Deepfake technology is a type of artificial intelligence used to create convincing fake images, videos and audio recordings. The term describes both the technology and the resulting bogus content and is a portmanteau of deep learning and fake.
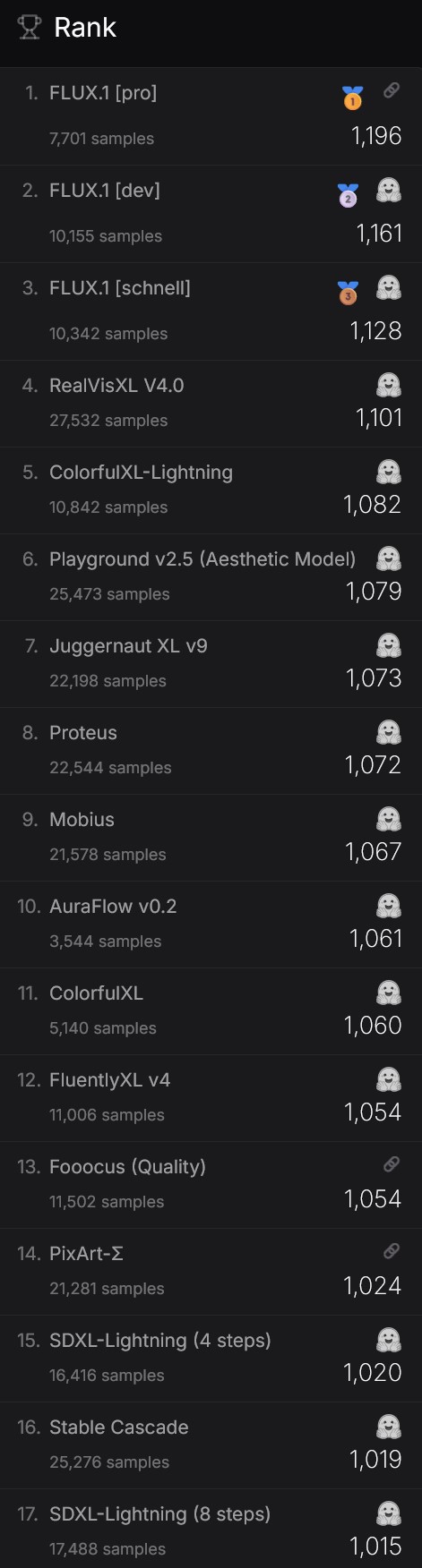
Deepfakes often transform existing source content where one person is swapped for another. They also create entirely original content where someone is represented doing or saying something they didn’t do or say.
Deepfakes aren’t edited or photoshopped videos or images. In fact, they’re created using specialized algorithms that blend existing and new footage. For example, subtle facial features of people in images are analyzed through machine learning (ML) to manipulate them within the context of other videos.
Deepfakes uses two algorithms — a generator and a discriminator — to create and refine fake content. The generator builds a training data set based on the desired output, creating the initial fake digital content, while the discriminator analyzes how realistic or fake the initial version of the content is. This process is repeated, enabling the generator to improve at creating realistic content and the discriminator to become more skilled at spotting flaws for the generator to correct.
The combination of the generator and discriminator algorithms creates a generative adversarial network.
A GANuses deep learning to recognize patterns in real images and then uses those patterns to create the fakes.
When creating a deepfake photograph, a GAN system views photographs of the target from an array of angles to capture all the details and perspectives. When creating a deepfake video, the GAN views the video from various angles and analyzes behavior, movement and speech patterns. This information is then run through the discriminator multiple times to fine-tune the realism of the final image or video.
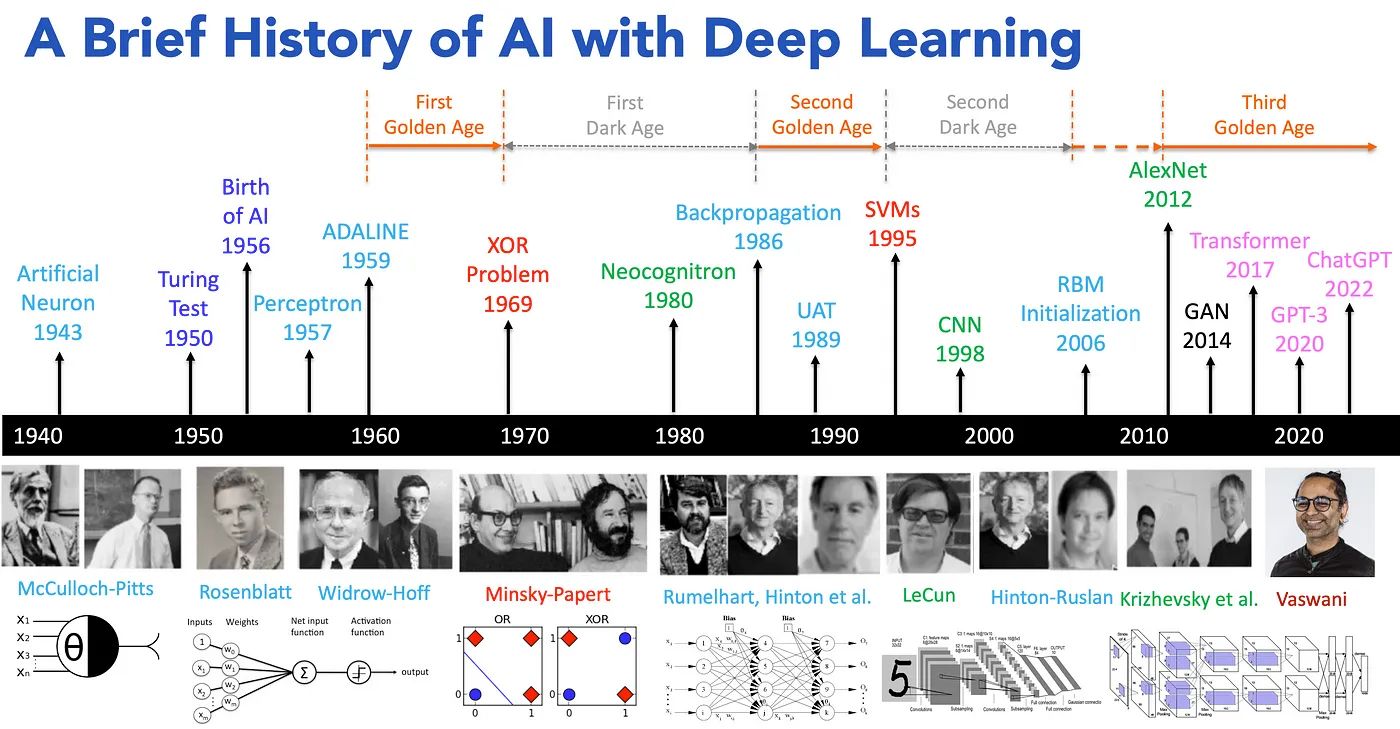
🔹 1943: 𝗠𝗰𝗖𝘂𝗹𝗹𝗼𝗰𝗵 & 𝗣𝗶𝘁𝘁𝘀 create the first artificial neuron. 🔹 1950: 𝗔𝗹𝗮𝗻 𝗧𝘂𝗿𝗶𝗻𝗴 introduces the Turing Test, forever changing the way we view intelligence. 🔹 1956: 𝗝𝗼𝗵𝗻 𝗠𝗰𝗖𝗮𝗿𝘁𝗵𝘆 coins the term “Artificial Intelligence,” marking the official birth of the field. 🔹 1957: 𝗙𝗿𝗮𝗻𝗸 𝗥𝗼𝘀𝗲𝗻𝗯𝗹𝗮𝘁𝘁 invents the Perceptron, one of the first neural networks. 🔹 1959: 𝗕𝗲𝗿𝗻𝗮𝗿𝗱 𝗪𝗶𝗱𝗿𝗼𝘄 and 𝗧𝗲𝗱 𝗛𝗼𝗳𝗳 create ADALINE, a model that would shape neural networks. 🔹 1969: 𝗠𝗶𝗻𝘀𝗸𝘆 & 𝗣𝗮𝗽𝗲𝗿𝘁 solve the XOR problem, but also mark the beginning of the “first AI winter.” 🔹 1980: 𝗞𝘂𝗻𝗶𝗵𝗶𝗸𝗼 𝗙𝘂𝗸𝘂𝘀𝗵𝗶𝗺𝗮 introduces Neocognitron, laying the groundwork for deep learning. 🔹 1986: 𝗚𝗲𝗼𝗳𝗳𝗿𝗲𝘆 𝗛𝗶𝗻𝘁𝗼𝗻 and 𝗗𝗮𝘃𝗶𝗱 𝗥𝘂𝗺𝗲𝗹𝗵𝗮𝗿𝘁 introduce backpropagation, making neural networks viable again. 🔹 1989: 𝗝𝘂𝗱𝗲𝗮 𝗣𝗲𝗮𝗿𝗹 advances UAT (Understanding and Reasoning), building a foundation for AI’s logical abilities. 🔹 1995: 𝗩𝗹𝗮𝗱𝗶𝗺𝗶𝗿 𝗩𝗮𝗽𝗻𝗶𝗸 and 𝗖𝗼𝗿𝗶𝗻𝗻𝗮 𝗖𝗼𝗿𝘁𝗲𝘀 develop Support Vector Machines (SVMs), a breakthrough in machine learning. 🔹 1998: 𝗬𝗮𝗻𝗻 𝗟𝗲𝗖𝘂𝗻 popularizes Convolutional Neural Networks (CNNs), revolutionizing image recognition. 🔹 2006: 𝗚𝗲𝗼𝗳𝗳𝗿𝗲𝘆 𝗛𝗶𝗻𝘁𝗼𝗻 and 𝗥𝘂𝘀𝗹𝗮𝗻 𝗦𝗮𝗹𝗮𝗸𝗵𝘂𝘁𝗱𝗶𝗻𝗼𝘃 introduce deep belief networks, reigniting interest in deep learning. 🔹 2012: 𝗔𝗹𝗲𝘅 𝗞𝗿𝗶𝘇𝗵𝗲𝘃𝘀𝗸𝘆 and 𝗚𝗲𝗼𝗳𝗳𝗿𝗲𝘆 𝗛𝗶𝗻𝘁𝗼𝗻 launch AlexNet, sparking the modern AI revolution in deep learning. 🔹 2014: 𝗜𝗮𝗻 𝗚𝗼𝗼𝗱𝗳𝗲𝗹𝗹𝗼𝘄 introduces Generative Adversarial Networks (GANs), opening new doors for AI creativity. 🔹 2017: 𝗔𝘀𝗵𝗶𝘀𝗵 𝗩𝗮𝘀𝘄𝗮𝗻𝗶 and team introduce Transformers, redefining natural language processing (NLP). 🔹 2020: OpenAI unveils GPT-3, setting a new standard for language models and AI’s capabilities. 🔹 2022: OpenAI releases ChatGPT, democratizing conversational AI and bringing it to the masses.
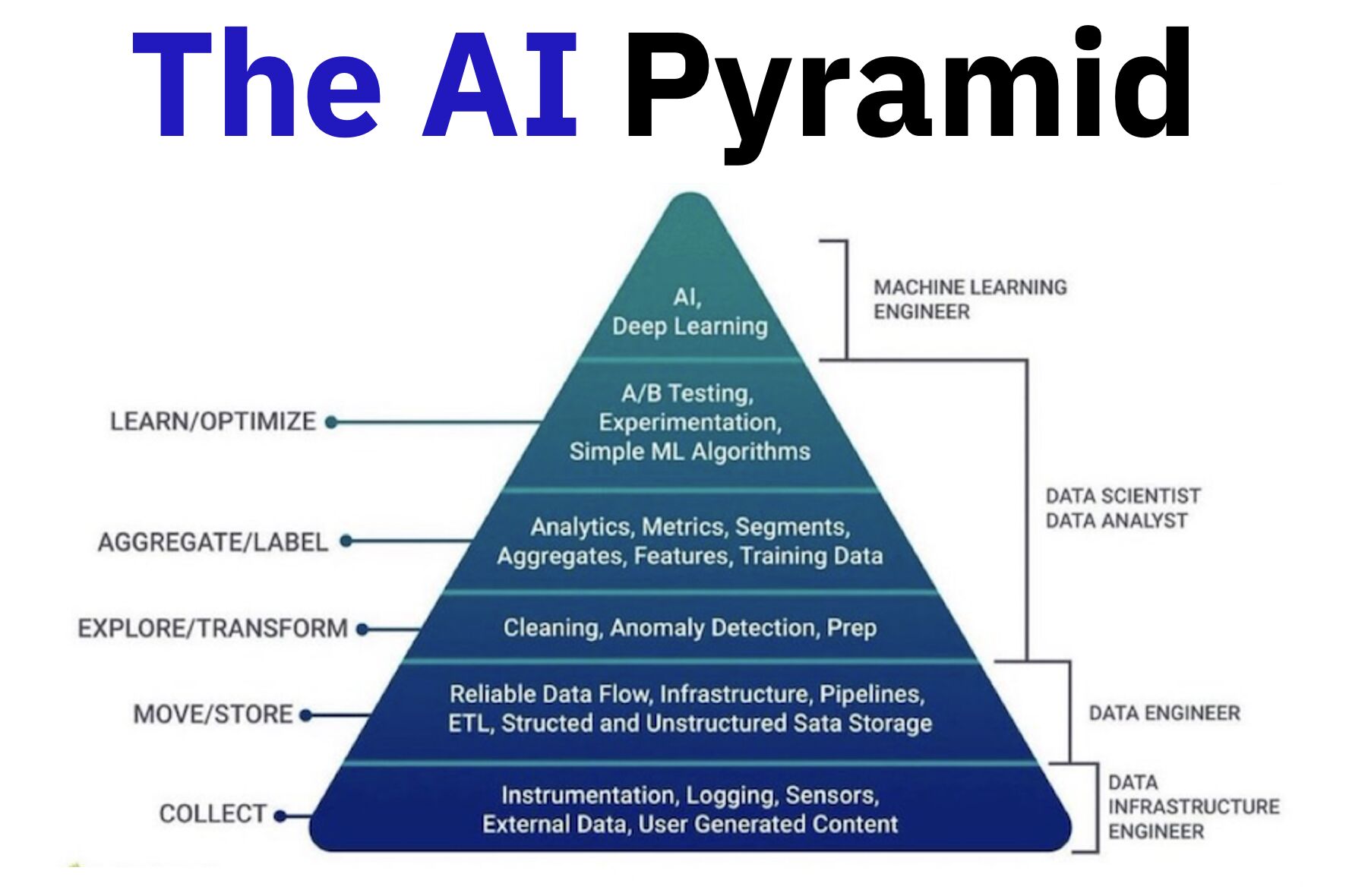
– Collect: Data from sensors, logs, and user input. – Move/Store: Build infrastructure, pipelines, and reliable data flow. – Explore/Transform: Clean, prep, and detect anomalies to make the data usable. – Aggregate/Label: Add analytics, metrics, and labels to create training data. – Learn/Optimize: Experiment, test, and train AI models.
– Instrumentation and logging: Sensors, logs, and external data capture the raw inputs. – Data flow and storage: Pipelines and infrastructure ensure smooth movement and reliable storage. – Exploration and transformation: Data is cleaned, prepped, and anomalies are detected. – Aggregation and labeling: Analytics, metrics, and labels create structured, usable datasets. – Experimenting/AI/ML: Models are trained and optimized using the prepared data. – AI insights and actions: Advanced AI generates predictions, insights, and decisions at the top.
𝗪𝗵𝗼 𝗺𝗮𝗸𝗲𝘀 𝗶𝘁 𝗵𝗮𝗽𝗽𝗲𝗻 𝗮𝗻𝗱 𝗸𝗲𝘆 𝗿𝗼𝗹𝗲𝘀:
– Data Infrastructure Engineers: Build the foundation — collect, move, and store data. – Data Engineers: Prep and transform the data into usable formats. – Data Analysts & Scientists: Aggregate, label, and generate insights. – Machine Learning Engineers: Optimize and deploy AI models.
Basically, gamma is the relationship between the brightness of a pixel as it appears on the screen, and the numerical value of that pixel. Generally Gamma is just about defining relationships.
Three main types: – Image Gamma encoded in images – Display Gammas encoded in hardware and/or viewing time – System or Viewing Gamma which is the net effect of all gammas when you look back at a final image. In theory this should flatten back to 1.0 gamma.
The dynamic range is a ratio between the maximum and minimum values of a physical measurement. Its definition depends on what the dynamic range refers to.
For a scene: Dynamic range is the ratio between the brightest and darkest parts of the scene.
For a camera: Dynamic range is the ratio of saturation to noise. More specifically, the ratio of the intensity that just saturates the camera to the intensity that just lifts the camera response one standard deviation above camera noise.
For a display: Dynamic range is the ratio between the maximum and minimum intensities emitted from the screen.
The Dynamic Range of real-world scenes can be quite high — ratios of 100,000:1 are common in the natural world. An HDR (High Dynamic Range) image stores pixel values that span the whole tonal range of real-world scenes. Therefore, an HDR image is encoded in a format that allows the largest range of values, e.g. floating-point values stored with 32 bits per color channel. Another characteristics of an HDR image is that it stores linear values. This means that the value of a pixel from an HDR image is proportional to the amount of light measured by the camera.
For TVs HDR is great, but it’s not the only new TV feature worth discussing.