



BREAKING NEWS
LATEST POSTS
-
Deep Compositing in Nuke – a walkthrough

Depth Map: A depth map is a representation of the distance or depth information for each pixel in a scene. It is typically a two-dimensional array where each pixel contains a value that represents the distance from the camera to the corresponding point in the scene. The depth values are usually represented in metric units, such as meters. A depth map provides a continuous representation of the scene’s depth information.
For example, in Arnold this is achieved through a Z AOV, this collects depth of the shading points as seen from the camera.
(more…)
https://help.autodesk.com/view/ARNOL/ENU/?guid=arnold_user_guide_ac_output_aovs_ac_aovs_html
https://help.autodesk.com/view/ARNOL/ENU/?guid=arnold_for_3ds_max_ax_aov_tutorials_ax_zdepth_aov_html -
VFX Giant MPC and Parent Company Technicolor Shut Down Amid ‘Severe Financial Challenges
https://variety.com/2025/film/global/technicolor-vfx-mpc-shutter-severe-challenges-1236316354
Shaun Severi, Head of Creative Production at the Mill, claimed in a LinkedIn post that 4,500 had lost their jobs in 24 hours: “The problem wasn’t talent or execution — it was mismanagement at the highest levels…the incompetence at the top was nothing short of disastrous.”
According to Severi, successive company presidents “buried the company under massive debt by acquiring VFX Studios…the second president, after a disastrous merger of the post houses, took us public, artificially inflating the company’s value — only for it to come crashing down when the real numbers were revealed….and the third and final president, who came from a car rental company, had no vision of what she was building, selling or managing.”

-
Moondream Gaze Detection – Open source code
This is convenient for captioning videos, understanding social dynamics, and for specific cases such as sports analytics, or detecting when drivers or operators are distracted.
https://huggingface.co/spaces/moondream/gaze-demo
https://moondream.ai/blog/announcing-gaze-detection

-
X-Dyna – Expressive Dynamic Human Image Animation
https://x-dyna.github.io/xdyna.github.io
A novel zero-shot, diffusion-based pipeline for animating a single human image using facial expressions and body movements derived from a driving video, that generates realistic, context-aware dynamics for both the subject and the surrounding environment.

-
Flex 1 Alpha – a pre-trained base 8 billion parameter rectified flow transformer
https://huggingface.co/ostris/Flex.1-alpha
Flex.1 started as the FLUX.1-schnell-training-adapter to make training LoRAs on FLUX.1-schnell possible.

-
Generative Detail Enhancement for Physically Based Materials
https://arxiv.org/html/2502.13994v1
https://arxiv.org/pdf/2502.13994
A tool for enhancing the detail of physically based materials using an off-the-shelf diffusion model and inverse rendering.

-
Camera Metadata Toolkit (camdkit) for Virtual Production
https://github.com/SMPTE/ris-osvp-metadata-camdkit
Today
camdkitsupports mapping (or importing, if you will) of metadata from five popular digital cinema cameras into a canonical form; it also supports a mapping of the metadata defined in the F4 protocol used by tracking system components from Mo-Sys.
-
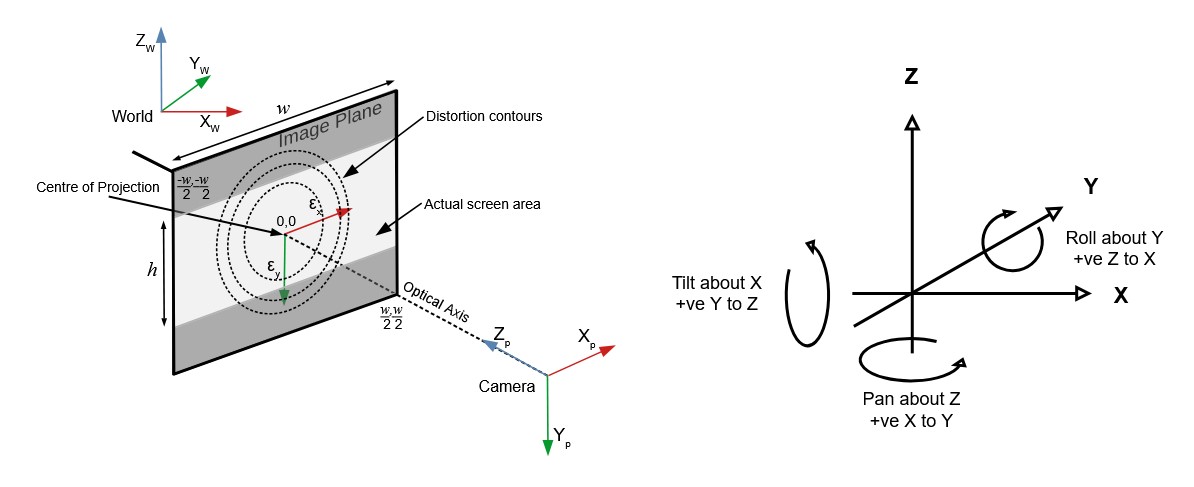
OpenTrackIO – free and open-source protocol designed to improve interoperability in Virtual Production
OpenTrackIO defines the schema of JSON samples that contain a wide range of metadata about the device, its transform(s), associated camera and lens. The full schema is given below and can be downloaded here.
-
Martin Gent – Comparing current video AI models
https://www.linkedin.com/posts/martingent_imagineapp-veo2-kling-activity-7298979787962806272-n0Sn
🔹 𝗩𝗲𝗼 2 – After the legendary prompt adherence of Veo 2 T2V, I have to say I2V is a little disappointing, especially when it comes to camera moves. You often get those Sora-like jump-cuts too which can be annoying.
🔹 𝗞𝗹𝗶𝗻𝗴 1.6 Pro – Still the one to beat for I2V, both for image quality and prompt adherence. It’s also a lot cheaper than Veo 2. Generations can be slow, but are usually worth the wait.
🔹 𝗥𝘂𝗻𝘄𝗮𝘆 Gen 3 – Useful for certain shots, but overdue an update. The worst performer here by some margin. Bring on Gen 4!
🔹 𝗟𝘂𝗺𝗮 Ray 2 – I love the energy and inventiveness Ray 2 brings, but those came with some image quality issues. I want to test more with this model though for sure.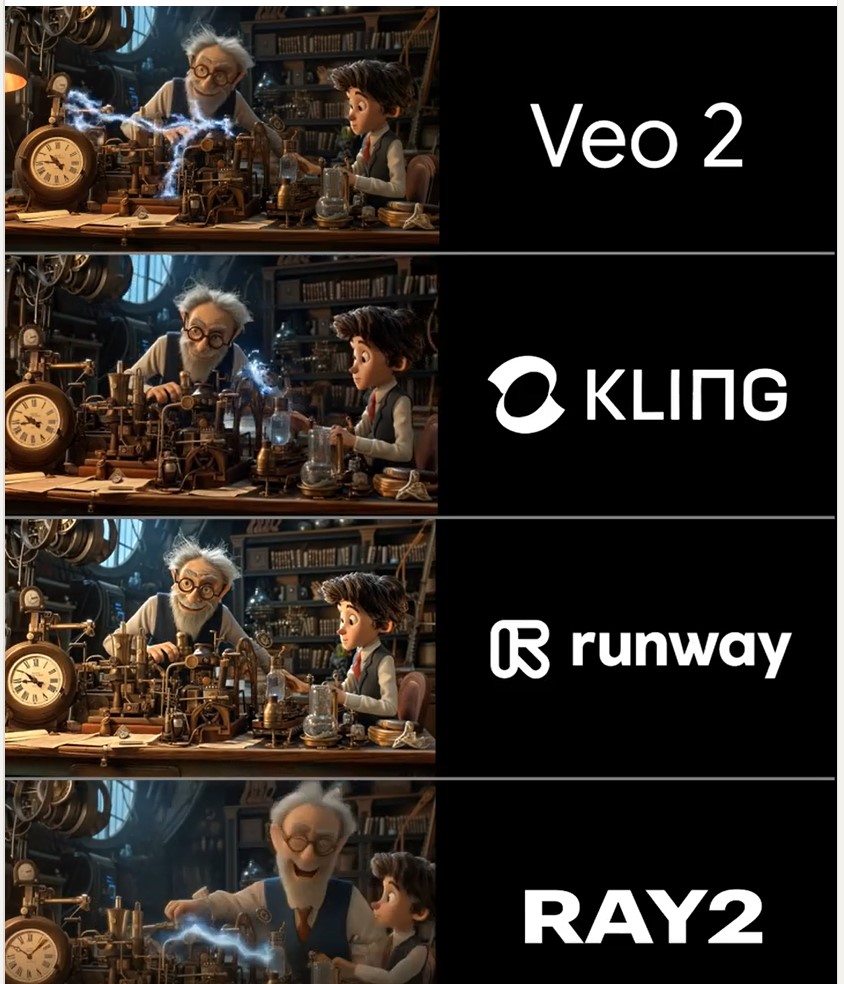



FEATURED POSTS


-
Google – Artificial Intelligence free courses
1. Introduction to Large Language Models: Learn about the use cases and how to enhance the performance of large language models.
https://www.cloudskillsboost.google/course_templates/5392. Introduction to Generative AI: Discover the differences between Generative AI and traditional machine learning methods.
https://www.cloudskillsboost.google/course_templates/5363. Generative AI Fundamentals: Earn a skill badge by demonstrating your understanding of foundational concepts in Generative AI.
https://www.cloudskillsboost.google/paths4. Introduction to Responsible AI: Learn about the importance of Responsible AI and how Google implements it in its products.
https://www.cloudskillsboost.google/course_templates/5545. Encoder-Decoder Architecture: Learn about the encoder-decoder architecture, a critical component of machine learning for sequence-to-sequence tasks.
https://www.cloudskillsboost.google/course_templates/5436. Introduction to Image Generation: Discover diffusion models, a promising family of machine learning models in the image generation space.
https://www.cloudskillsboost.google/course_templates/5417. Transformer Models and BERT Model: Get a comprehensive introduction to the Transformer architecture and the Bidirectional Encoder Representations from the Transformers (BERT) model.
https://www.cloudskillsboost.google/course_templates/5388. Attention Mechanism: Learn about the attention mechanism, which allows neural networks to focus on specific parts of an input sequence.
https://www.cloudskillsboost.google/course_templates/537







-
Composition – cinematography Cheat Sheet

Where is our eye attracted first? Why?
Size. Focus. Lighting. Color.
Size. Mr. White (Harvey Keitel) on the right.
Focus. He’s one of the two objects in focus.
Lighting. Mr. White is large and in focus and Mr. Pink (Steve Buscemi) is highlighted by
a shaft of light.
Color. Both are black and white but the read on Mr. White’s shirt now really stands out.
(more…)
What type of lighting?