The new material provides an energy density—the amount that can be squeezed into a given space—of 1,000 watt-hours per liter, which is about 100 times greater than TDK’s current battery in mass production.
TDK has 50 to 60 percent global market share in the small-capacity batteries that power smartphones and is targeting leadership in the medium-capacity market, which includes energy storage devices and larger electronics such as drones.
Blender 3 updated Intel® Open Image Denoise to version 1.4.2 which improved many artifacts in render, even separating into passes, but still loses a lot of definition when used in standard mode, DENOISER COMP separates passes and applies denoiser only in the selected passes and generates the final pass (beauty) keeping much more definition as can be seen in the videos.
Gen-3 Alpha is the first of an upcoming series of models trained by Runway on a new infrastructure built for large-scale multimodal training. It is a major improvement in fidelity, consistency, and motion over Gen-2, and a step towards building General World Models.
A novel zero-shot, diffusion-based pipeline for animating a single human image using facial expressions and body movements derived from a driving video, that generates realistic, context-aware dynamics for both the subject and the surrounding environment.
QuickTime (.mov) files are fundamentally time-based, not frame-based, and so don’t have a built-in, uniform “first frame/last frame” field you can set as numeric frame IDs. Instead, tools like Shotgun Create rely on the timecode track and the movie’s duration to infer frame numbers. If you want Shotgun to pick up a non-default frame range (e.g. start at 1001, end at 1064), you must bake in an SMPTE timecode that corresponds to your desired start frame, and ensure the movie’s duration matches your clip length.
How Shotgun Reads Frame Ranges
Default start frame is 1. If no timecode metadata is present, Shotgun assumes the movie begins at frame 1.
Timecode ⇒ frame number. Shotgun Create “honors the timecodes of media sources,” mapping the embedded TC to frame IDs. For example, a 24 fps QuickTime tagged with a start timecode of 00:00:41:17 will be interpreted as beginning on frame 1001 (1001 ÷ 24 fps ≈ 41.71 s).
Embedding a Start Timecode
QuickTime uses a tmcd (timecode) track. You can bake in an SMPTE track via FFmpeg’s -timecode flag or via Compressor/encoder settings:
Compute your start TC.
Desired start frame = 1001
Frame 1001 at 24 fps ⇒ 1001 ÷ 24 ≈ 41.708 s ⇒ TC 00:00:41:17
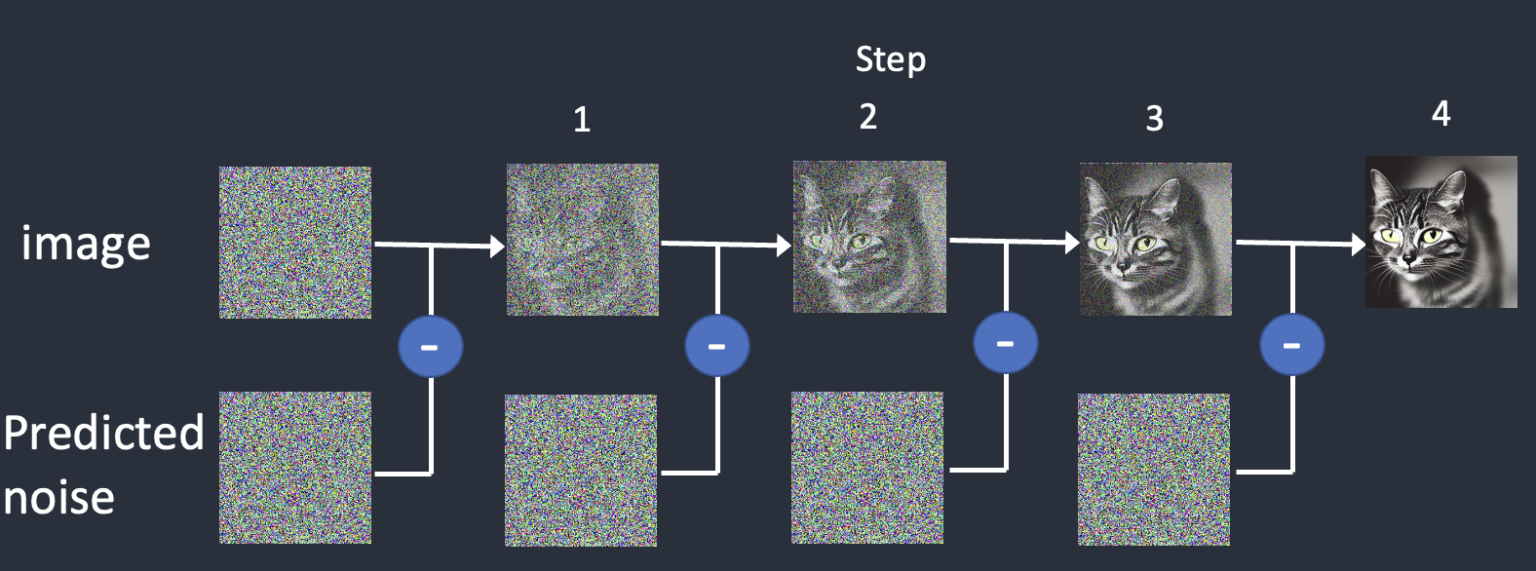
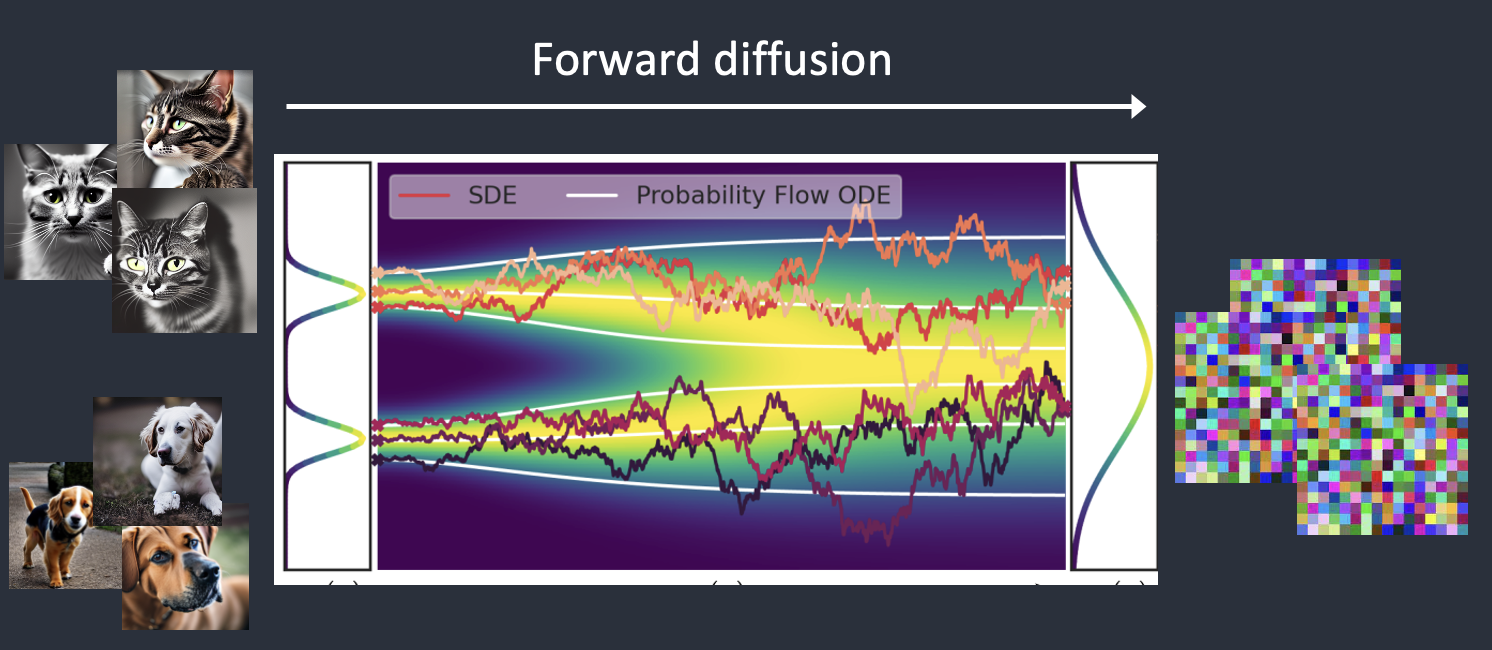
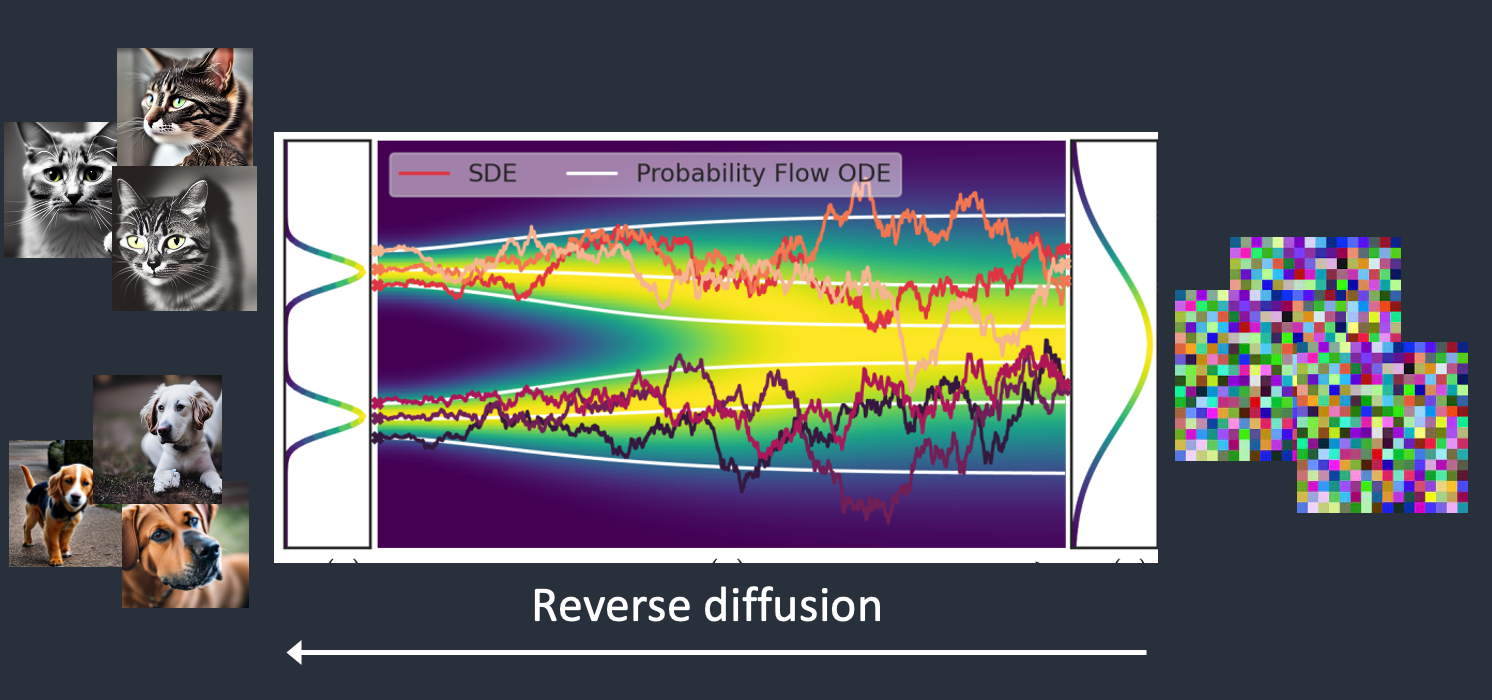
Stable Diffusion is a latent diffusion model that generates AI images from text. Instead of operating in the high-dimensional image space, it first compresses the image into the latent space.
Stable Diffusion belongs to a class of deep learning models called diffusion models. They are generative models, meaning they are designed to generate new data similar to what they have seen in training. In the case of Stable Diffusion, the data are images.
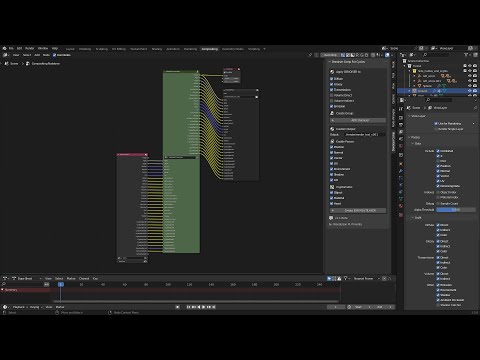
Why is it called the diffusion model? Because its math looks very much like diffusion in physics. Let’s go through the idea.