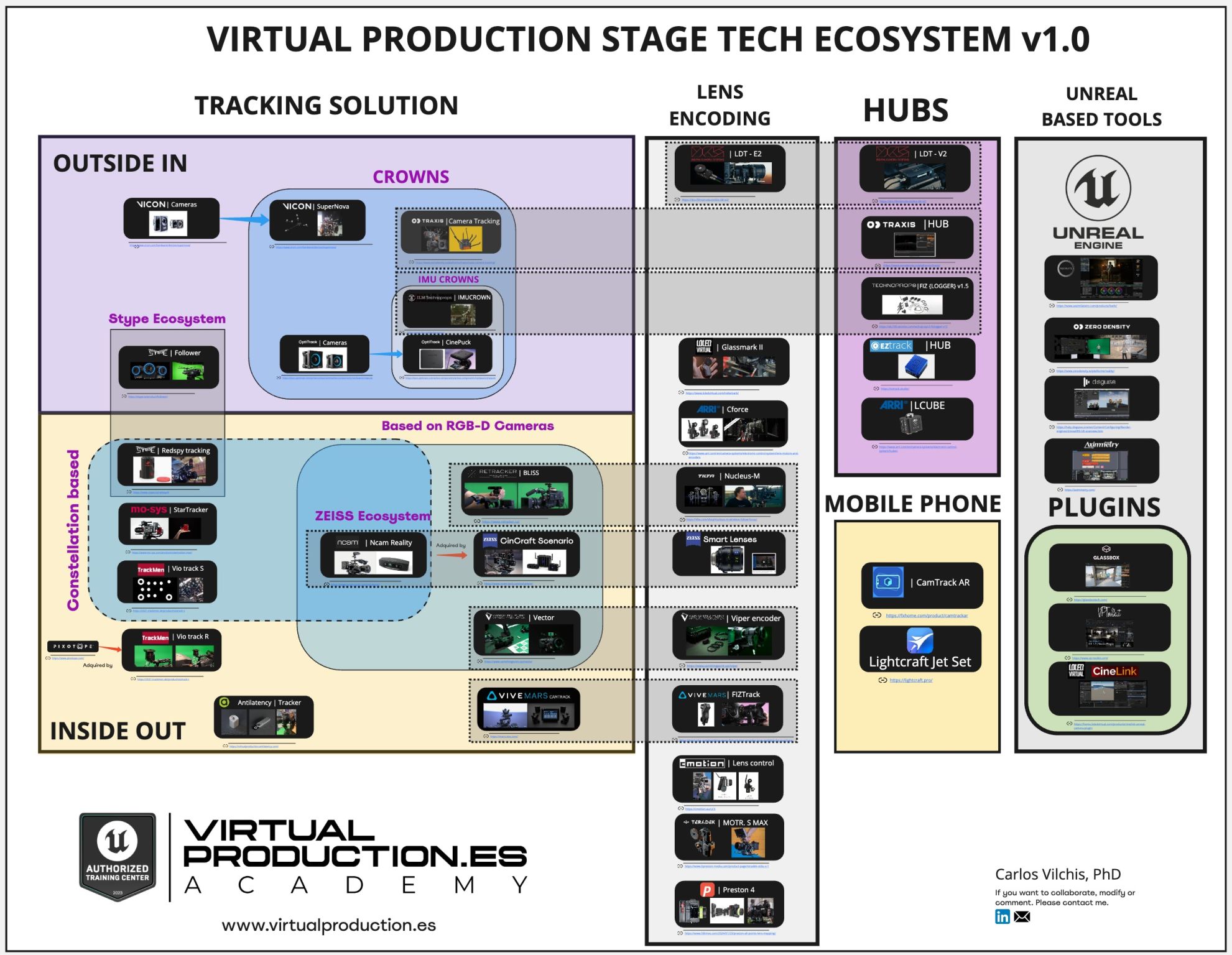
Despilling is arguably the most important step to get right when pulling a key. A great despill can often hide imperfections in your alpha channel & prevents tedious painting to manually fix edges.
Planning with partial observation is a central challenge in embodied AI. A majority of prior works have tackled this challenge by developing agents that physically explore their environment to update their beliefs about the world state. However, humans can imagine unseen parts of the world through a mental exploration and revise their beliefs with imagined observations. Such updated beliefs can allow them to make more informed decisions at the current step, without having to physically explore the world first. To achieve this human-like ability, we introduce the Generative World Explorer (Genex), a video generation model that allows an agent to mentally explore a large-scale 3D world (e.g., urban scenes) and acquire imagined observations to update its belief about the world .
– Markerless facial mocap: capture facial performance and head motion with a matching geometry – Custom face mesh generation: create digital doubles using snapshots of video frames (available with FaceBundle) – 3D texture mapping: beauty work, (de)ageing, relighting – 3D compositing: add digital make-up, dynamic VFX, hair and more – (NEW) Animation retargeting: convert facial animation to ARKit blendshapes or Rigify rig in one click
Recent video generation models can produce smooth and visually appealing clips, but they often struggle to synthesize complex dynamics with a coherent chain of consequences. Accurately modeling visual outcomes and state transitions over time remains a core challenge. In contrast, large language and multimodal models (e.g., GPT-4o) exhibit strong visual state reasoning and future prediction capabilities. To bridge these strengths, we introduce VChain, a novel inference-time chain-of-visual-thought framework that injects visual reasoning signals from multimodal models into video generation. Specifically, VChain contains a dedicated pipeline that leverages large multimodal models to generate a sparse set of critical keyframes as snapshots, which are then used to guide the sparse inference-time tuning of a pre-trained video generator only at these key moments. Our approach is tuning-efficient, introduces minimal overhead and avoids dense supervision. Extensive experiments on complex, multi-step scenarios show that VChain significantly enhances the quality of generated videos.
Stable Diffusion is a latent diffusion model that generates AI images from text. Instead of operating in the high-dimensional image space, it first compresses the image into the latent space.
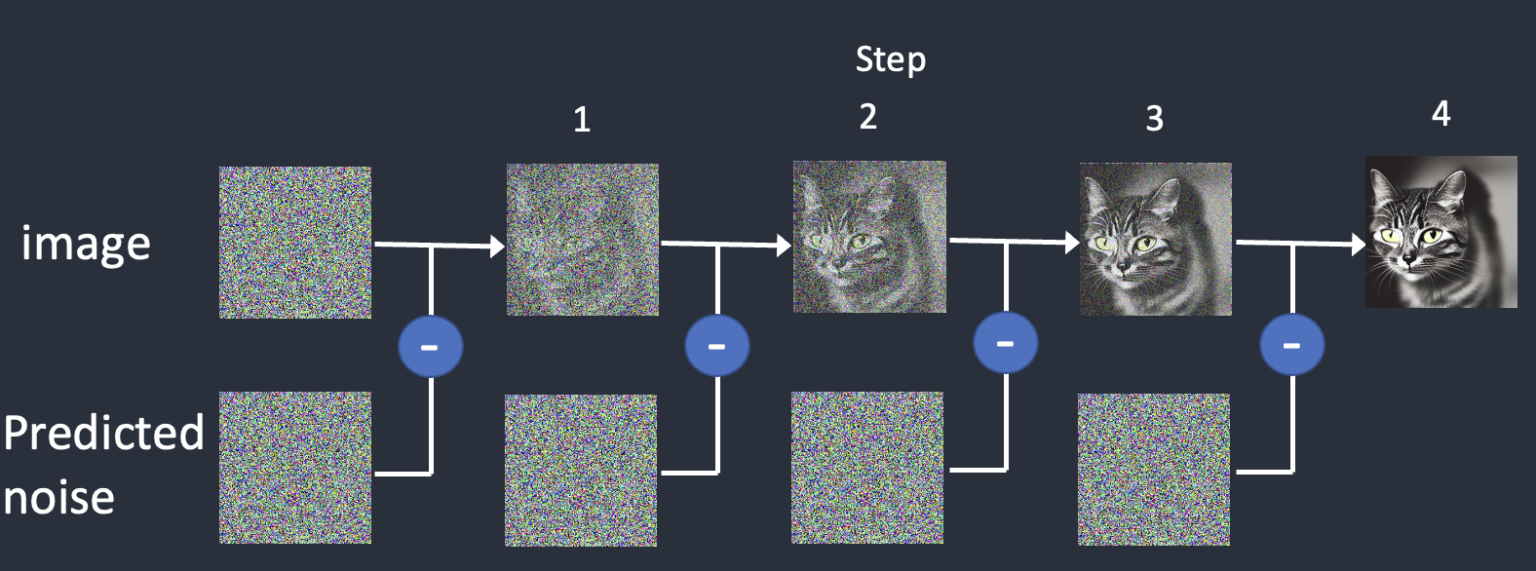
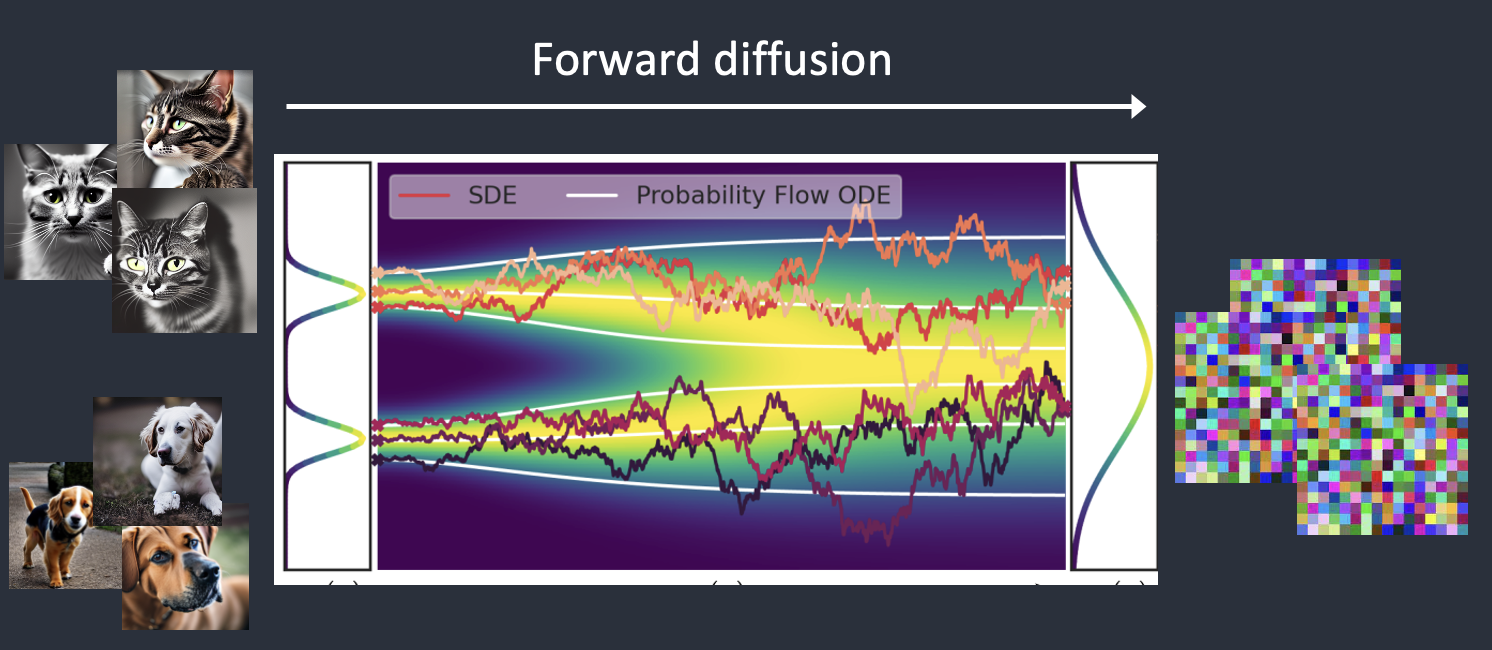
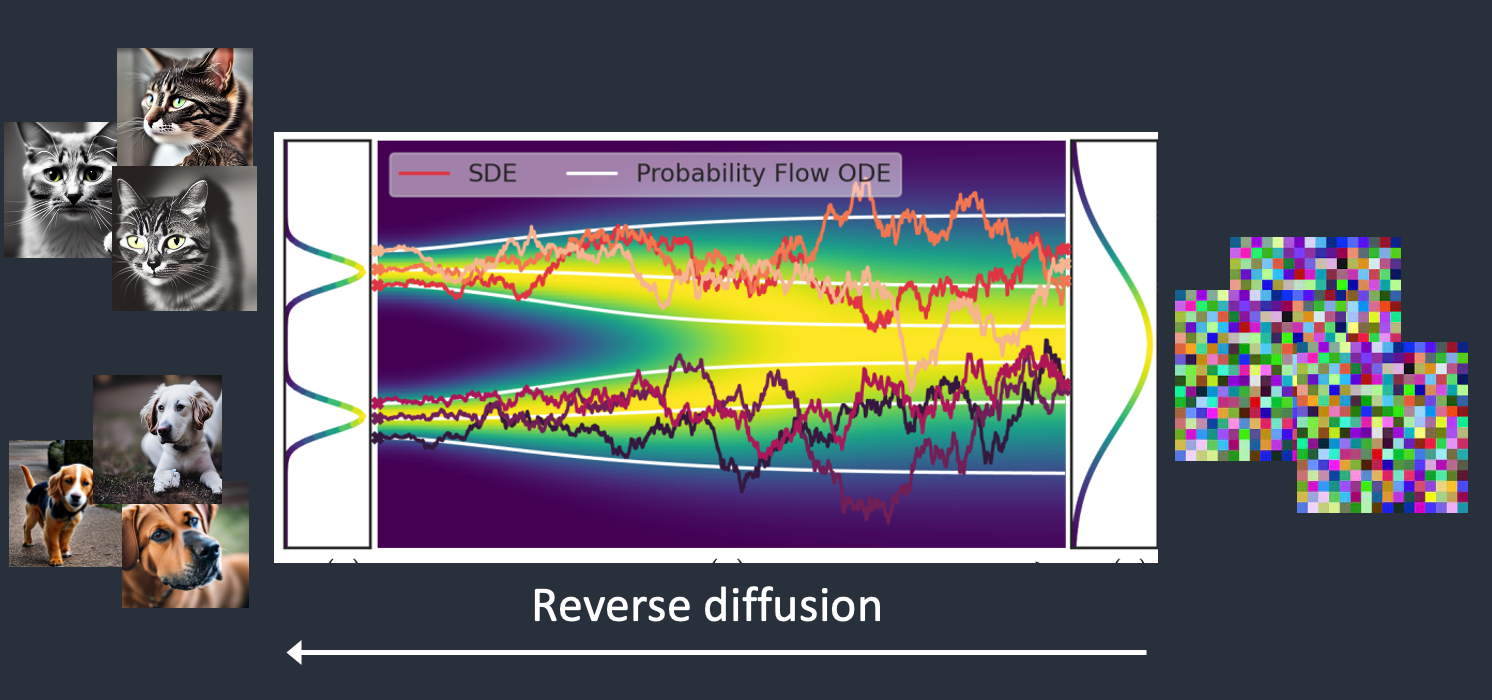
Stable Diffusion belongs to a class of deep learning models called diffusion models. They are generative models, meaning they are designed to generate new data similar to what they have seen in training. In the case of Stable Diffusion, the data are images.
Why is it called the diffusion model? Because its math looks very much like diffusion in physics. Let’s go through the idea.