𝐌𝐞𝐭𝐚 𝐇𝐲𝐩𝐞𝐫𝐬𝐜𝐚𝐩𝐞 𝐢𝐧 𝐚 𝐧𝐮𝐭𝐬𝐡𝐞𝐥𝐥
Hyperscape technology allows us to scan spaces with just a phone and create photorealistic replicas of the physical world with high fidelity. You can experience these digital replicas on the Quest 3 or on the just announced Quest 3S.
𝐇𝐢𝐠𝐡 𝐅𝐢𝐝𝐞𝐥𝐢𝐭𝐲 𝐄𝐧𝐚𝐛𝐥𝐞𝐬 𝐚 𝐍𝐞𝐰 𝐒𝐞𝐧𝐬𝐞 𝐨𝐟 𝐏𝐫𝐞𝐬𝐞𝐧𝐜𝐞
This level of photorealism will enable a new way to be together, where spaces look, sound, and feel like you are physically there.
𝐒𝐢𝐦𝐩𝐥𝐞 𝐂𝐚𝐩𝐭𝐮𝐫𝐞 𝐩𝐫𝐨𝐜𝐞𝐬𝐬 𝐰𝐢𝐭𝐡 𝐲𝐨𝐮𝐫 𝐦𝐨𝐛𝐢𝐥𝐞 𝐩𝐡𝐨𝐧𝐞
Currently not available, but in the future, it will offer a new way to create worlds in Horizon and will be the easiest way to bring physical spaces to the digital world. Creators can capture physical environments on their mobile device and invite friends, fans, or customers to visit and engage in the digital replicas.
𝐂𝐥𝐨𝐮𝐝-𝐛𝐚𝐬𝐞𝐝 𝐏𝐫𝐨𝐜𝐞𝐬𝐬𝐢𝐧𝐠 𝐚𝐧𝐝 𝐑𝐞𝐧𝐝𝐞𝐫𝐢𝐧𝐠
Using Gaussian Splatting, a 3D modeling technique that renders fine details with high accuracy and efficiency, we process the model input data in the cloud and render the created model through cloud rendering and streaming on Quest 3 and the just announced Quest 3S.
𝐓𝐫𝐲 𝐢𝐭 𝐨𝐮𝐭 𝐲𝐨𝐮𝐫𝐬𝐞𝐥𝐟
If you are in the US and you have a Meta Quest 3 or 3S you can try it out here:
In the next couple of decades, we will be able to do things that would have seemed like magic to our grandparents.
This phenomenon is not new, but it will be newly accelerated. People have become dramatically more capable over time; we can already accomplish things now that our predecessors would have believed to be impossible.
We are more capable not because of genetic change, but because we benefit from the infrastructure of society being way smarter and more capable than any one of us; in an important sense, society itself is a form of advanced intelligence. Our grandparents – and the generations that came before them – built and achieved great things. They contributed to the scaffolding of human progress that we all benefit from. AI will give people tools to solve hard problems and help us add new struts to that scaffolding that we couldn’t have figured out on our own. The story of progress will continue, and our children will be able to do things we can’t.
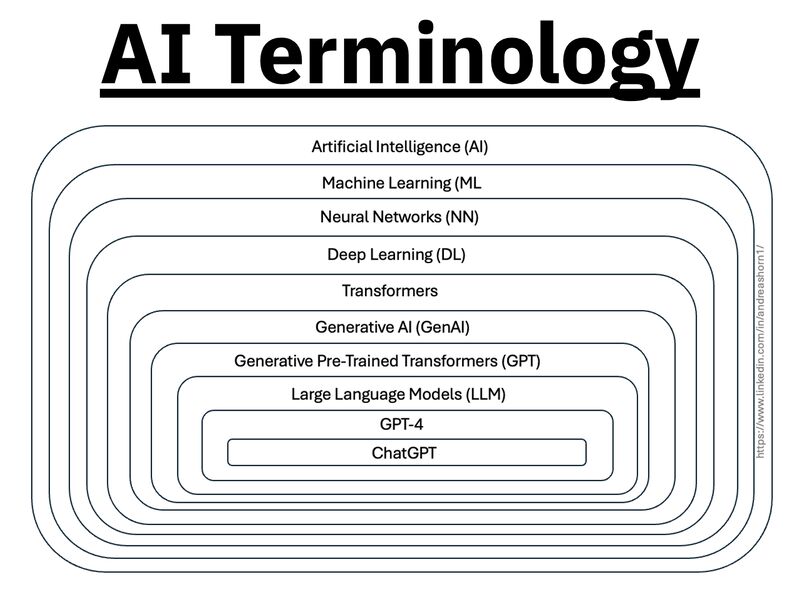
1️⃣ 𝗔𝗿𝘁𝗶𝗳𝗶𝗰𝗶𝗮𝗹 𝗜𝗻𝘁𝗲𝗹𝗹𝗶𝗴𝗲𝗻𝗰𝗲 (𝗔𝗜) – The broadest category, covering automation, reasoning, and decision-making. Early AI was rule-based, but today, it’s mainly data-driven. 2️⃣ 𝗠𝗮𝗰𝗵𝗶𝗻𝗲 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 (𝗠𝗟) – AI that learns patterns from data without explicit programming. Includes decision trees, clustering, and regression models. 3️⃣ 𝗡𝗲𝘂𝗿𝗮𝗹 𝗡𝗲𝘁𝘄𝗼𝗿𝗸𝘀 (𝗡𝗡) – A subset of ML, inspired by the human brain, designed for pattern recognition and feature extraction. 4️⃣ 𝗗𝗲𝗲𝗽 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 (𝗗𝗟) – Multi-layered neural networks that drives a lot of modern AI advancements, for example enabling image recognition, speech processing, and more. 5️⃣ 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗲𝗿𝘀 – A revolutionary deep learning architecture introduced by Google in 2017 that allows models to understand and generate language efficiently. 6️⃣ 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝘃𝗲 𝗔𝗜 (𝗚𝗲𝗻𝗔𝗜) – AI that doesn’t just analyze data—it creates. From text and images to music and code, this layer powers today’s most advanced AI models. 7️⃣ 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝘃𝗲 𝗣𝗿𝗲-𝗧𝗿𝗮𝗶𝗻𝗲𝗱 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗲𝗿𝘀 (𝗚𝗣𝗧) – A specific subset of Generative AI that uses transformers for text generation. 8️⃣ 𝗟𝗮𝗿𝗴𝗲 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹𝘀 (𝗟𝗟𝗠) – Massive AI models trained on extensive datasets to understand and generate human-like language. 9️⃣ 𝗚𝗣𝗧-4 – One of the most advanced LLMs, built on transformer architecture, trained on vast datasets to generate human-like responses. 🔟 𝗖𝗵𝗮𝘁𝗚𝗣𝗧 – A specific application of GPT-4, optimized for conversational AI and interactive use.
Recent video generation models can produce smooth and visually appealing clips, but they often struggle to synthesize complex dynamics with a coherent chain of consequences. Accurately modeling visual outcomes and state transitions over time remains a core challenge. In contrast, large language and multimodal models (e.g., GPT-4o) exhibit strong visual state reasoning and future prediction capabilities. To bridge these strengths, we introduce VChain, a novel inference-time chain-of-visual-thought framework that injects visual reasoning signals from multimodal models into video generation. Specifically, VChain contains a dedicated pipeline that leverages large multimodal models to generate a sparse set of critical keyframes as snapshots, which are then used to guide the sparse inference-time tuning of a pre-trained video generator only at these key moments. Our approach is tuning-efficient, introduces minimal overhead and avoids dense supervision. Extensive experiments on complex, multi-step scenarios show that VChain significantly enhances the quality of generated videos.