FlashVSR is a streaming, one-step diffusion-based video super-resolution framework with block-sparse attention and a Tiny Conditional Decoder. It reaches ~17 FPS at 768×1408 on a single A100 GPU. A Locality-Constrained Attention design further improves generalization and perceptual quality on ultra-high-resolution videos.
Stable Video Infinity (SVI) is able to generate ANY-length videos with high temporal consistency, plausible scene transitions, and controllable streaming storylines in ANY domains.
OpenSVI: Everything is open-sourced: training & evaluation scripts, datasets, and more.
Infinite Length: No inherent limit on video duration; generate arbitrarily long stories (see the 10‑minute “Tom and Jerry” demo).
Versatile: Supports diverse in-the-wild generation tasks: multi-scene short films, single‑scene animations, skeleton-/audio-conditioned generation, cartoons, and more.
Efficient: Only LoRA adapters are tuned, requiring very little training data: anyone can make their own SVI easily.
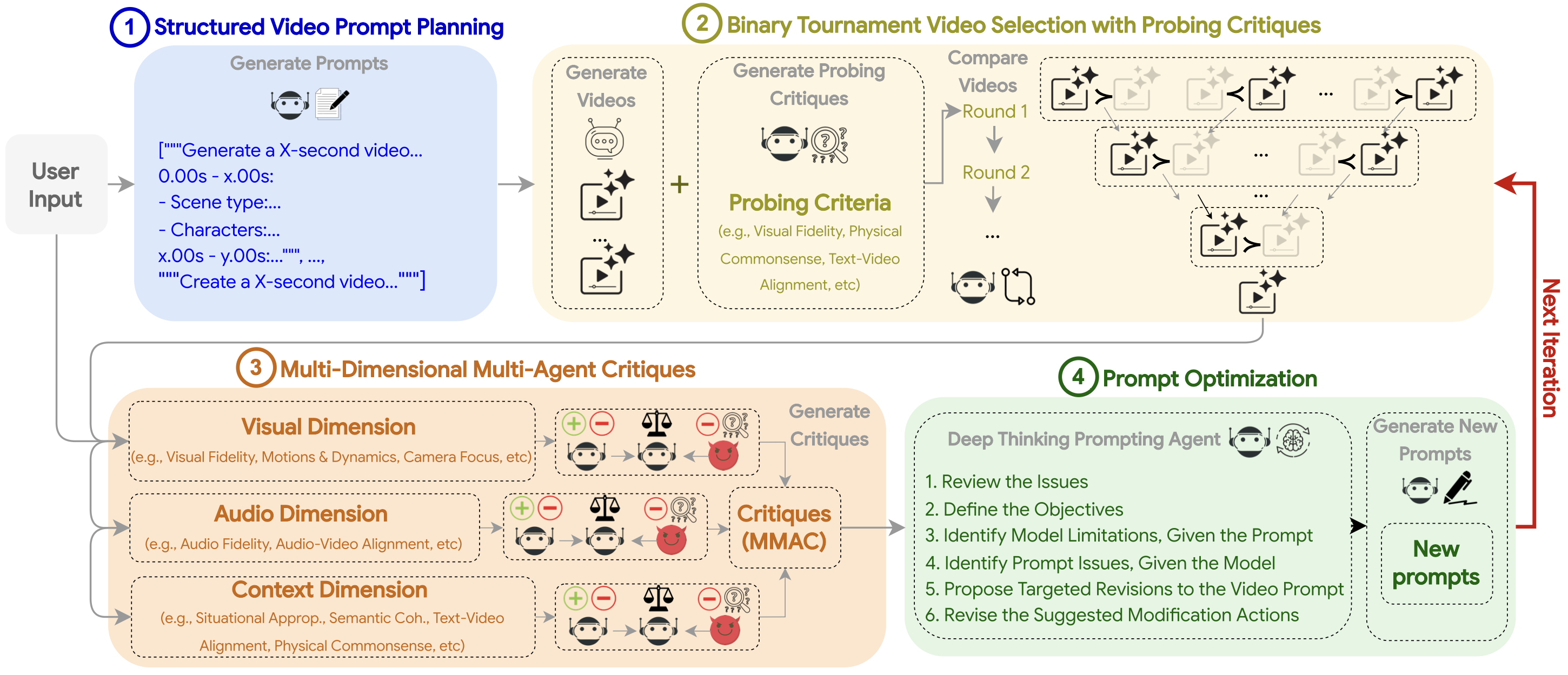
VISTA is a modular, configurable framework for optimizing text-to-video generation. Given a user video prompt P, it produces an optimized video V* and its refined prompt P* through two phases: (i) Initialization and (ii) Self-Improvement, inspired by the human video optimization process via prompting. During (i), the prompt is parsed and planned into variants to generate candidate videos (Step 1), after which the best video-prompt pair is selected (Step 2). In (ii), the system generates multi-dimensional, multi-agent critiques (Step 3), refines the prompt (Step 4), produces new videos, and reselects the champion pair (Step 2). This phase continues until a stopping criterion is met or the maximum number of iterations is reached.
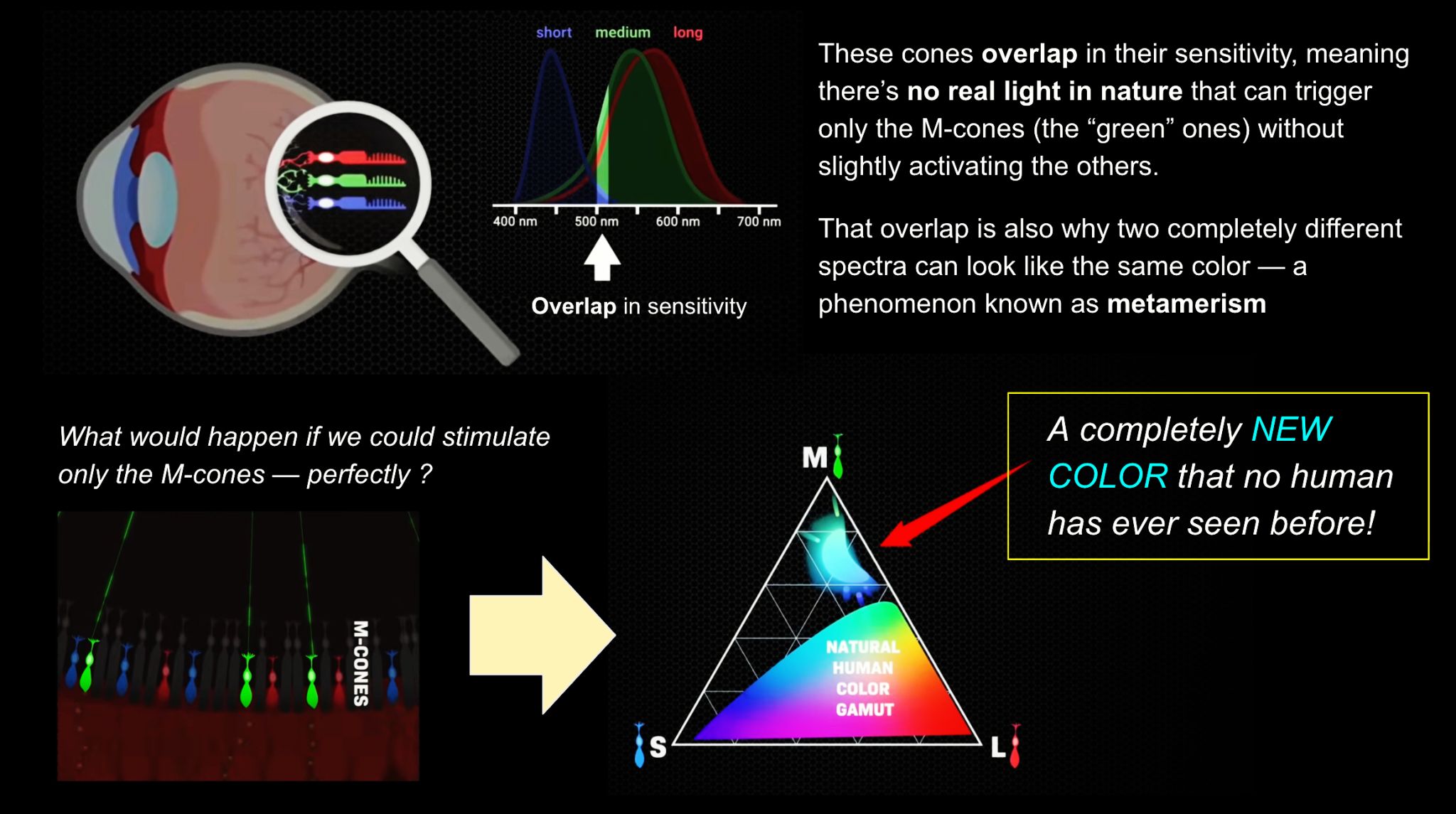
We introduce a principle, Oz, for displaying color imagery: directly controlling the human eye’s photoreceptor activity via cell-by-cell light delivery. Theoretically, novel colors are possible through bypassing the constraints set by the cone spectral sensitivities and activating M cone cells exclusively. In practice, we confirm a partial expansion of colorspace toward that theoretical ideal. Attempting to activate M cones exclusively is shown to elicit a color beyond the natural human gamut, formally measured with color matching by human subjects. They describe the color as blue-green of unprecedented saturation. Further experiments show that subjects perceive Oz colors in image and video form. The prototype targets laser microdoses to thousands of spectrally classified cones under fixational eye motion. These results are proof-of-principle for programmable control over individual photoreceptors at population scale.
SeC (Segment Concept) is a breakthrough in video object segmentation that shifts from simple feature matching to high-level conceptual understanding. Unlike SAM 2.1 which relies primarily on visual similarity, SeC uses a Large Vision-Language Model (LVLM) to understand what an object is conceptually, enabling robust tracking through:
Semantic Understanding: Recognizes objects by concept, not just appearance
Scene Complexity Adaptation: Automatically balances semantic reasoning vs feature matching
Superior Robustness: Handles occlusions, appearance changes, and complex scenes better than SAM 2.1
SOTA Performance: +11.8 points over SAM 2.1 on SeCVOS benchmark
How SeC Works
Visual Grounding: You provide initial prompts (points/bbox/mask) on one frame
Concept Extraction: SeC’s LVLM analyzes the object to build a semantic understanding
Smart Tracking: Dynamically uses both semantic reasoning and visual features
Keyframe Bank: Maintains diverse views of the object for robust concept understanding
The result? SeC tracks objects more reliably through challenging scenarios like rapid appearance changes, occlusions, and complex multi-object scenes.
SeC (Segment Concept) is a breakthrough in video object segmentation that shifts from simple feature matching to high-level conceptual understanding. Unlike SAM 2.1 which relies primarily on visual similarity, SeC uses a Large Vision-Language Model (LVLM) to understand what an object is conceptually, enabling robust tracking through:
Semantic Understanding: Recognizes objects by concept, not just appearance
Scene Complexity Adaptation: Automatically balances semantic reasoning vs feature matching
Superior Robustness: Handles occlusions, appearance changes, and complex scenes better than SAM 2.1
SOTA Performance: +11.8 points over SAM 2.1 on SeCVOS benchmark
How SeC Works
Visual Grounding: You provide initial prompts (points/bbox/mask) on one frame
Concept Extraction: SeC’s LVLM analyzes the object to build a semantic understanding
Smart Tracking: Dynamically uses both semantic reasoning and visual features
Keyframe Bank: Maintains diverse views of the object for robust concept understanding
The result? SeC tracks objects more reliably through challenging scenarios like rapid appearance changes, occlusions, and complex multi-object scenes.
Airplane manufacturing is no different from mortgage lending or insulin distribution or make-believe blood analyzing software (or VFX?) —another cash cow for the one percent, bound inexorably for the slaughterhouse.
The beginning of the end was “Boeing’s 1997 acquisition of McDonnell Douglas, a dysfunctional firm with a dilapidated aircraft plant in Long Beach and a CEO (Harry Stonecipher) who liked to use what he called the “Hollywood model” for dealing with engineers: Hire them for a few months when project deadlines are nigh, fire them when you need to make numbers.” And all that came with it. “Stonecipher’s team had driven the last nail in the coffin of McDonnell’s flailing commercial jet business by trying to outsource everything but design, final assembly, and flight testing and sales.”
It is understood, now more than ever, that capitalism does half-assed things like that, especially in concert with computer software and oblivious regulators.
There was something unsettlingly familiar when the world first learned of MCAS in November, about two weeks after the system’s unthinkable stupidity drove the two-month-old plane and all 189 people on it to a horrific death. It smacked of the sort of screwup a 23-year-old intern might have made—and indeed, much of the software on the MAX had been engineered by recent grads of Indian software-coding academies making as little as $9 an hour, part of Boeing management’s endless war on the unions that once represented more than half its employees.
Down in South Carolina, a nonunion Boeing assembly line that opened in 2011 had for years churned out scores of whistle-blower complaints and wrongful termination lawsuits packed with scenes wherein quality-control documents were regularly forged, employees who enforced standards were sabotaged, and planes were routinely delivered to airlines with loose screws, scratched windows, and random debris everywhere.
Shockingly, another piece of the quality failure is Boeing securing investments from all airliners, starting with SouthWest above all, to guarantee Boeing’s production lines support in exchange for fair market prices and favorite treatments. Basically giving Boeing financial stability independently on the quality of their product. “Those partnerships were but one numbers-smoothing mechanism in a diversified tool kit Boeing had assembled over the previous generation for making its complex and volatile business more palatable to Wall Street.”
Spectral sensitivity of eye is influenced by light intensity. And the light intensity determines the level of activity of cones cell and rod cell. This is the main characteristic of human vision. Sensitivity to individual colors, in other words, wavelengths of the light spectrum, is explained by the RGB (red-green-blue) theory. This theory assumed that there are three kinds of cones. It’s selectively sensitive to red (700-630 nm), green (560-500 nm), and blue (490-450 nm) light. And their mutual interaction allow to perceive all colors of the spectrum.
5.10 of this tool includes excellent tools to clean up cr2 and cr3 used on set to support HDRI processing.
Converting raw to AcesCG 32 bit tiffs with metadata.






































{kind=link}


