



BREAKING NEWS
LATEST POSTS
-
One-Prompt-One-Story – Free-Lunch Consistent Text-to-Image Generation Using a Single Prompt
https://byliutao.github.io/1Prompt1Story.github.io
Tneration models can create high-quality images from input prompts. However, they struggle to support the consistent generation of identity-preserving requirements for storytelling.
Our approach 1Prompt1Story concatenates all prompts into a single input for T2I diffusion models, initially preserving character identities.

-
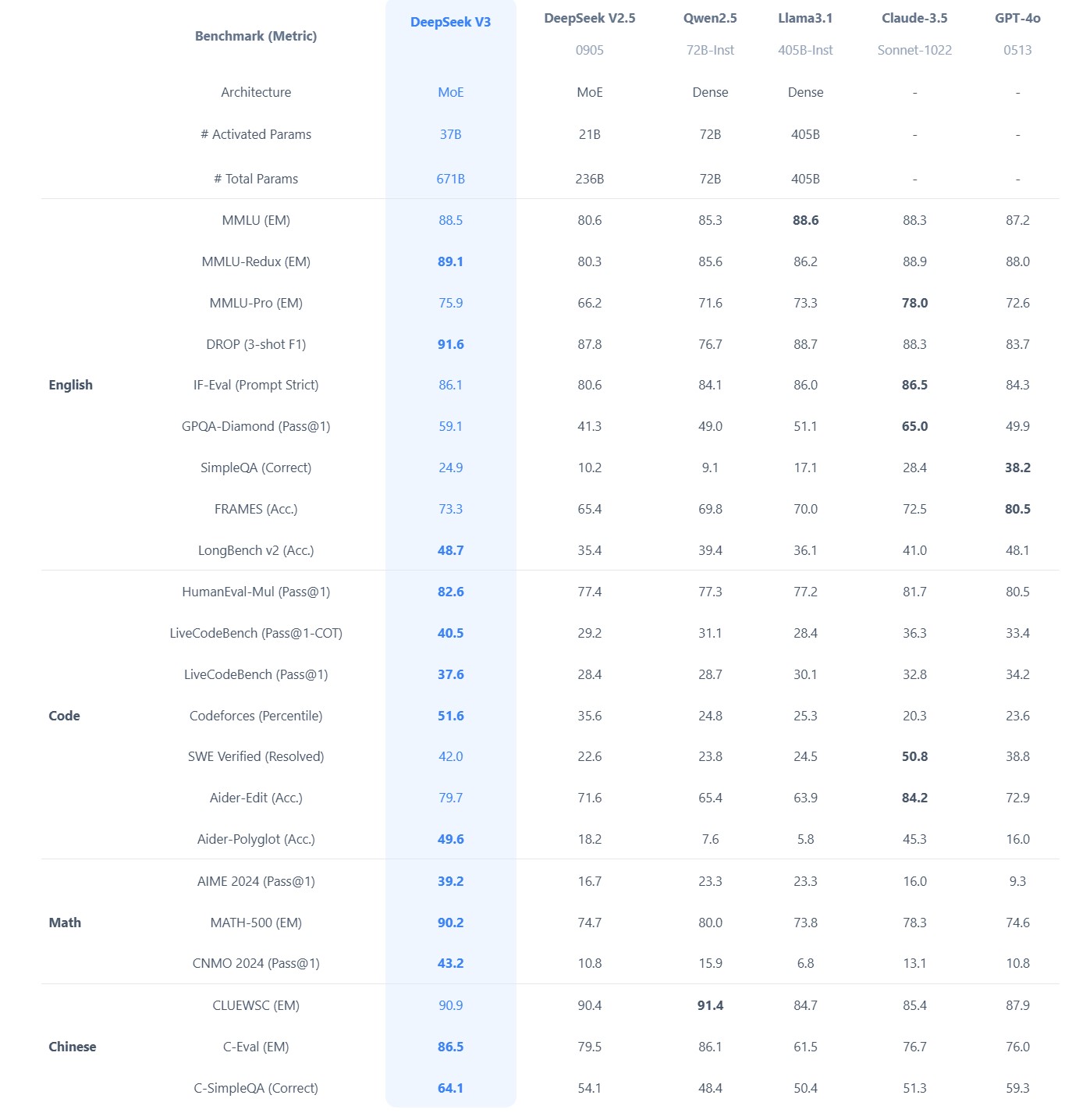
What did DeepSeek figure out about reasoning with DeepSeek-R1?
https://www.seangoedecke.com/deepseek-r1
The Chinese AI lab DeepSeek recently released their new reasoning model R1, which is supposedly (a) better than the current best reasoning models (OpenAI’s o1- series), and (b) was trained on a GPU cluster a fraction the size of any of the big western AI labs.
DeepSeek uses a reinforcement learning approach, not a fine-tuning approach. There’s no need to generate a huge body of chain-of-thought data ahead of time, and there’s no need to run an expensive answer-checking model. Instead, the model generates its own chains-of-thought as it goes.
The secret behind their success? A bold move to train their models using FP8 (8-bit floating-point precision) instead of the standard FP32 (32-bit floating-point precision).
…
By using a clever system that applies high precision only when absolutely necessary, they achieved incredible efficiency without losing accuracy.
…
The impressive part? These multi-token predictions are about 85–90% accurate, meaning DeepSeek R1 can deliver high-quality answers at double the speed of its competitors.Chinese AI firm DeepSeek has 50,000 NVIDIA H100 AI GPUs

-
CaPa – Carve-n-Paint Synthesisfor Efficient 4K Textured Mesh Generation
https://github.com/ncsoft/CaPa
a novel method for generating hyper-quality 4K textured mesh under only 30 seconds, providing 3D assets ready for commercial applications such as games, movies, and VR/AR.

-
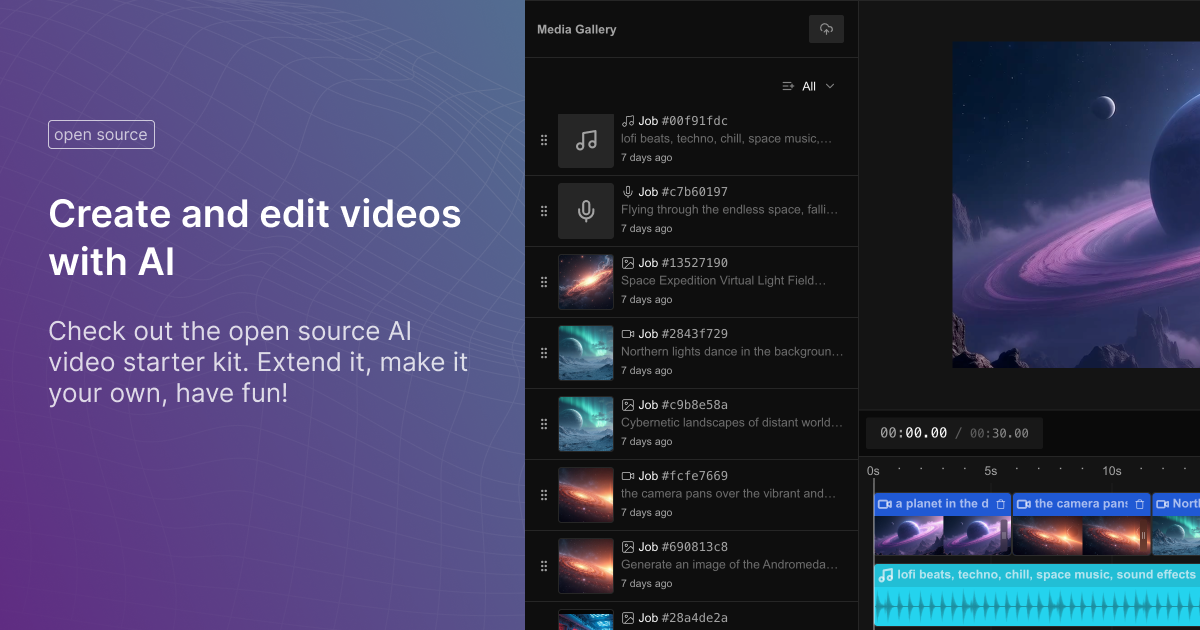
Fal Video Studio – The first open-source AI toolkit for video editing
https://github.com/fal-ai-community/video-starter-kit
https://fal-video-studio.vercel.app
- 🎬 Browser-Native Video Processing: Seamless video handling and composition in the browser
- 🤖 AI Model Integration: Direct access to state-of-the-art video models through fal.ai
- Minimax for video generation
- Hunyuan for visual synthesis
- LTX for video manipulation
- 🎵 Advanced Media Capabilities:
- Multi-clip video composition
- Audio track integration
- Voiceover support
- Extended video duration handling
- 🛠️ Developer Utilities:
- Metadata encoding
- Video processing pipeline
- Ready-to-use UI components
- TypeScript support
-
Tencent Hunyuan3D – an advanced large-scale 3D synthesis system for generating high-resolution textured 3D assets
https://github.com/tencent/Hunyuan3D-2
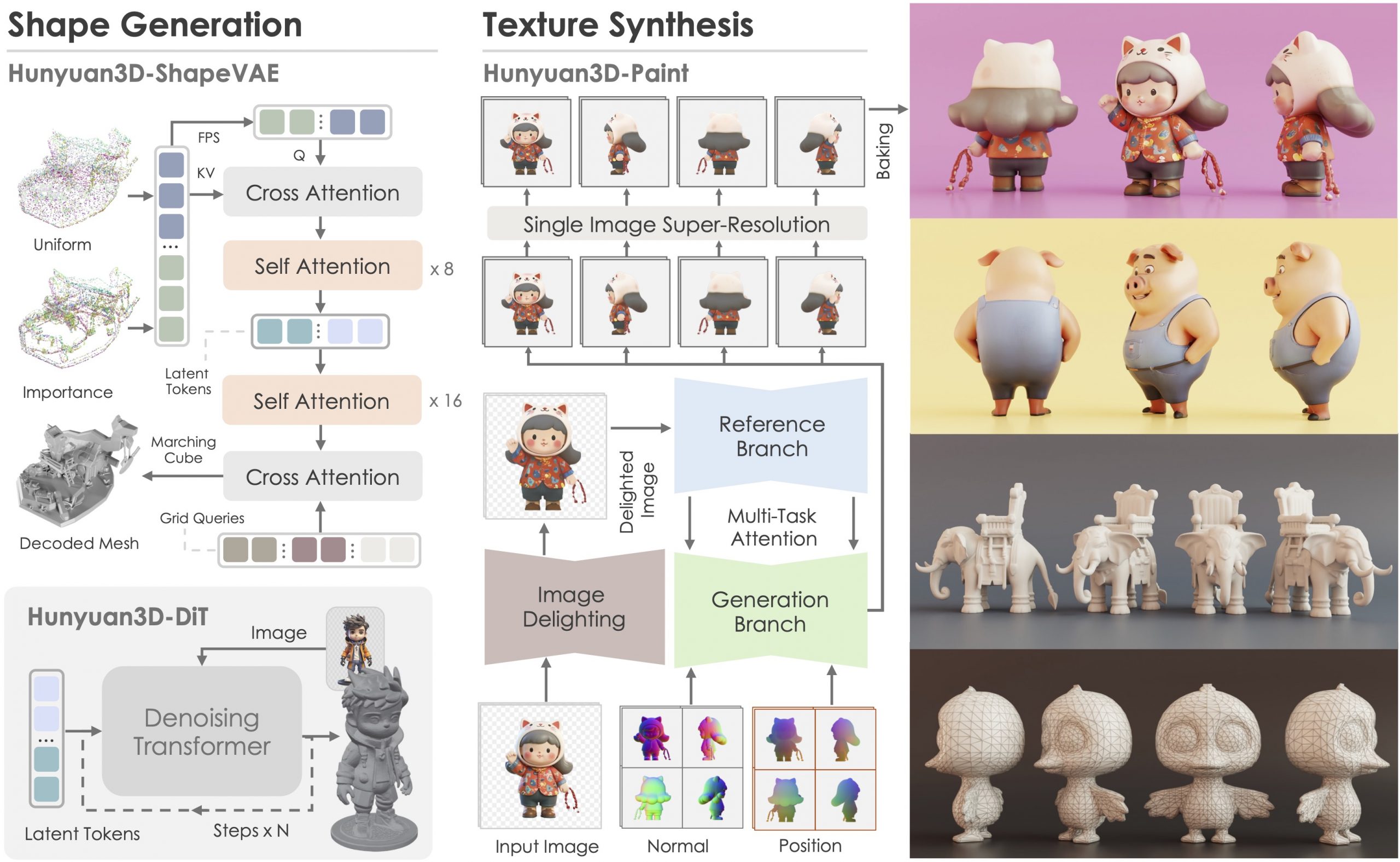

Hunyuan3D 2.0, an advanced large-scale 3D synthesis system for generating high-resolution textured 3D assets. This system includes two foundation components: a large-scale shape generation model – Hunyuan3D-DiT, and a large-scale texture synthesis model – Hunyuan3D-Paint.
The shape generative model, built on a scalable flow-based diffusion transformer, aims to create geometry that properly aligns with a given condition image, laying a solid foundation for downstream applications. The texture synthesis model, benefiting from strong geometric and diffusion priors, produces high-resolution and vibrant texture maps for either generated or hand-crafted meshes. Furthermore, we build Hunyuan3D-Studio – a versatile, user-friendly production platform that simplifies the re-creation process of 3D assets.
It allows both professional and amateur users to manipulate or even animate their meshes efficiently. We systematically evaluate our models, showing that Hunyuan3D 2.0 outperforms previous state-of-the-art models, including the open-source models and closed-source models in geometry details, condition alignment, texture quality, and e.t.c.






FEATURED POSTS




-
Free fonts
https://fontlibrary.org
https://fontsource.orgOpen-source fonts packaged into individual NPM packages for self-hosting in web applications. Self-hosting fonts can significantly improve website performance, remain version-locked, work offline, and offer more privacy.
https://www.awwwards.com/awwwards/collections/free-fonts
http://www.fontspace.com/popular/fonts
https://www.urbanfonts.com/free-fonts.htm
http://www.1001fonts.com/poster-fonts.html

How to use @font-face in CSS
The
@font-facerule allows custom fonts to be loaded on a webpage: https://css-tricks.com/snippets/css/using-font-face-in-css/

-
Photography Basics : Spectral Sensitivity Estimation Without a Camera
https://color-lab-eilat.github.io/Spectral-sensitivity-estimation-web/
A number of problems in computer vision and related fields would be mitigated if camera spectral sensitivities were known. As consumer cameras are not designed for high-precision visual tasks, manufacturers do not disclose spectral sensitivities. Their estimation requires a costly optical setup, which triggered researchers to come up with numerous indirect methods that aim to lower cost and complexity by using color targets. However, the use of color targets gives rise to new complications that make the estimation more difficult, and consequently, there currently exists no simple, low-cost, robust go-to method for spectral sensitivity estimation that non-specialized research labs can adopt. Furthermore, even if not limited by hardware or cost, researchers frequently work with imagery from multiple cameras that they do not have in their possession.
To provide a practical solution to this problem, we propose a framework for spectral sensitivity estimation that not only does not require any hardware (including a color target), but also does not require physical access to the camera itself. Similar to other work, we formulate an optimization problem that minimizes a two-term objective function: a camera-specific term from a system of equations, and a universal term that bounds the solution space.
Different than other work, we utilize publicly available high-quality calibration data to construct both terms. We use the colorimetric mapping matrices provided by the Adobe DNG Converter to formulate the camera-specific system of equations, and constrain the solutions using an autoencoder trained on a database of ground-truth curves. On average, we achieve reconstruction errors as low as those that can arise due to manufacturing imperfections between two copies of the same camera. We provide predicted sensitivities for more than 1,000 cameras that the Adobe DNG Converter currently supports, and discuss which tasks can become trivial when camera responses are available.




