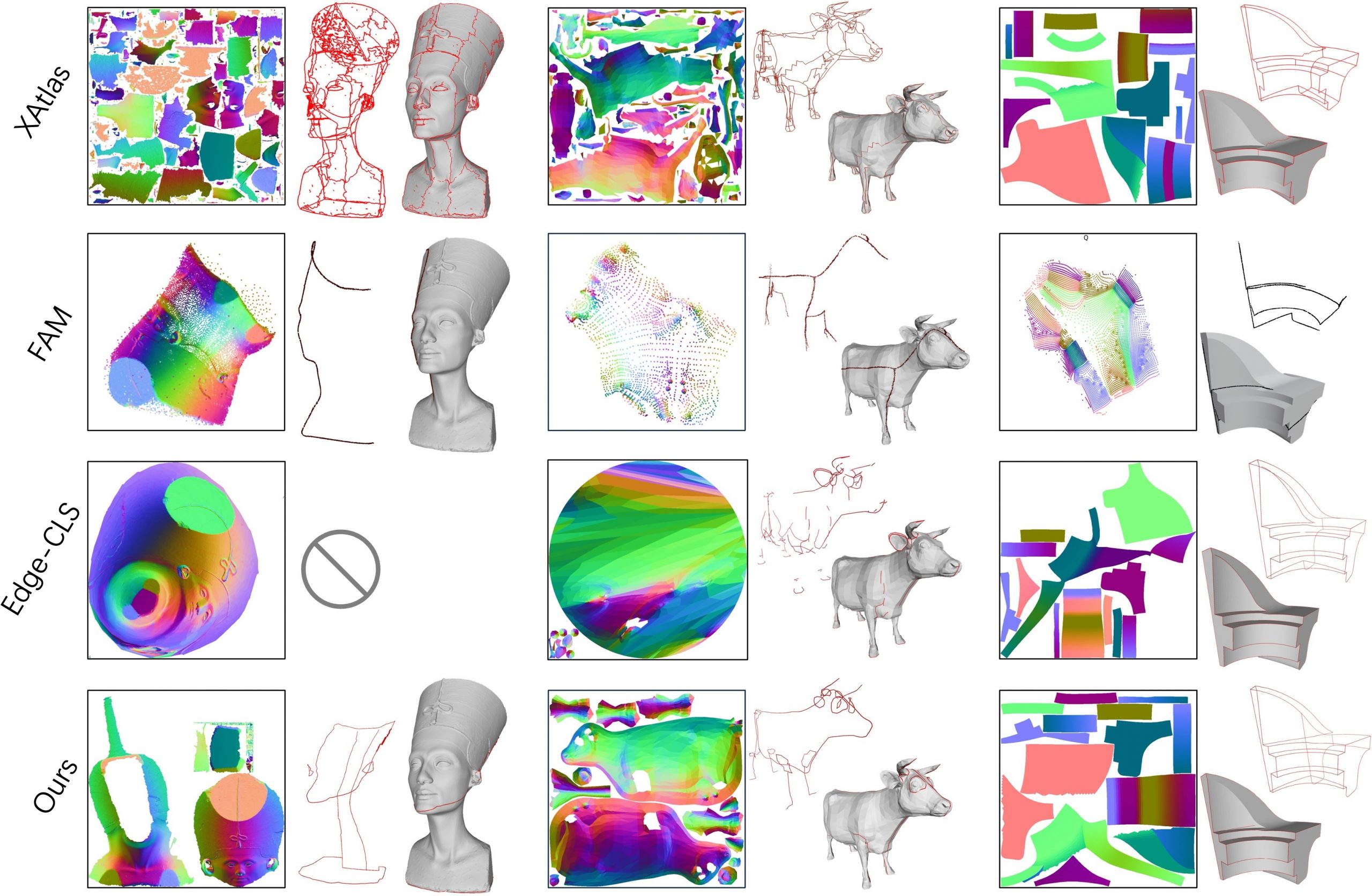
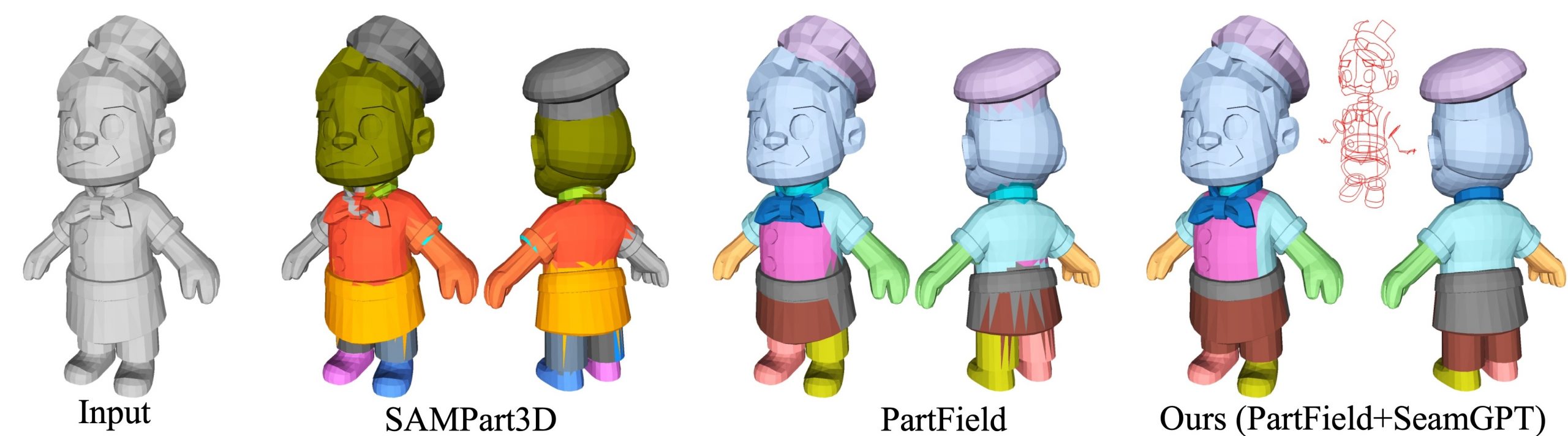
Our human-centric dense prediction model delivers high-quality, detailed (depth) results while achieving remarkable efficiency, running orders of magnitude faster than competing methods, with inference speeds as low as 21 milliseconds per frame (the large multi-task model on an NVIDIA A100). It reliably captures a wide range of human characteristics under diverse lighting conditions, preserving fine-grained details such as hair strands and subtle facial features. This demonstrates the model’s robustness and accuracy in complex, real-world scenarios.
The state of the art in human-centric computer vision achieves high accuracy and robustness across a diverse range of tasks. The most effective models in this domain have billions of parameters, thus requiring extremely large datasets, expensive training regimes, and compute-intensive inference. In this paper, we demonstrate that it is possible to train models on much smaller but high-fidelity synthetic datasets, with no loss in accuracy and higher efficiency. Using synthetic training data provides us with excellent levels of detail and perfect labels, while providing strong guarantees for data provenance, usage rights, and user consent. Procedural data synthesis also provides us with explicit control on data diversity, that we can use to address unfairness in the models we train. Extensive quantitative assessment on real input images demonstrates accuracy of our models on three dense prediction tasks: depth estimation, surface normal estimation, and soft foreground segmentation. Our models require only a fraction of the cost of training and inference when compared with foundational models of similar accuracy.
QuickTime (.mov) files are fundamentally time-based, not frame-based, and so don’t have a built-in, uniform “first frame/last frame” field you can set as numeric frame IDs. Instead, tools like Shotgun Create rely on the timecode track and the movie’s duration to infer frame numbers. If you want Shotgun to pick up a non-default frame range (e.g. start at 1001, end at 1064), you must bake in an SMPTE timecode that corresponds to your desired start frame, and ensure the movie’s duration matches your clip length.
How Shotgun Reads Frame Ranges
Default start frame is 1. If no timecode metadata is present, Shotgun assumes the movie begins at frame 1.
Timecode ⇒ frame number. Shotgun Create “honors the timecodes of media sources,” mapping the embedded TC to frame IDs. For example, a 24 fps QuickTime tagged with a start timecode of 00:00:41:17 will be interpreted as beginning on frame 1001 (1001 ÷ 24 fps ≈ 41.71 s).
Embedding a Start Timecode
QuickTime uses a tmcd (timecode) track. You can bake in an SMPTE track via FFmpeg’s -timecode flag or via Compressor/encoder settings:
Compute your start TC.
Desired start frame = 1001
Frame 1001 at 24 fps ⇒ 1001 ÷ 24 ≈ 41.708 s ⇒ TC 00:00:41:17
Aider enables developers to interactively generate, modify, and test code by leveraging both cloud-hosted and local LLMs directly from the terminal or within an IDE. Key capabilities include comprehensive codebase mapping, support for over 100 programming languages, automated git commit messages, voice-to-code interactions, and built-in linting and testing workflows. Installation is straightforward via pip or uv, and while the tool itself has no licensing cost, actual usage costs stem from the underlying LLM APIs, which are billed separately by providers like OpenAI or Anthropic.
Key Features
Cloud & Local LLM Support Connect to most major LLM providers out of the box, or run models locally for privacy and cost control aider.chat.
Codebase Mapping Automatically indexes all project files so that even large repositories can be edited contextually aider.chat.
100+ Language Support Works with Python, JavaScript, Rust, Ruby, Go, C++, PHP, HTML, CSS, and dozens more aider.chat.
Git Integration Generates sensible commit messages and automates diffs/undo operations through familiar git tooling aider.chat.
Voice-to-Code Speak commands to Aider to request features, tests, or fixes without typing aider.chat.
Images & Web Pages Attach screenshots, diagrams, or documentation URLs to provide visual context for edits aider.chat.
Linting & Testing Runs lint and test suites automatically after each change, and can fix issues it detects
Sourcetree and GitHub Desktop are both free, GUI-based Git clients aimed at simplifying version control for developers. While they share the same core purpose—making Git more accessible—they differ in features, UI design, integration options, and target audiences.
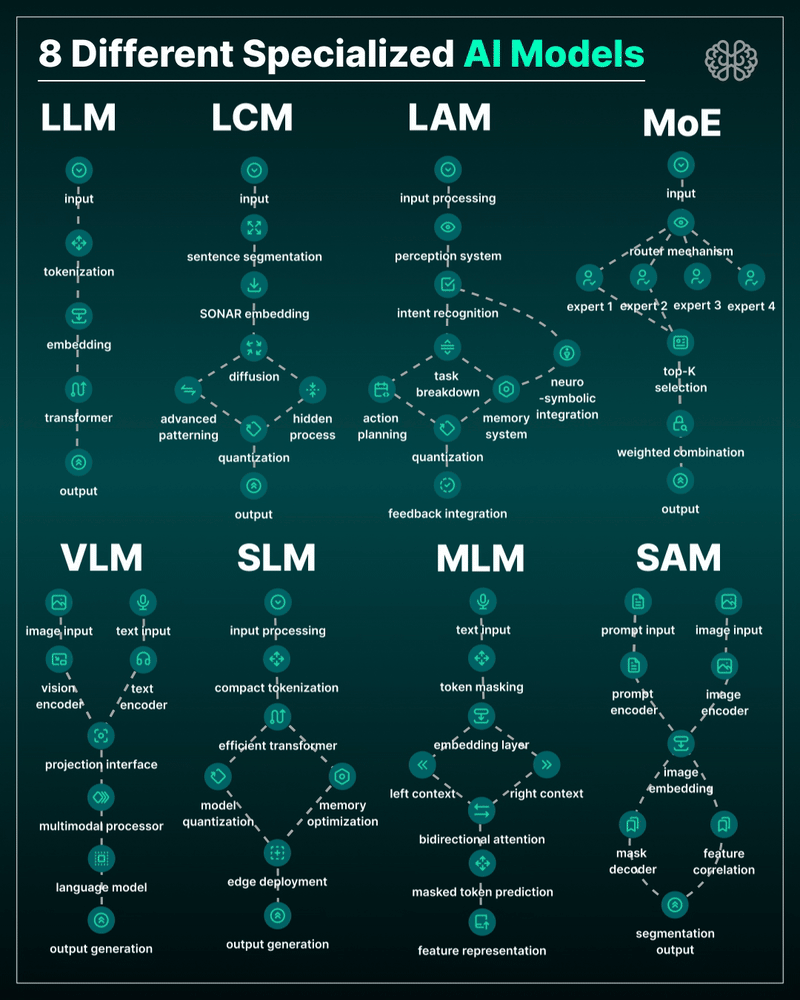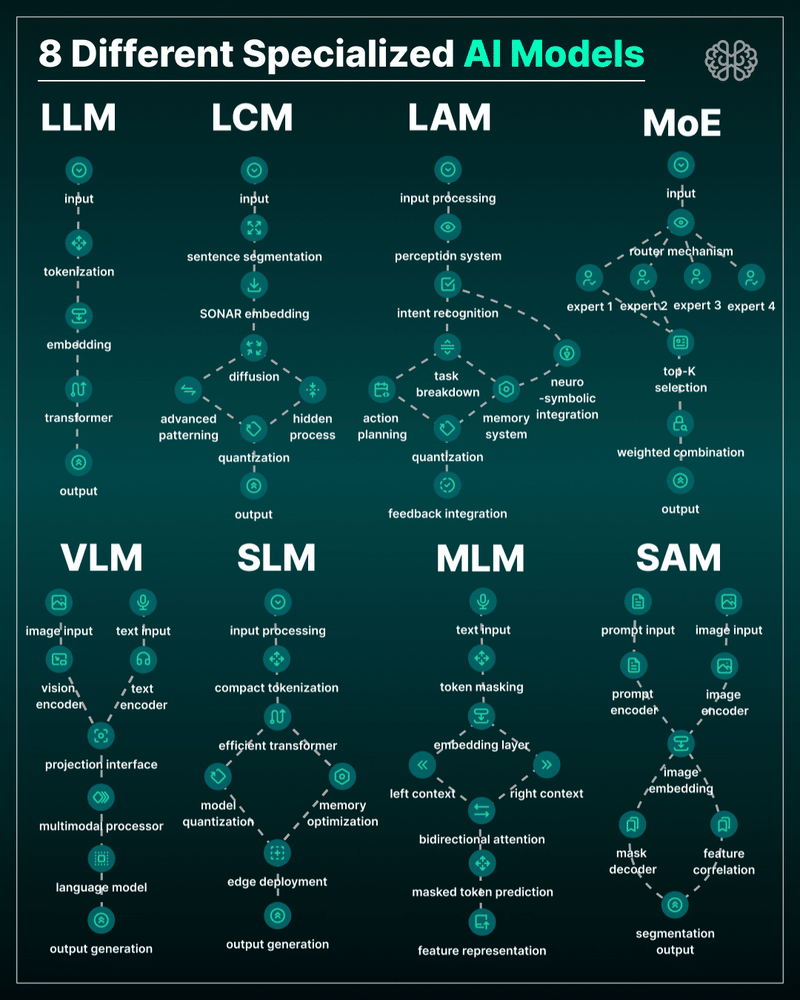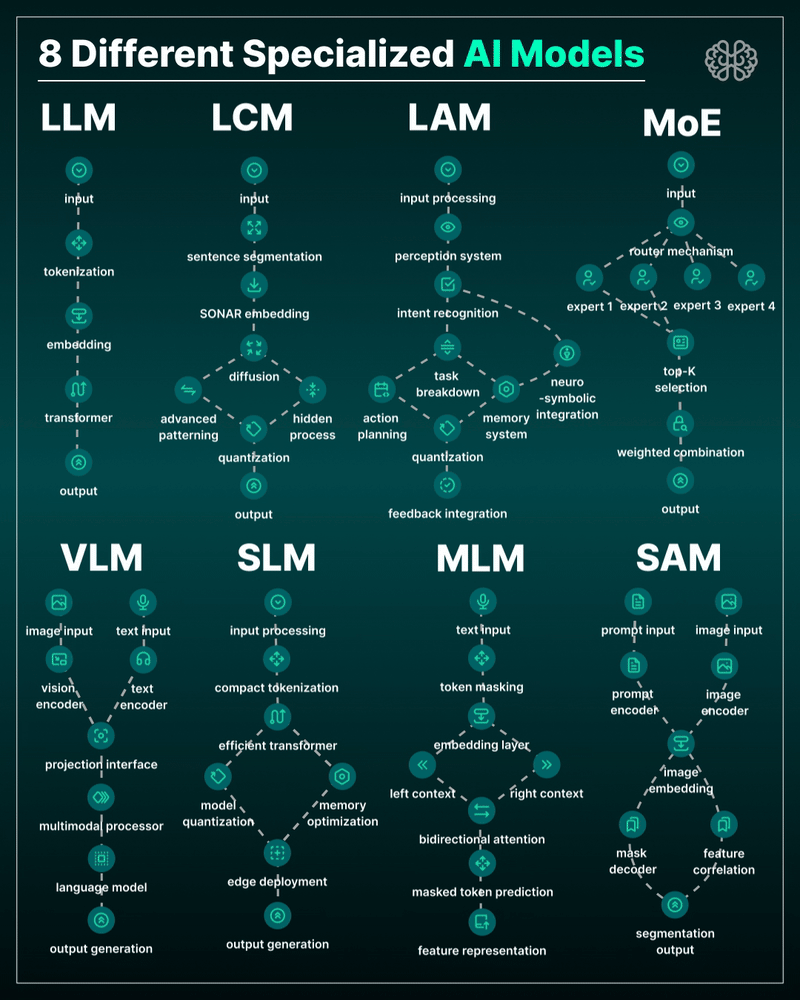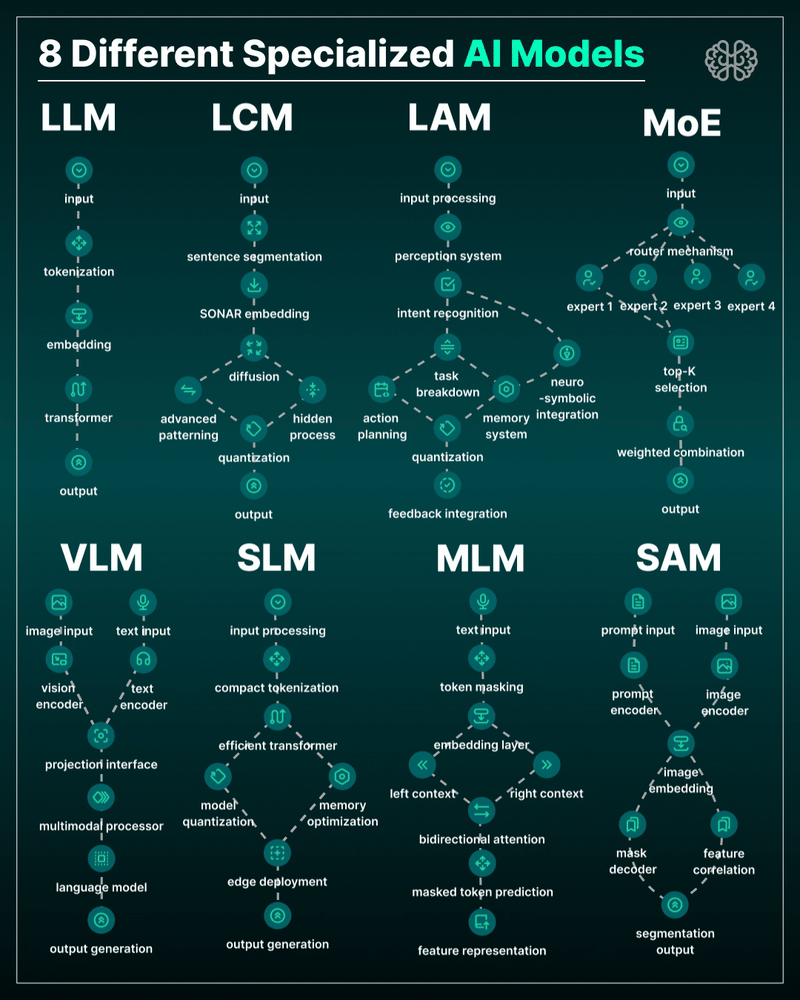
the 8 most important model types and what they’re actually built to do: ⬇️
1. 𝗟𝗟𝗠 – 𝗟𝗮𝗿𝗴𝗲 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹 → Your ChatGPT-style model. Handles text, predicts the next token, and powers 90% of GenAI hype. 🛠 Use case: content, code, convos.
2. 𝗟𝗖𝗠 – 𝗟𝗮𝘁𝗲𝗻𝘁 𝗖𝗼𝗻𝘀𝗶𝘀𝘁𝗲𝗻𝗰𝘆 𝗠𝗼𝗱𝗲𝗹 → Lightweight, diffusion-style models. Fast, quantized, and efficient — perfect for real-time or edge deployment. 🛠 Use case: image generation, optimized inference.
3. 𝗟𝗔𝗠 – 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗔𝗰𝘁𝗶𝗼𝗻 𝗠𝗼𝗱𝗲𝗹 → Where LLM meets planning. Adds memory, task breakdown, and intent recognition. 🛠 Use case: AI agents, tool use, step-by-step execution.
4. 𝗠𝗼𝗘 – 𝗠𝗶𝘅𝘁𝘂𝗿𝗲 𝗼𝗳 𝗘𝘅𝗽𝗲𝗿𝘁𝘀 → One model, many minds. Routes input to the right “expert” model slice — dynamic, scalable, efficient. 🛠 Use case: high-performance model serving at low compute cost.
5. 𝗩𝗟𝗠 – 𝗩𝗶𝘀𝗶𝗼𝗻 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹 → Multimodal beast. Combines image + text understanding via shared embeddings. 🛠 Use case: Gemini, GPT-4o, search, robotics, assistive tech.
6. 𝗦𝗟𝗠 – 𝗦𝗺𝗮𝗹𝗹 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹 → Tiny but mighty. Designed for edge use, fast inference, low latency, efficient memory. 🛠 Use case: on-device AI, chatbots, privacy-first GenAI.
7. 𝗠𝗟𝗠 – 𝗠𝗮𝘀𝗸𝗲𝗱 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹 → The OG foundation model. Predicts masked tokens using bidirectional context. 🛠 Use case: search, classification, embeddings, pretraining.
8. 𝗦𝗔𝗠 – 𝗦𝗲𝗴𝗺𝗲𝗻𝘁 𝗔𝗻𝘆𝘁𝗵𝗶𝗻𝗴 𝗠𝗼𝗱𝗲𝗹 → Vision model for pixel-level understanding. Highlights, segments, and understands *everything* in an image. 🛠 Use case: medical imaging, AR, robotics, visual agents.
🔸 Gaussian Splats: imagine throwing thousands of tiny ellipsoidal paint drops. They overlap, blend, and create a smooth, photorealistic look. Fast, great for visualization, but less structured for measurements.
🔸 Point Clouds: every dot is a measured hit. LiDAR or photogrammetry gives us millions of them forming a constellation of reality. Amazing for accuracy, but they don’t connect the dots out of the box.
🔸 Meshes: take those points, connect them into triangles, and you get very realistic surfaces. Strong for 3D analysis, simulation as continues watertight models.
A measure of how large the object appears to an observer looking from that point. Thus. A measure for objects in the sky. Useful to retuen the size of the sun and moon… and in perspective, how much of their contribution to lighting. Solid angle can be represented in ‘angular diameter’ as well.
A solid angle is expressed in a dimensionless unit called a steradian (symbol: sr). By default in terms of the total celestial sphere and before atmospheric’s scattering, the Sun and the Moon subtend fractional areas of 0.000546% (Sun) and 0.000531% (Moon).
On earth the sun is likely closer to 0.00011 solid angle after athmospheric scattering. The sun as perceived from earth has a diameter of 0.53 degrees. This is about 0.000064 solid angle.
The mean angular diameter of the full moon is 2q = 0.52° (it varies with time around that average, by about 0.009°). This translates into a solid angle of 0.0000647 sr, which means that the whole night sky covers a solid angle roughly one hundred thousand times greater than the full moon.
The apparent size of an object as seen by an observer; expressed in units of degrees (of arc), arc minutes, or arc seconds. The moon, as viewed from the Earth, has an angular diameter of one-half a degree.
The angle covered by the diameter of the full moon is about 31 arcmin or 1/2°, so astronomers would say the Moon’s angular diameter is 31 arcmin, or the Moon subtends an angle of 31 arcmin.