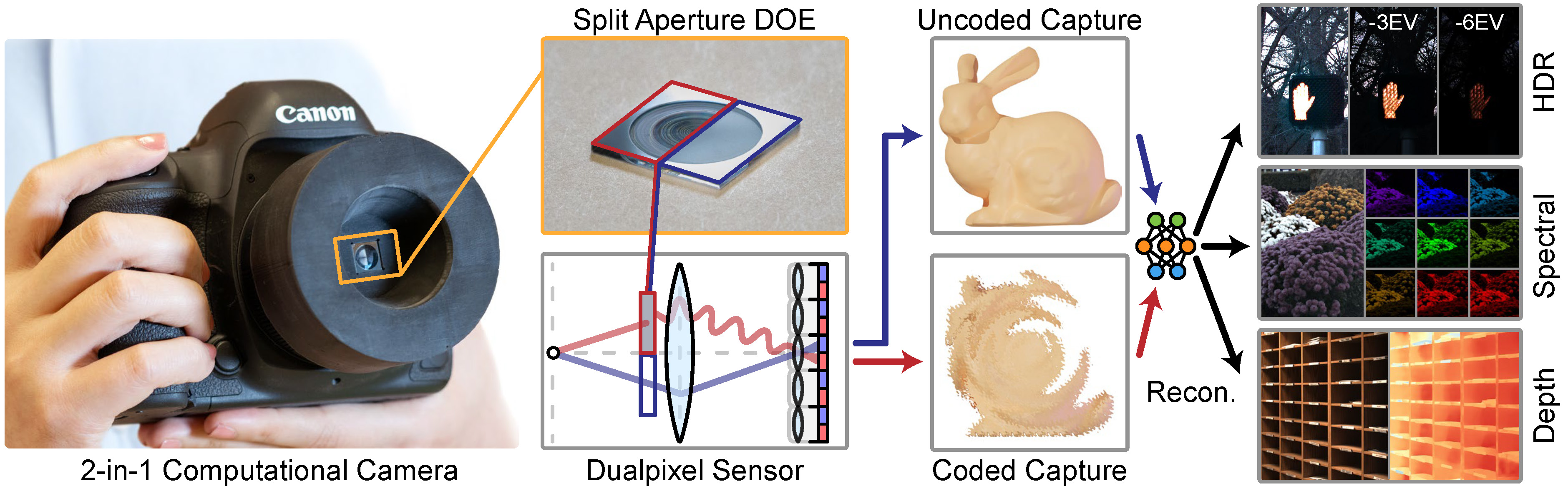
“We combine these two optical systems in a single camera by splitting the aperture: one half applies application-specific modulation using a diffractive optical element, and the other captures a conventional image. This co-design with a dual-pixel sensor allows simultaneous capture of coded and uncoded images — without increasing physical or computational footprint.”
The EU Artificial Intelligence (AI) Act, which went into effect on August 1, 2024.
This act implements a risk-based approach to AI regulation, categorizing AI systems based on the level of risk they pose. High-risk systems, such as those used in healthcare, transport, and law enforcement, face stringent requirements, including risk management, transparency, and human oversight.
Key provisions of the AI Act include:
Transparency and Safety Requirements: AI systems must be designed to be safe, transparent, and easily understandable to users. This includes labeling requirements for AI-generated content, such as deepfakes (Engadget).
Risk Management and Compliance: Companies must establish comprehensive governance frameworks to assess and manage the risks associated with their AI systems. This includes compliance programs that cover data privacy, ethical use, and geographical considerations (Faegre Drinker Biddle & Reath LLP) (Passle).
Copyright and Data Mining: Companies must adhere to copyright laws when training AI models, obtaining proper authorization from rights holders for text and data mining unless it is for research purposes (Engadget).
Prohibitions and Restrictions: AI systems that manipulate behavior, exploit vulnerabilities, or perform social scoring are prohibited. The act also sets out specific rules for high-risk AI applications and imposes fines for non-compliance (Passle).
For US tech firms, compliance with the EU AI Act is critical due to the EU’s significant market size
FLUX (or FLUX. 1) is a suite of text-to-image models from Black Forest Labs, a new company set up by some of the AI researchers behind innovations and models like VQGAN, Stable Diffusion, Latent Diffusion, and Adversarial Diffusion Distillation
Tneration models can create high-quality images from input prompts. However, they struggle to support the consistent generation of identity-preserving requirements for storytelling.
Our approach 1Prompt1Story concatenates all prompts into a single input for T2I diffusion models, initially preserving character identities.
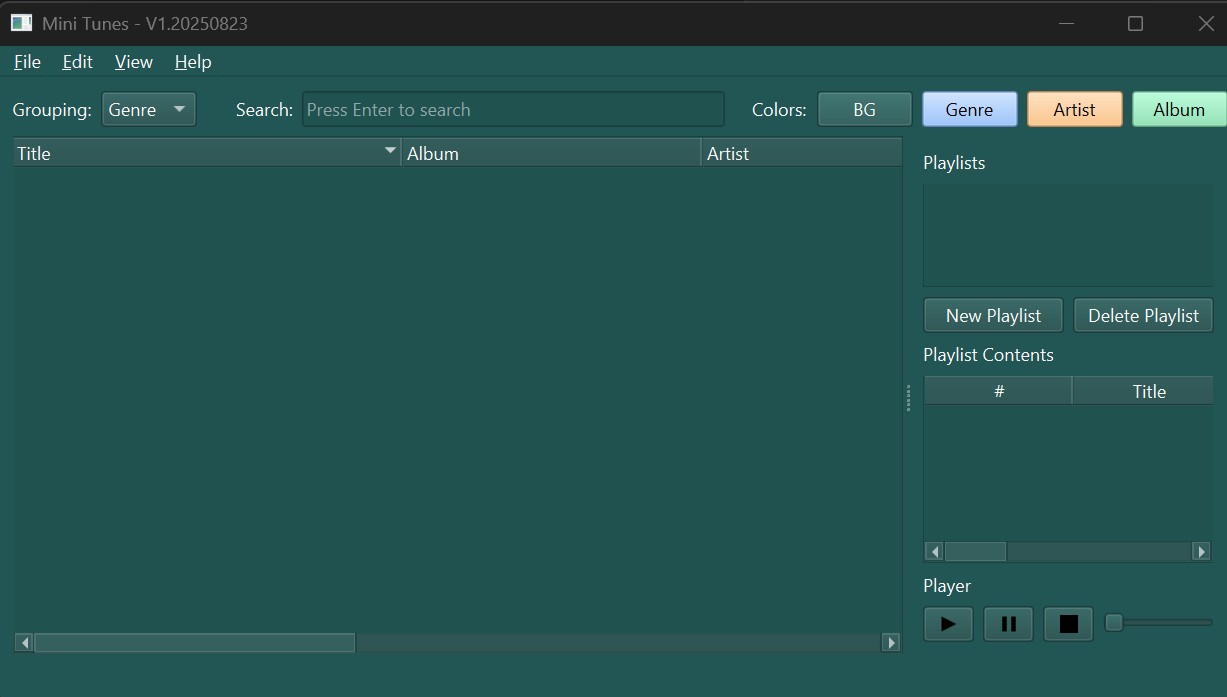
Tired of having iTunes messing up your mp3 library? … Time to try MiniTunes!
– Arrange your library by Genre, Artists or Albums. – Change UI colors at will. – Edit tags and create playlists. – Consolidate your library once for all. – Windows 64 only
Recent video generation models can produce smooth and visually appealing clips, but they often struggle to synthesize complex dynamics with a coherent chain of consequences. Accurately modeling visual outcomes and state transitions over time remains a core challenge. In contrast, large language and multimodal models (e.g., GPT-4o) exhibit strong visual state reasoning and future prediction capabilities. To bridge these strengths, we introduce VChain, a novel inference-time chain-of-visual-thought framework that injects visual reasoning signals from multimodal models into video generation. Specifically, VChain contains a dedicated pipeline that leverages large multimodal models to generate a sparse set of critical keyframes as snapshots, which are then used to guide the sparse inference-time tuning of a pre-trained video generator only at these key moments. Our approach is tuning-efficient, introduces minimal overhead and avoids dense supervision. Extensive experiments on complex, multi-step scenarios show that VChain significantly enhances the quality of generated videos.