One of the strengths of that original OpenAI group was recruiting. Somehow you managed to corner the market on a ton of the top AI research talent, often with much less money to offer than your competitors. What was the pitch?
The pitch was just come build AGI. And the reason it worked—I cannot overstate how heretical it was at the time to say we’re gonna build AGI. So you filter out 99% of the world, and you only get the really talented, original thinkers. And that’s really powerful. If you’re doing the same thing everybody else is doing, if you’re building, like, the 10,000th photo-sharing app? Really hard to recruit talent.
OpenAI senior executives at the company’s headquarters in San Francisco on March 13, 2023, from left: Sam Altman, chief executive officer; Mira Murati, chief technology officer; Greg Brockman, president; and Ilya Sutskever, chief scientist. Photographer: Jim Wilson/The New York Times
An efficient differentiable mesh-based method that can effectively handle complex 2D and 3D shapes. For instance, it can be used for reconstructing complex shapes from point clouds and multi-view images.
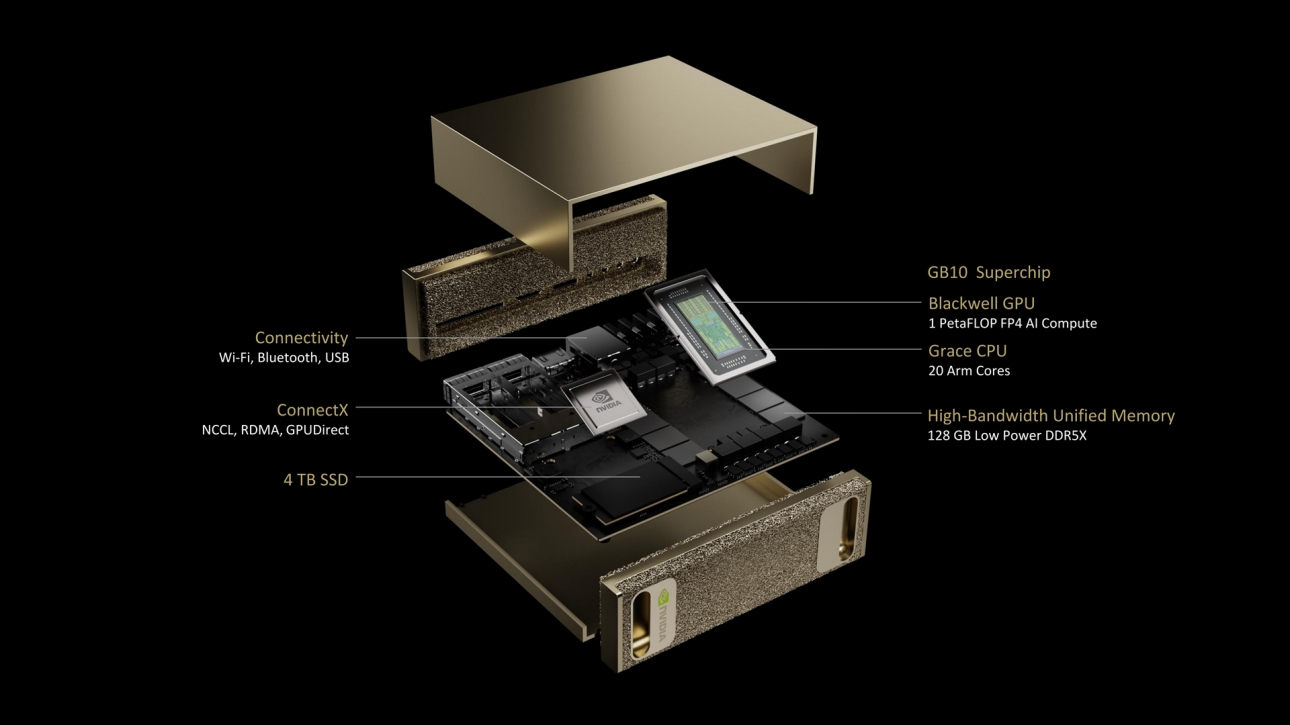
Some smaller open-weights AI language models (such as Llama 3.1 70B, with 70 billion parameters) and various AI image-synthesis models like Flux.1 dev (12 billion parameters) could probably run comfortably on Project DIGITS, but larger open models like Llama 3.1 405B, with 405 billion parameters, may not. Given the recent explosion of smaller AI models, a creative developer could likely run quite a few interesting models on the unit.
DIGITS’ 128GB of unified RAM is notable because a high-power consumer GPU like the RTX 4090 has only 24GB of VRAM. Memory serves as a hard limit on AI model parameter size, and more memory makes room for running larger local AI models.
Temporary Use: AI-generated material can be used for ideation, visualization, and exploration—but is currently considered temporary and not part of final deliverables.
Ownership & Rights: All outputs must be carefully reviewed to ensure rights, copyright, and usage are properly cleared before integrating into production.
Transparency: Productions are expected to document and disclose how generative AI is used.
Human Oversight: AI tools are meant to support creative teams, not replace them—final decision-making rests with human creators.
Security & Compliance: Any use of AI tools must align with Netflix’s security protocols and protect confidential production material.
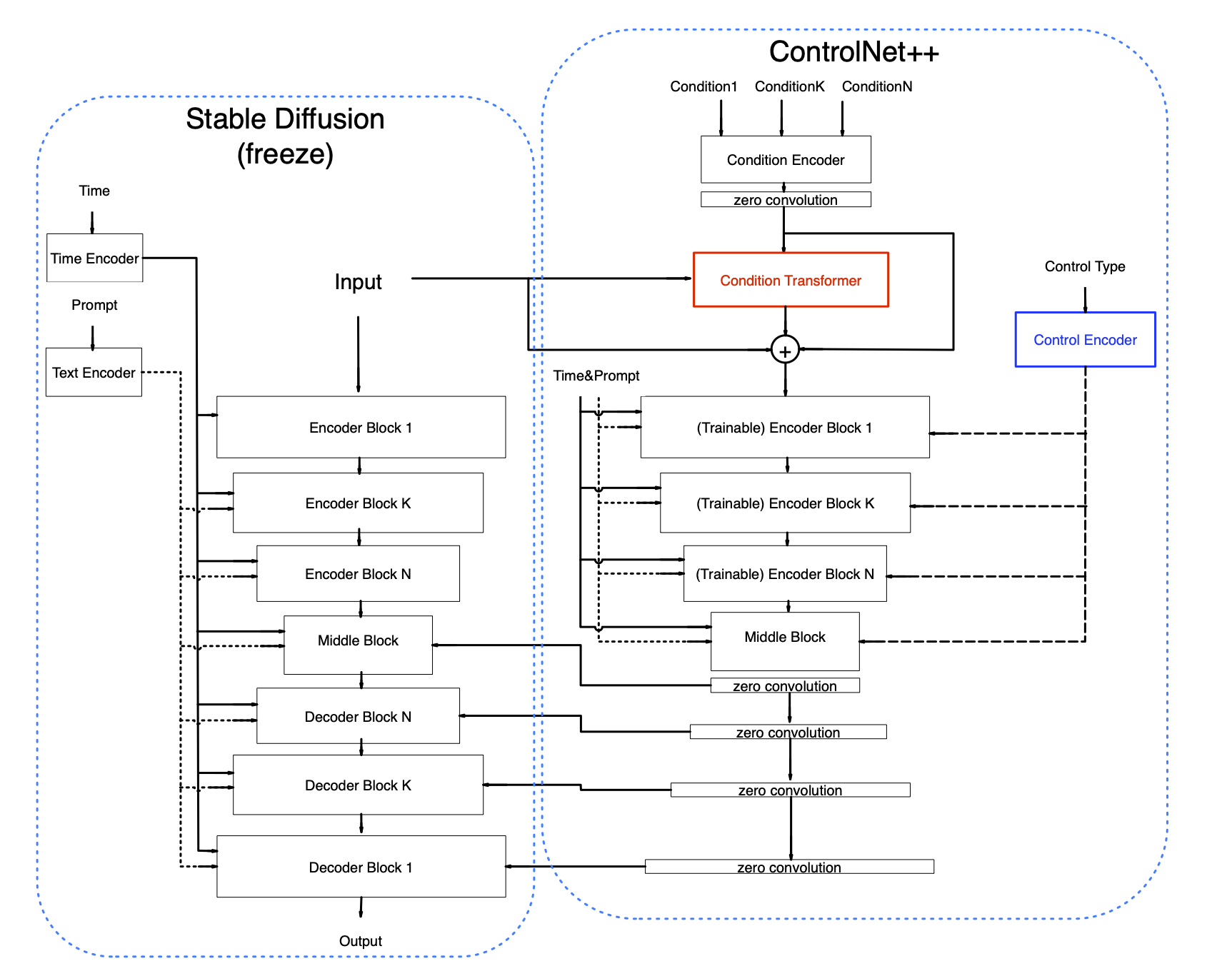
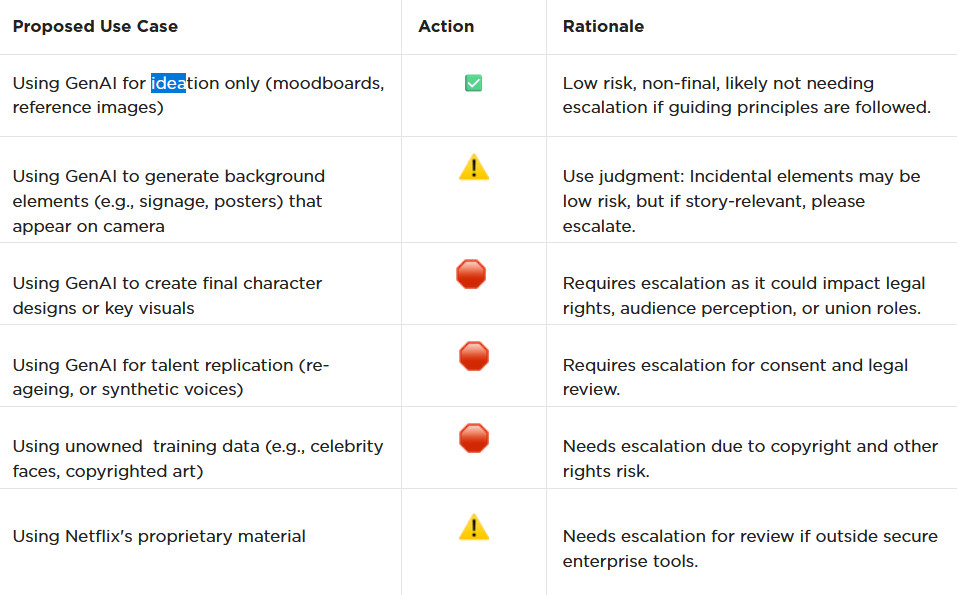
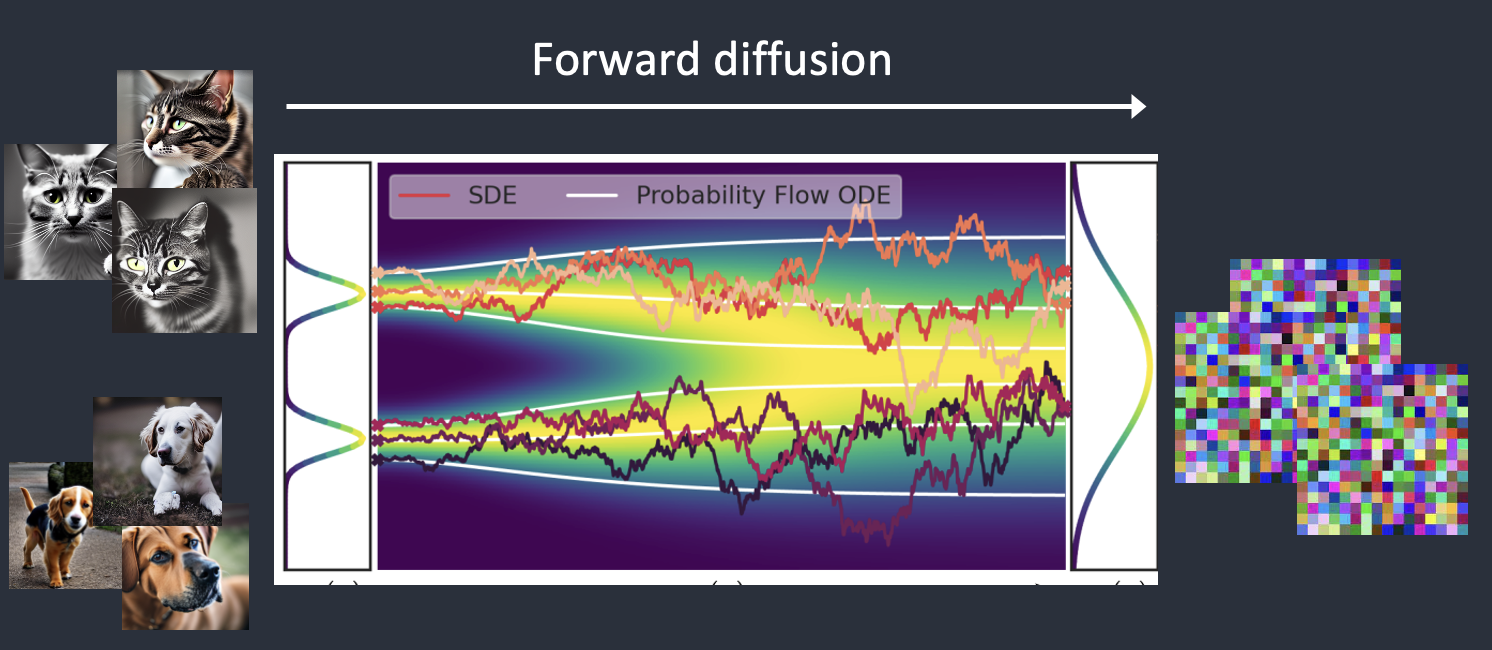
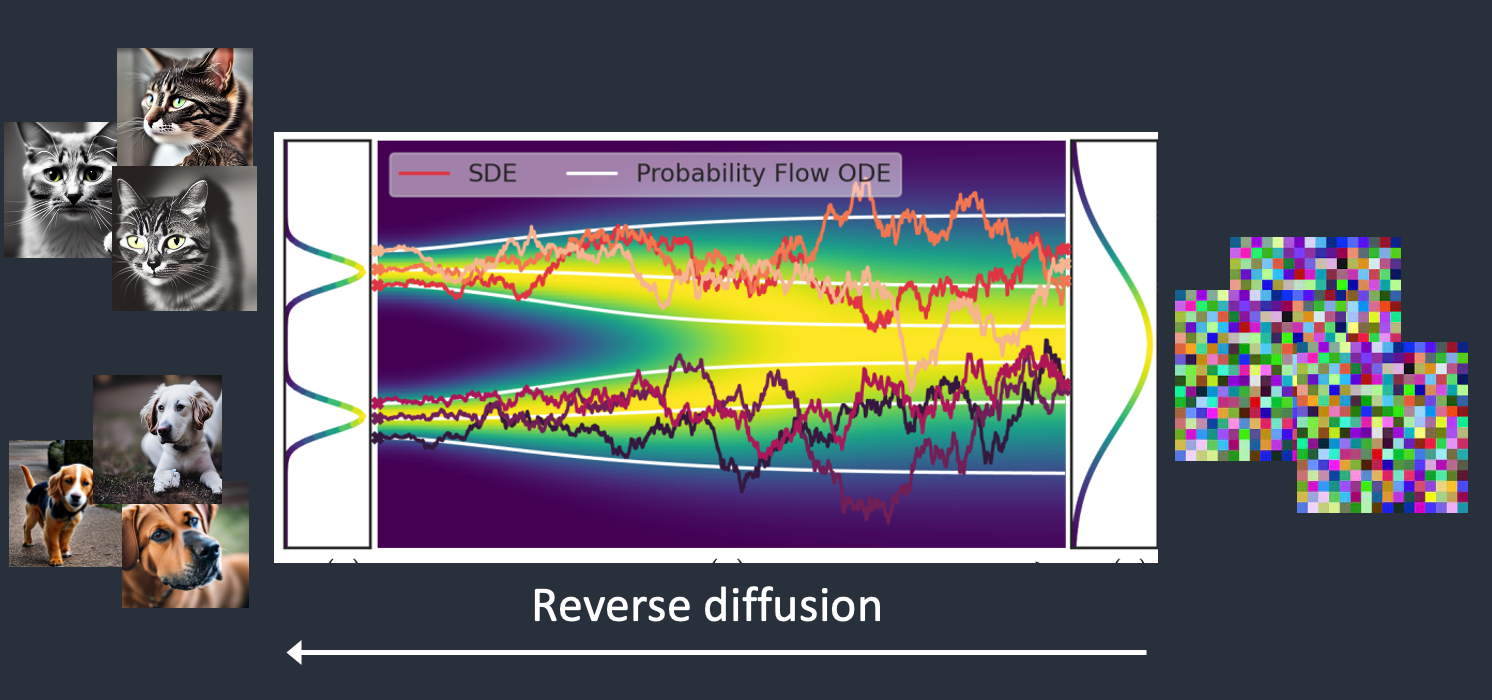
Stable Diffusion is a latent diffusion model that generates AI images from text. Instead of operating in the high-dimensional image space, it first compresses the image into the latent space.
Stable Diffusion belongs to a class of deep learning models called diffusion models. They are generative models, meaning they are designed to generate new data similar to what they have seen in training. In the case of Stable Diffusion, the data are images.
Why is it called the diffusion model? Because its math looks very much like diffusion in physics. Let’s go through the idea.
The Manuka rendering architecture has been designed in the spirit of the classic reyes rendering architecture. In its core, reyes is based on stochastic rasterisation of micropolygons, facilitating depth of field, motion blur, high geometric complexity,and programmable shading.
This is commonly achieved with Monte Carlo path tracing, using a paradigm often called shade-on-hit, in which the renderer alternates tracing rays with running shaders on the various ray hits. The shaders take the role of generating the inputs of the local material structure which is then used bypath sampling logic to evaluate contributions and to inform what further rays to cast through the scene.
Over the years, however, the expectations have risen substantially when it comes to image quality. Computing pictures which are indistinguishable from real footage requires accurate simulation of light transport, which is most often performed using some variant of Monte Carlo path tracing. Unfortunately this paradigm requires random memory accesses to the whole scene and does not lend itself well to a rasterisation approach at all.
Manuka is both a uni-directional and bidirectional path tracer and encompasses multiple importance sampling (MIS). Interestingly, and importantly for production character skin work, it is the first major production renderer to incorporate spectral MIS in the form of a new ‘Hero Spectral Sampling’ technique, which was recently published at Eurographics Symposium on Rendering 2014.
Manuka propose a shade-before-hit paradigm in-stead and minimise I/O strain (and some memory costs) on the system, leveraging locality of reference by running pattern generation shaders before we execute light transport simulation by path sampling, “compressing” any bvh structure as needed, and as such also limiting duplication of source data.
The difference with reyes is that instead of baking colors into the geometry like in Reyes, manuka bakes surface closures. This means that light transport is still calculated with path tracing, but all texture lookups etc. are done up-front and baked into the geometry.
The main drawback with this method is that geometry has to be tessellated to its highest, stable topology before shading can be evaluated properly. As such, the high cost to first pixel. Even a basic 4 vertices square becomes a much more complex model with this approach.
Manuka use the RenderMan Shading Language (rsl) for programmable shading [Pixar Animation Studios 2015], but we do not invoke rsl shaders when intersecting a ray with a surface (often called shade-on-hit). Instead, we pre-tessellate and pre-shade all the input geometry in the front end of the renderer.
This way, we can efficiently order shading computations to sup-port near-optimal texture locality, vectorisation, and parallelism. This system avoids repeated evaluation of shaders at the same surface point, and presents a minimal amount of memory to be accessed during light transport time. An added benefit is that the acceleration structure for ray tracing (abounding volume hierarchy, bvh) is built once on the final tessellated geometry, which allows us to ray trace more efficiently than multi-level bvhs and avoids costly caching of on-demand tessellated micropolygons and the associated scheduling issues.
For the shading reasons above, in terms of AOVs, the studio approach is to succeed at combining complex shading with ray paths in the render rather than pass a multi-pass render to compositing.
For the Spectral Rendering component. The light transport stage is fully spectral, using a continuously sampled wavelength which is traced with each path and used to apply the spectral camera sensitivity of the sensor. This allows for faithfully support any degree of observer metamerism as the camera footage they are intended to match as well as complex materials which require wavelength dependent phenomena such as diffraction, dispersion, interference, iridescence, or chromatic extinction and Rayleigh scattering in participating media.
As opposed to the original reyes paper, we use bilinear interpolation of these bsdf inputs later when evaluating bsdfs per pathv ertex during light transport4. This improves temporal stability of geometry which moves very slowly with respect to the pixel raster
In terms of the pipeline, everything rendered at Weta was already completely interwoven with their deep data pipeline. Manuka very much was written with deep data in mind. Here, Manuka not so much extends the deep capabilities, rather it fully matches the already extremely complex and powerful setup Weta Digital already enjoy with RenderMan. For example, an ape in a scene can be selected, its ID is available and a NUKE artist can then paint in 3D say a hand and part of the way up the neutral posed ape.
We called our system Manuka, as a respectful nod to reyes: we had heard a story froma former ILM employee about how reyes got its name from how fond the early Pixar people were of their lunches at Point Reyes, and decided to name our system after our surrounding natural environment, too. Manuka is a kind of tea tree very common in New Zealand which has very many very small leaves, in analogy to micropolygons ina tree structure for ray tracing. It also happens to be the case that Weta Digital’s main site is on Manuka Street.