analysis, or edge detection, through openCV for example.