



BREAKING NEWS
LATEST POSTS
-
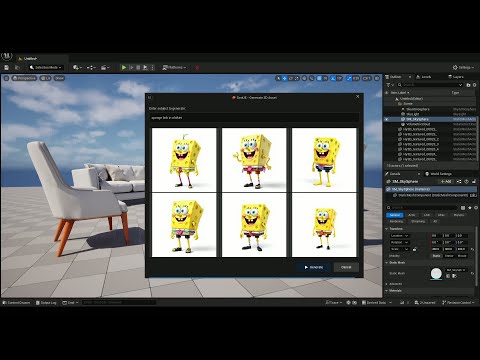
GenUE – Direct Prompt-to-Mesh Generation in Unreal Engine Integrated with ComfyUI
GenUE brings prompt-driven 3D asset creation directly into Unreal Engine using ComfyUI as a flexible backend. • Generate high-quality images from text prompts. • Choose from a catalog of batch-generated images – no style limitations. • Convert the selected image to a fully textured 3D mesh. • Automatically import and place the model into your Unreal Engine scene. This modular pipeline gives you full control over the image and 3D generation stages, with support for any ComfyUI workflow or model. Full generation (image + mesh + import) completes in under 2 minutes on a high-end consumer GPU.
-
Edward Ureña – Rig creator
https://edwardurena.gumroad.com/l/ramoo
What it offers:
• Base rigs for multiple character types
• Automatic weight application
• Built-in facial rigging system
• Bone generators with FK and IK options
• Streamlined constraint panel
-
GPT-Image-1 API now available through ComfyUI with Dall-E integration
https://blog.comfy.org/p/comfyui-now-supports-gpt-image-1
https://docs.comfy.org/tutorials/api-nodes/openai/gpt-image-1
https://openai.com/index/image-generation-api
• Prompt GPT-Image-1 directly in ComfyUI using text or image inputs
• Set resolution and quality
• Supports image editing + transparent backgrounds
• Seamlessly mix with local workflows like WAN 2.1, FLUX Tools, and more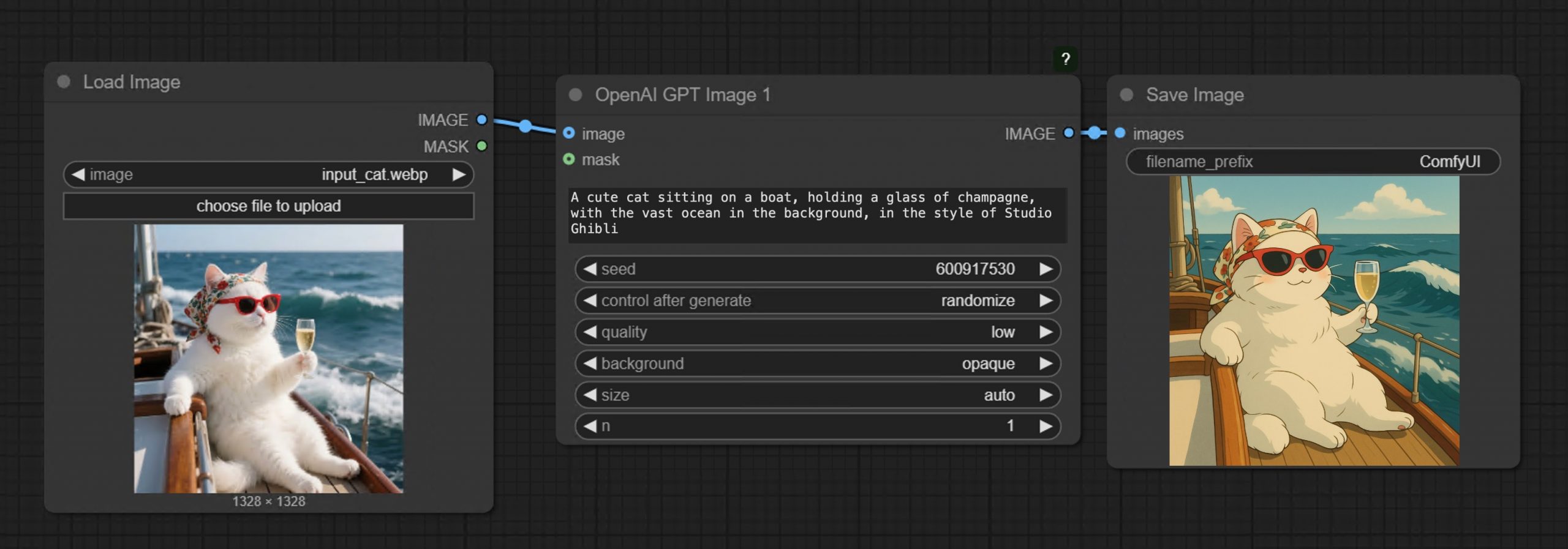
-
Tencent Hunyuan3D 2.5 – Transform images and text into 3D models with ultra-high-definition precision
What makes it special?
• Massive 10B parameter geometric model with 10x more mesh faces.
• High-quality textures with industry-first multi-view PBR generation.
• Optimized skeletal rigging for streamlined animation workflows.
• Flexible pipeline for text-to-3D and image-to-3D generation.
They’re making it accessible to everyone:
• Open-source code and pre-trained models.
• Easy-to-use API and intuitive web interface.
• Free daily quota doubled to 20 generations!
-
Alibaba 3DV-TON – A novel diffusion model for HQ and temporally consistent video
https://arxiv.org/pdf/2504.17414

Video try-on replaces clothing in videos with target garments. Existing methods struggle to generate high-quality and temporally consistent results when handling complex clothing patterns and diverse body poses. We present 3DV-TON, a novel diffusion-based framework for generating high-fidelity and temporally consistent video try-on results. Our approach employs generated animatable textured 3D meshes as explicit frame-level guidance, alleviating the issue of models over-focusing on appearance fidelity at the expanse of motion coherence. This is achieved by enabling direct reference to consistent garment texture movements throughout video sequences. The proposed method features an adaptive pipeline for generating dynamic 3D guidance: (1) selecting a keyframe for initial 2D image try-on, followed by (2) reconstructing and animating a textured 3D mesh synchronized with original video poses. We further introduce a robust rectangular masking strategy that successfully mitigates artifact propagation caused by leaking clothing information during dynamic human and garment movements. To advance video try-on research, we introduce HR-VVT, a high-resolution benchmark dataset containing 130 videos with diverse clothing types and scenarios. Quantitative and qualitative results demonstrate our superior performance over existing methods.
-
FramePack – Packing Input Frame Context in Next-Frame Prediction Models for Offline Video Generation With Low Resource Requirements
https://lllyasviel.github.io/frame_pack_gitpage/
- Diffuse thousands of frames at full fps-30 with 13B models using 6GB laptop GPU memory.
- Finetune 13B video model at batch size 64 on a single 8xA100/H100 node for personal/lab experiments.
- Personal RTX 4090 generates at speed 2.5 seconds/frame (unoptimized) or 1.5 seconds/frame (teacache).
- No timestep distillation.
- Video diffusion, but feels like image diffusion.

Image-to-5-Seconds (30fps, 150 frames)
-
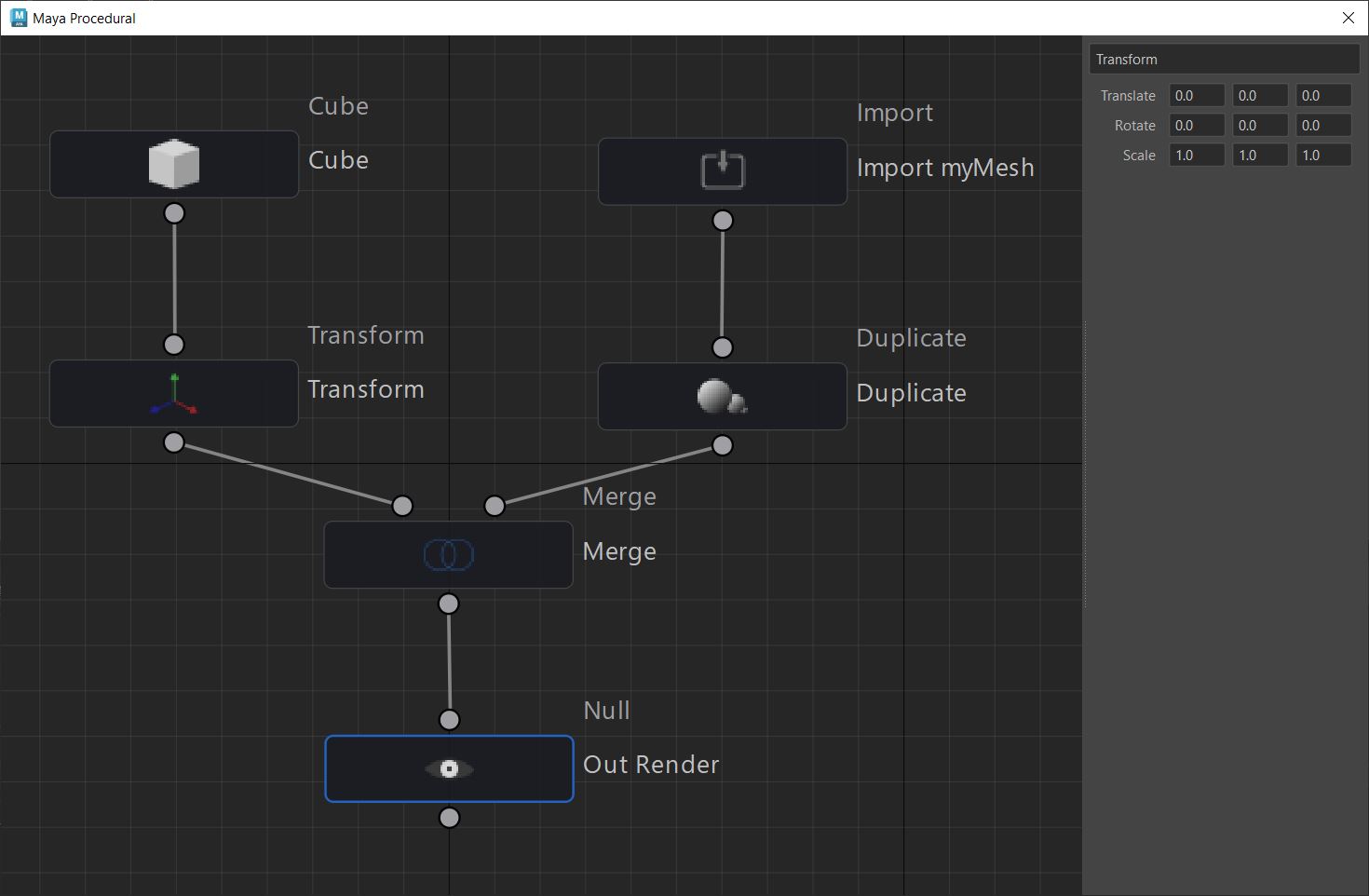
Anthony Sauzet – ProceduralMaya
A Maya script that introduces a node-based graph system for procedural modeling, like Houdini
https://github.com/AnthonySTZ/ProceduralMaya
-
11 Public Speaking Strategies

What do people report as their #1 greatest fear?
It’s not death….
It’s public speaking.
Glossophobia, the fear of public speaking, has been a daunting obstacle for me for years.
11 confidence-boosting tips
1/ The 5-5-5 Rule
→ Scan 5 faces; Hold each gaze for 5 seconds.
→ Repeat every 5 minutes.
→ Creates an authentic connection.
2/Power Pause
→ Dead silence for 3 seconds after key points.
→ Let your message land.
3/ The 3-Part Open
→ Hook with a question.
→ Share a story.
→ State your promise.
4/ Palm-Up Principle
→ Open palms when speaking = trustworthy.
→ Pointing fingers = confrontational.
5/ The 90-Second Reset
→ Feel nervous? Excuse yourself.
→ 90 seconds of deep breathing reset your nervous system.
6/ Rule of Three
→ Structure key points in threes.
→ Our brains love patterns.
7/ 2-Minute Story Rule
→ Keep stories under 2 minutes.
→ Any longer, you lose them.
8/ The Lighthouse Method
→ Plant “anchor points” around the room.
→ Rotate eye contact between them.
→ Looks natural, feels structured.
9/ The Power Position
→ Feet shoulder-width apart.
→ Hands relaxed at sides.
→ Projects confidence even when nervous.
10/ The Callback Technique
→ Reference earlier points later in your talk.
→ Creates a narrative thread.
→ Audiences love connections.
11/ The Rehearsal Truth
→ Practice the opening 3x more than the rest.
→ Nail the first 30 seconds; you’ll nail the talk. -
FreeCodeCamp – Train Your Own LLM
https://www.freecodecamp.org/news/train-your-own-llm
Ever wondered how large language models like ChatGPT are actually built? Behind these impressive AI tools lies a complex but fascinating process of data preparation, model training, and fine-tuning. While it might seem like something only experts with massive resources can do, it’s actually possible to learn how to build your own language model from scratch. And with the right guidance, you can go from loading raw text data to chatting with your very own AI assistant.

-
Alibaba FloraFauna.ai – AI Collaboration canvas
FLORA aims to make generative creation accessible, removing the need for advanced technical skills or hardware. Drag, drop, and connect hand curated AI models to build your own creative workflows with a high degree of creative control.




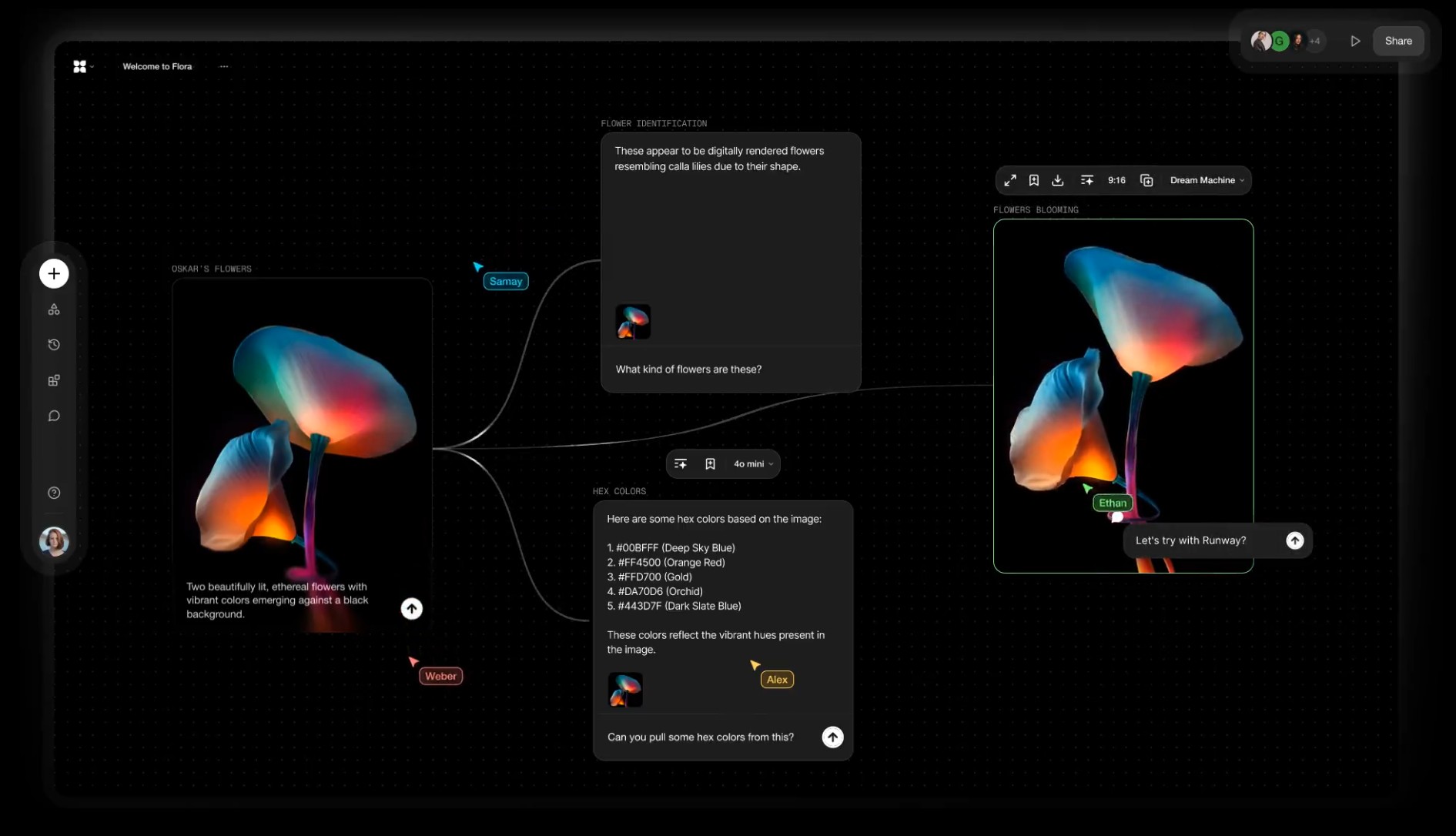
-
Runway introduces Gen-4 – Generate consistent elements by controlling input elements
https://runwayml.com/research/introducing-runway-gen-4
With Gen-4, you are now able to precisely generate consistent characters, locations and objects across scenes. Simply set your look and feel and the model will maintain coherent world environments while preserving the distinctive style, mood and cinematographic elements of each frame. Then, regenerate those elements from multiple perspectives and positions within your scenes.
𝗛𝗲𝗿𝗲’𝘀 𝘄𝗵𝘆 𝗚𝗲𝗻-𝟰 𝗰𝗵𝗮𝗻𝗴𝗲𝘀 𝗲𝘃𝗲𝗿𝘆𝘁𝗵𝗶𝗻𝗴:
✨ 𝗨𝗻𝘄𝗮𝘃𝗲𝗿𝗶𝗻𝗴 𝗖𝗵𝗮𝗿𝗮𝗰𝘁𝗲𝗿 𝗖𝗼𝗻𝘀𝗶𝘀𝘁𝗲𝗻𝗰𝘆
• Characters and environments 𝗻𝗼𝘄 𝘀𝘁𝗮𝘆 𝗳𝗹𝗮𝘄𝗹𝗲𝘀𝘀𝗹𝘆 𝗰𝗼𝗻𝘀𝗶𝘀𝘁𝗲𝗻𝘁 across shots—even as lighting shifts or angles pivot—all from one reference image. No more jarring transitions or mismatched details.
✨ 𝗗𝘆𝗻𝗮𝗺𝗶𝗰 𝗠𝘂𝗹𝘁𝗶-𝗔𝗻𝗴𝗹𝗲 𝗠𝗮𝘀𝘁𝗲𝗿𝘆
• Generate cohesive scenes from any perspective without manual tweaks. Gen-4 intuitively 𝗰𝗿𝗮𝗳𝘁𝘀 𝗺𝘂𝗹𝘁𝗶-𝗮𝗻𝗴𝗹𝗲 𝗰𝗼𝘃𝗲𝗿𝗮𝗴𝗲, 𝗮 𝗹𝗲𝗮𝗽 𝗽𝗮𝘀𝘁 𝗲𝗮𝗿𝗹𝗶𝗲𝗿 𝗺𝗼𝗱𝗲𝗹𝘀 that struggled with spatial continuity.
✨ 𝗣𝗵𝘆𝘀𝗶𝗰𝘀 𝗧𝗵𝗮𝘁 𝗙𝗲𝗲𝗹 𝗔𝗹𝗶𝘃𝗲
• Capes ripple, objects collide, and fabrics drape with startling realism. 𝗚𝗲𝗻-𝟰 𝘀𝗶𝗺𝘂𝗹𝗮𝘁𝗲𝘀 𝗿𝗲𝗮𝗹-𝘄𝗼𝗿𝗹𝗱 𝗽𝗵𝘆𝘀𝗶𝗰𝘀, breathing life into scenes that once demanded painstaking manual animation.
✨ 𝗦𝗲𝗮𝗺𝗹𝗲𝘀𝘀 𝗦𝘁𝘂𝗱𝗶𝗼 𝗜𝗻𝘁𝗲𝗴𝗿𝗮𝘁𝗶𝗼𝗻
• Outputs now blend effortlessly with live-action footage or VFX pipelines. 𝗠𝗮𝗷𝗼𝗿 𝘀𝘁𝘂𝗱𝗶𝗼𝘀 𝗮𝗿𝗲 𝗮𝗹𝗿𝗲𝗮𝗱𝘆 𝗮𝗱𝗼𝗽𝘁𝗶𝗻𝗴 𝗚𝗲𝗻-𝟰 𝘁𝗼 𝗽𝗿𝗼𝘁𝗼𝘁𝘆𝗽𝗲 𝘀𝗰𝗲𝗻𝗲𝘀 𝗳𝗮𝘀𝘁𝗲𝗿 and slash production timelines.
• 𝗪𝗵𝘆 𝘁𝗵𝗶𝘀 𝗺𝗮𝘁𝘁𝗲𝗿𝘀: Gen-4 erases the line between AI experiments and professional filmmaking. 𝗗𝗶𝗿𝗲𝗰𝘁𝗼𝗿𝘀 𝗰𝗮𝗻 𝗶𝘁𝗲𝗿𝗮𝘁𝗲 𝗼𝗻 𝗰𝗶𝗻𝗲𝗺𝗮𝘁𝗶𝗰 𝘀𝗲𝗾𝘂𝗲𝗻𝗰𝗲𝘀 𝗶𝗻 𝗱𝗮𝘆𝘀, 𝗻𝗼𝘁 𝗺𝗼𝗻𝘁𝗵𝘀—democratizing access to tools that once required million-dollar budgets.






FEATURED POSTS

-
Embedding frame ranges into Quicktime movies with FFmpeg
QuickTime (.mov) files are fundamentally time-based, not frame-based, and so don’t have a built-in, uniform “first frame/last frame” field you can set as numeric frame IDs. Instead, tools like Shotgun Create rely on the timecode track and the movie’s duration to infer frame numbers. If you want Shotgun to pick up a non-default frame range (e.g. start at 1001, end at 1064), you must bake in an SMPTE timecode that corresponds to your desired start frame, and ensure the movie’s duration matches your clip length.
How Shotgun Reads Frame Ranges
- Default start frame is 1. If no timecode metadata is present, Shotgun assumes the movie begins at frame 1.
- Timecode ⇒ frame number. Shotgun Create “honors the timecodes of media sources,” mapping the embedded TC to frame IDs. For example, a 24 fps QuickTime tagged with a start timecode of 00:00:41:17 will be interpreted as beginning on frame 1001 (1001 ÷ 24 fps ≈ 41.71 s).
Embedding a Start Timecode
QuickTime uses a
tmcd(timecode) track. You can bake in an SMPTE track via FFmpeg’s-timecodeflag or via Compressor/encoder settings:- Compute your start TC.
- Desired start frame = 1001
- Frame 1001 at 24 fps ⇒ 1001 ÷ 24 ≈ 41.708 s ⇒ TC 00:00:41:17
- FFmpeg example:
ffmpeg -i input.mov \ -c copy \ -timecode 00:00:41:17 \ output.movThis adds a timecode track beginning at 00:00:41:17, which Shotgun maps to frame 1001.
Ensuring the Correct End Frame
Shotgun infers the last frame from the movie’s duration. To end on frame 1064:
- Frame count = 1064 – 1001 + 1 = 64 frames
- Duration = 64 ÷ 24 fps ≈ 2.667 s
FFmpeg trim example:
ffmpeg -i input.mov \ -c copy \ -timecode 00:00:41:17 \ -t 00:00:02.667 \ output_trimmed.movThis results in a 64-frame clip (1001→1064) at 24 fps.

-
Free fonts
https://fontlibrary.org
https://fontsource.orgOpen-source fonts packaged into individual NPM packages for self-hosting in web applications. Self-hosting fonts can significantly improve website performance, remain version-locked, work offline, and offer more privacy.
https://www.awwwards.com/awwwards/collections/free-fonts
http://www.fontspace.com/popular/fonts
https://www.urbanfonts.com/free-fonts.htm
http://www.1001fonts.com/poster-fonts.html

How to use @font-face in CSS
The
@font-facerule allows custom fonts to be loaded on a webpage: https://css-tricks.com/snippets/css/using-font-face-in-css/



-
What light is best to illuminate gems for resale
www.palagems.com/gem-lighting2
Artificial light sources, not unlike the diverse phases of natural light, vary considerably in their properties. As a result, some lamps render an object’s color better than others do.
The most important criterion for assessing the color-rendering ability of any lamp is its spectral power distribution curve.
Natural daylight varies too much in strength and spectral composition to be taken seriously as a lighting standard for grading and dealing colored stones. For anything to be a standard, it must be constant in its properties, which natural light is not.
For dealers in particular to make the transition from natural light to an artificial light source, that source must offer:
1- A degree of illuminance at least as strong as the common phases of natural daylight.
2- Spectral properties identical or comparable to a phase of natural daylight.A source combining these two things makes gems appear much the same as when viewed under a given phase of natural light. From the viewpoint of many dealers, this corresponds to a naturalappearance.
The 6000° Kelvin xenon short-arc lamp appears closest to meeting the criteria for a standard light source. Besides the strong illuminance this lamp affords, its spectrum is very similar to CIE standard illuminants of similar color temperature.

