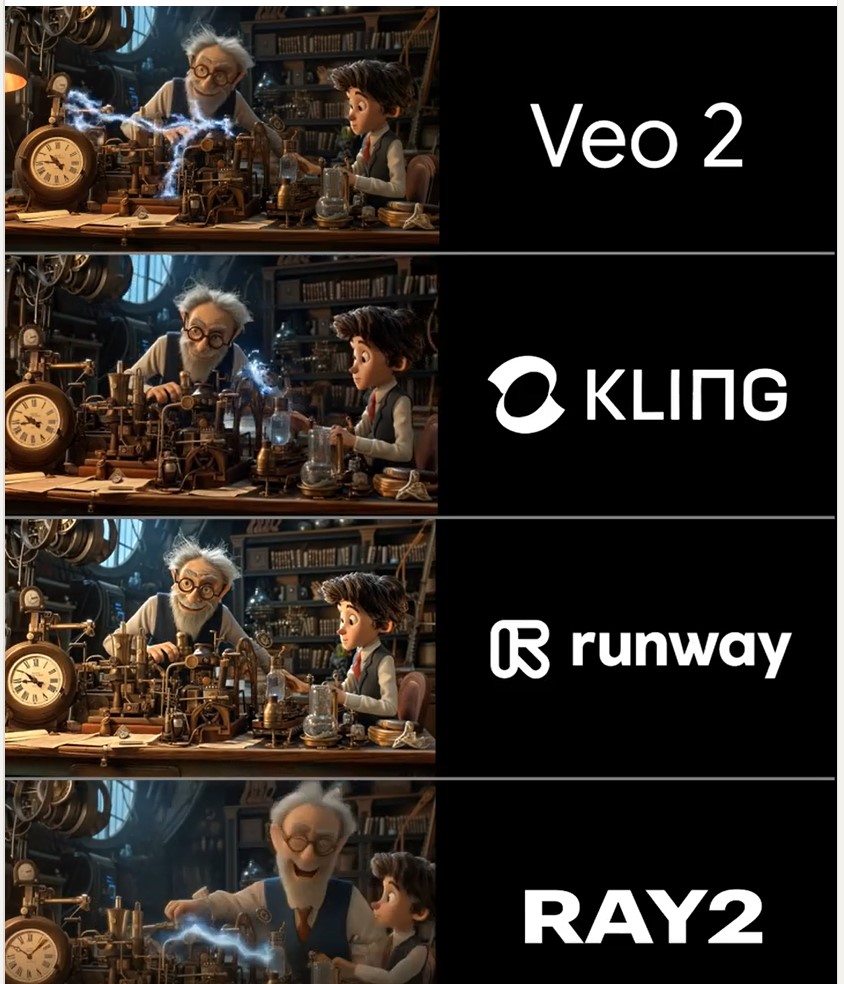
🔹 𝗩𝗲𝗼 2 – After the legendary prompt adherence of Veo 2 T2V, I have to say I2V is a little disappointing, especially when it comes to camera moves. You often get those Sora-like jump-cuts too which can be annoying.
🔹 𝗞𝗹𝗶𝗻𝗴 1.6 Pro – Still the one to beat for I2V, both for image quality and prompt adherence. It’s also a lot cheaper than Veo 2. Generations can be slow, but are usually worth the wait.
🔹 𝗥𝘂𝗻𝘄𝗮𝘆 Gen 3 – Useful for certain shots, but overdue an update. The worst performer here by some margin. Bring on Gen 4!
🔹 𝗟𝘂𝗺𝗮 Ray 2 – I love the energy and inventiveness Ray 2 brings, but those came with some image quality issues. I want to test more with this model though for sure.
RigAnything was developed through a collaboration between UC San Diego, Adobe Research, and Hillbot Inc. It addresses one of 3D animation’s most persistent challenges: automatic rigging.
Template-Free Autoregressive Rigging. A transformer-based model that sequentially generates skeletons without predefined templates, enabling automatic rigging across diverse 3D assets through probabilistic joint prediction and skinning weight assignment.
Support Arbitrary Input Pose. Generates high-quality skeletons for shapes in any pose through online joint pose augmentation during training, eliminating the common rest-pose requirement of existing methods and enabling broader real-world applications.
Fast Rigging Speed. Achieves 20x faster performance than existing template-based methods, completing rigging in under 2 seconds per shape.
All-in-one AI platform for video creation, including voiceover, lipsync, SFX, and editing. One click turn text to video & image to video. Turns idea into stunning video in minutes. Check Pricing Details. Start For Free. All-In-One Platform.
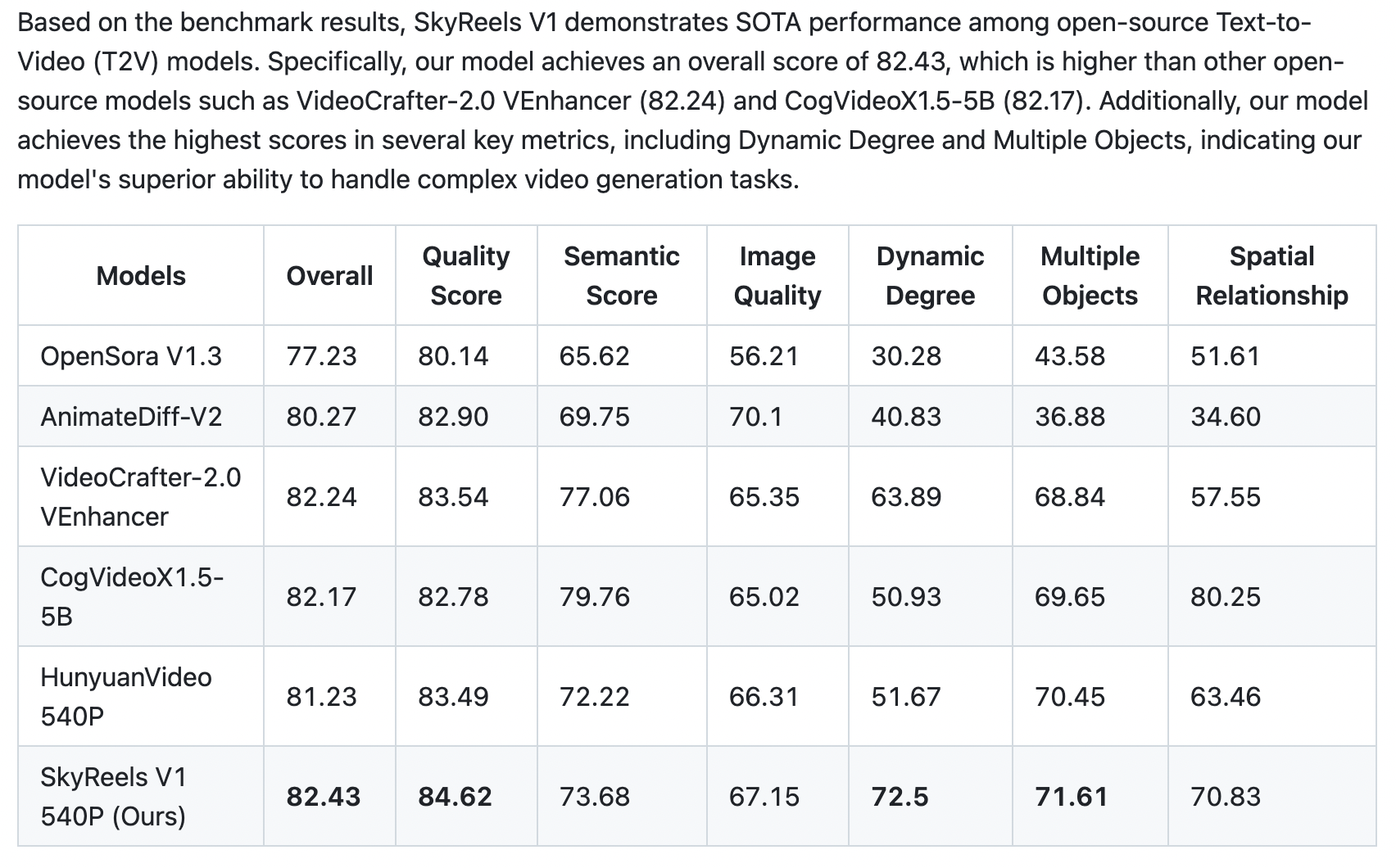
SkyReels-V1 is purpose-built for AI short video production based on Hynyuan. It achieves cinematic-grade micro-expression performances with 33 nuanced facial expressions and 400+ natural body movements that can be freely combined. The model integrates film-quality lighting aesthetics, generating visually stunning compositions and textures through text-to-video or image-to-video conversion – outperforming all existing open-source models across key metrics.
The model generates videos up to 204 frames, using a high-compression Video-VAE (16×16 spatial, 8x temporal). It processes English and Chinese prompts via bilingual text encoders. A 3D full-attention DiT, trained with Flow Matching, denoises latent frames conditioned on text and timesteps. A video-based DPO further reduces artifacts, enhancing realism and smoothness.