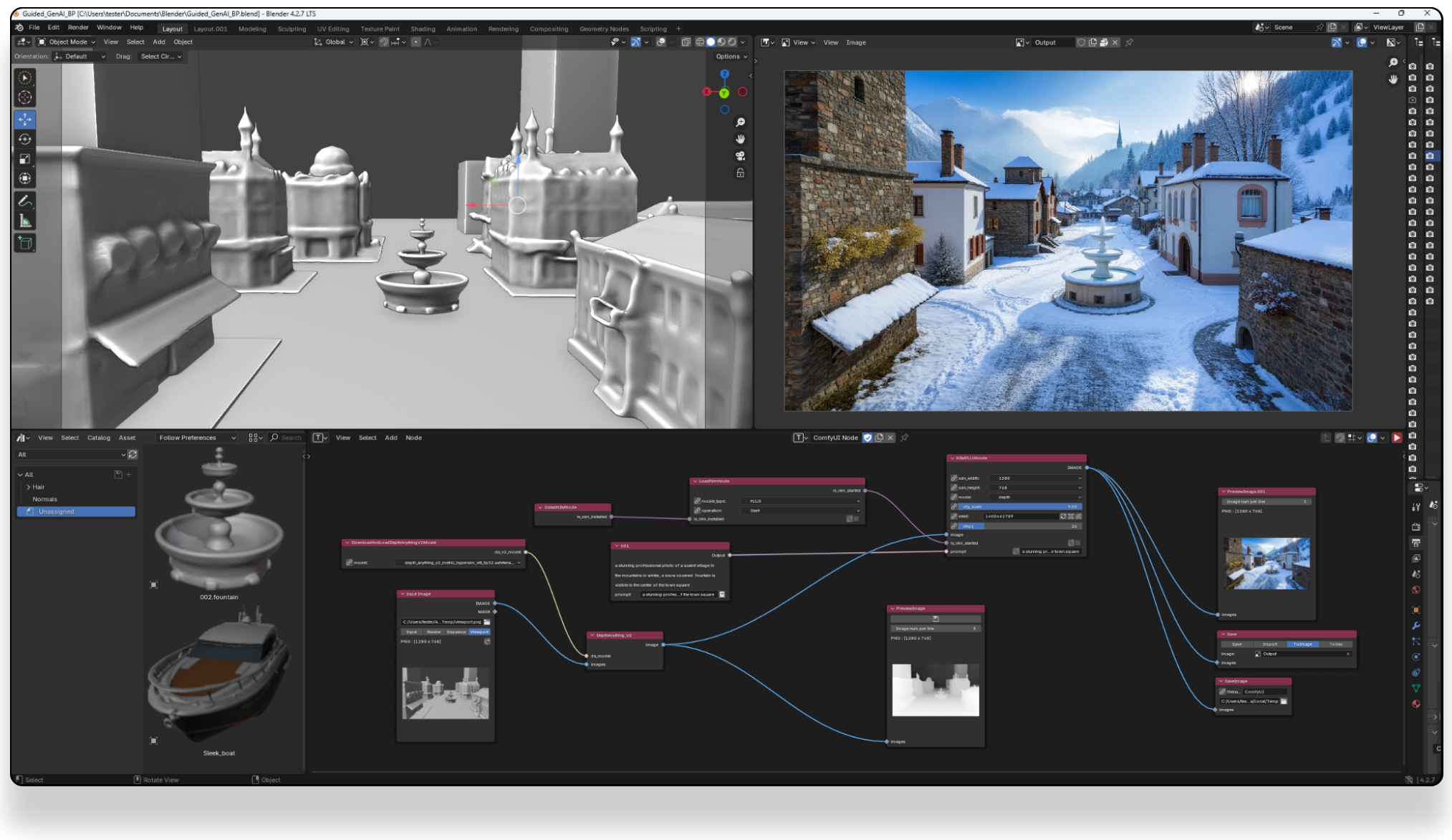
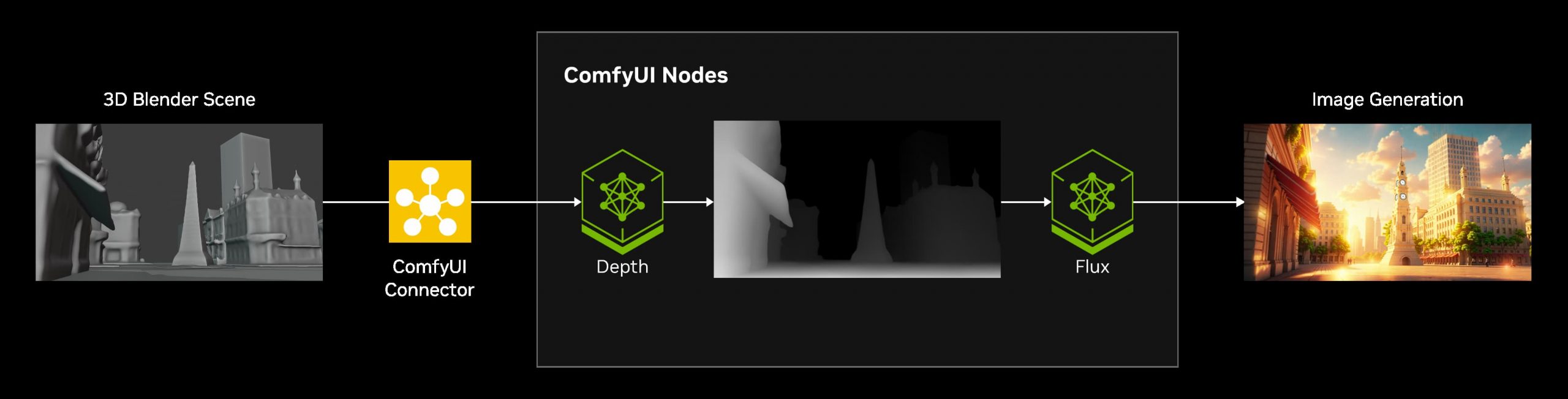
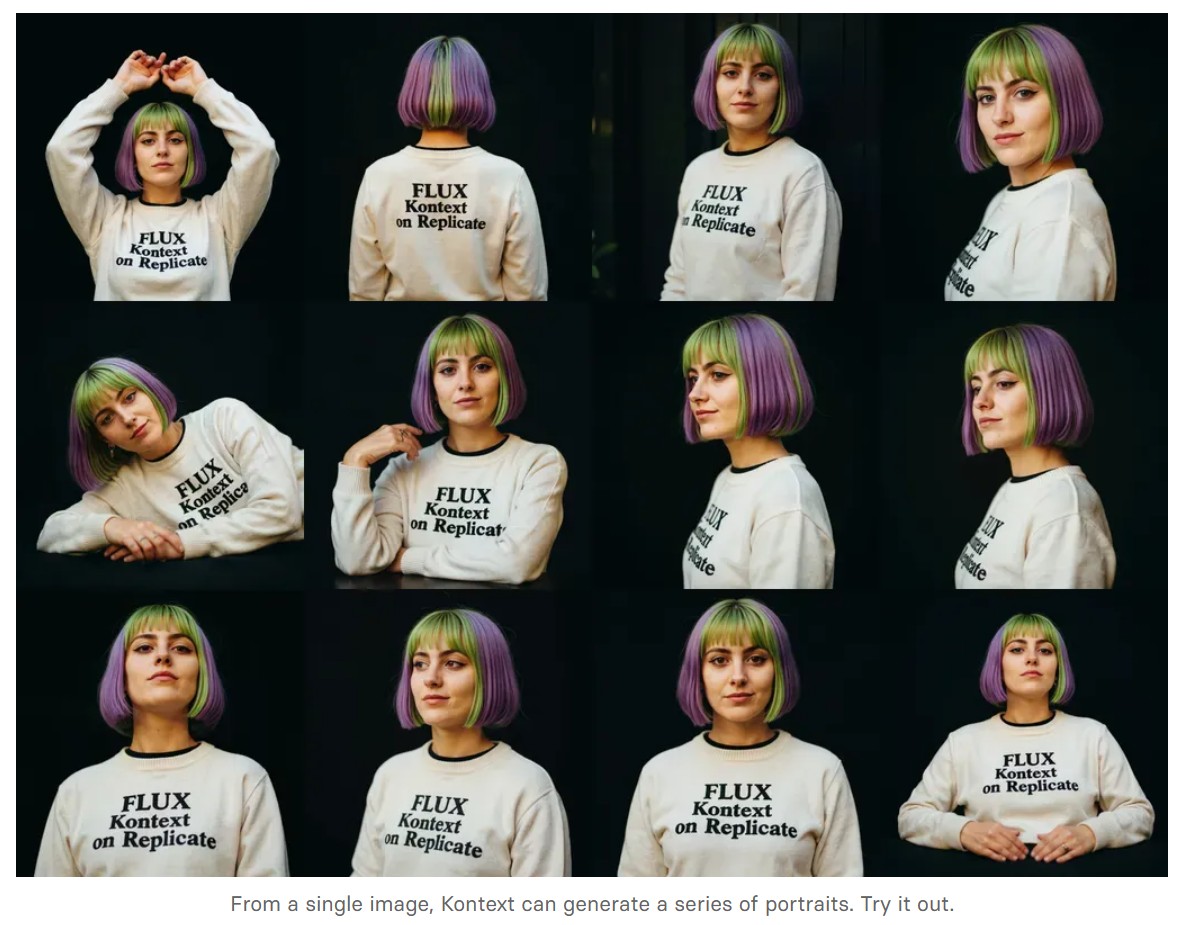There are three models, two are available now, and a third open-weight version is coming soon:
FLUX.1 Kontext [pro]: State-of-the-art performance for image editing. High-quality outputs, great prompt following, and consistent results.
FLUX.1 Kontext [max]: A premium model that brings maximum performance, improved prompt adherence, and high-quality typography generation without compromise on speed.
Coming soon: FLUX.1 Kontext [dev]: An open-weight, guidance-distilled version of Kontext.
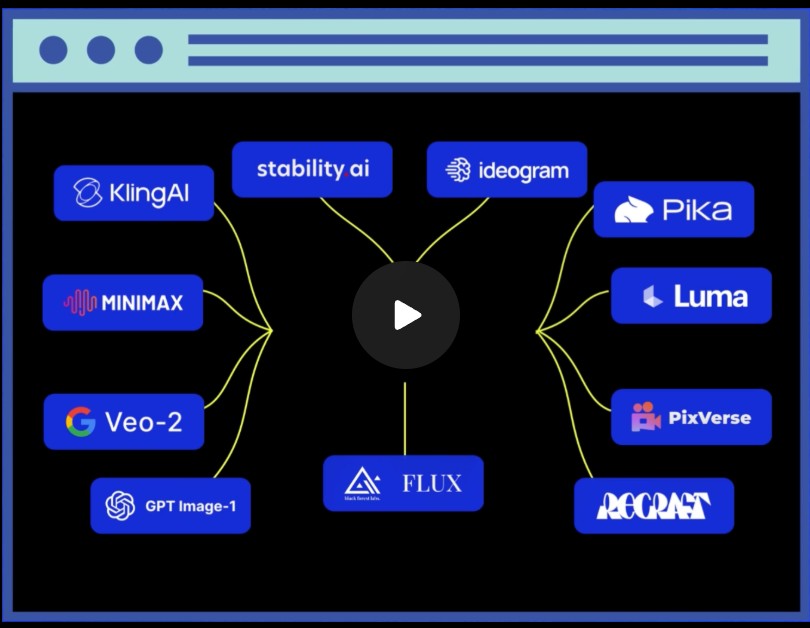
We’re so excited with what Kontext can do, we’ve created a collection of models on Replicate to give you ideas:
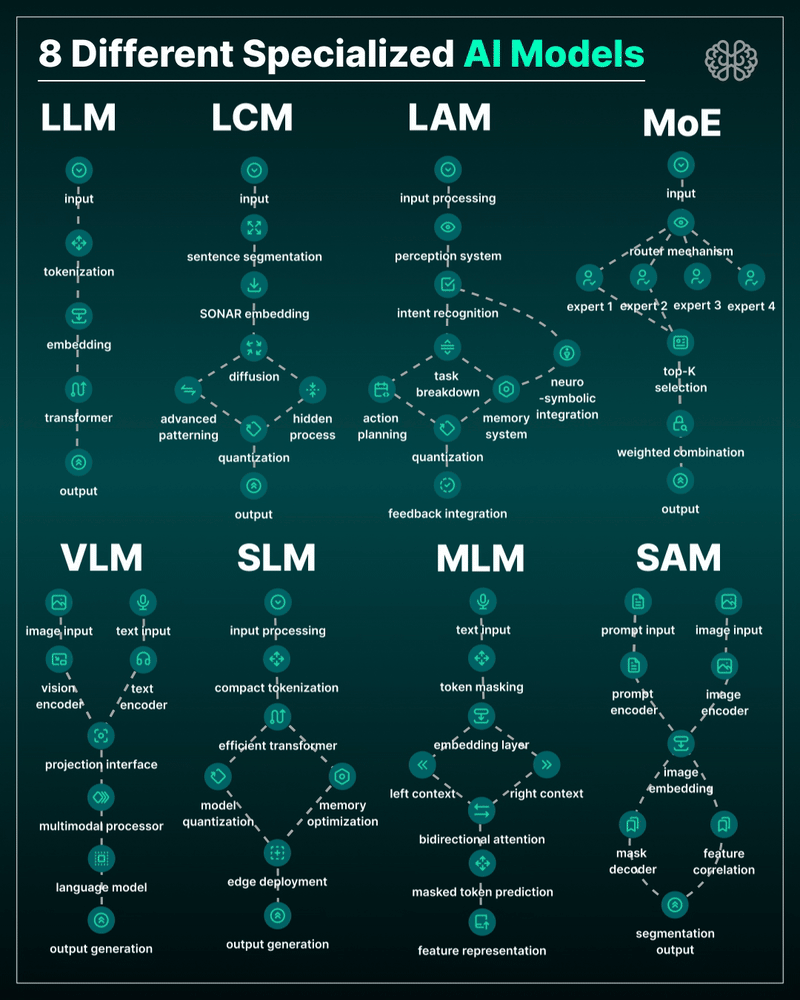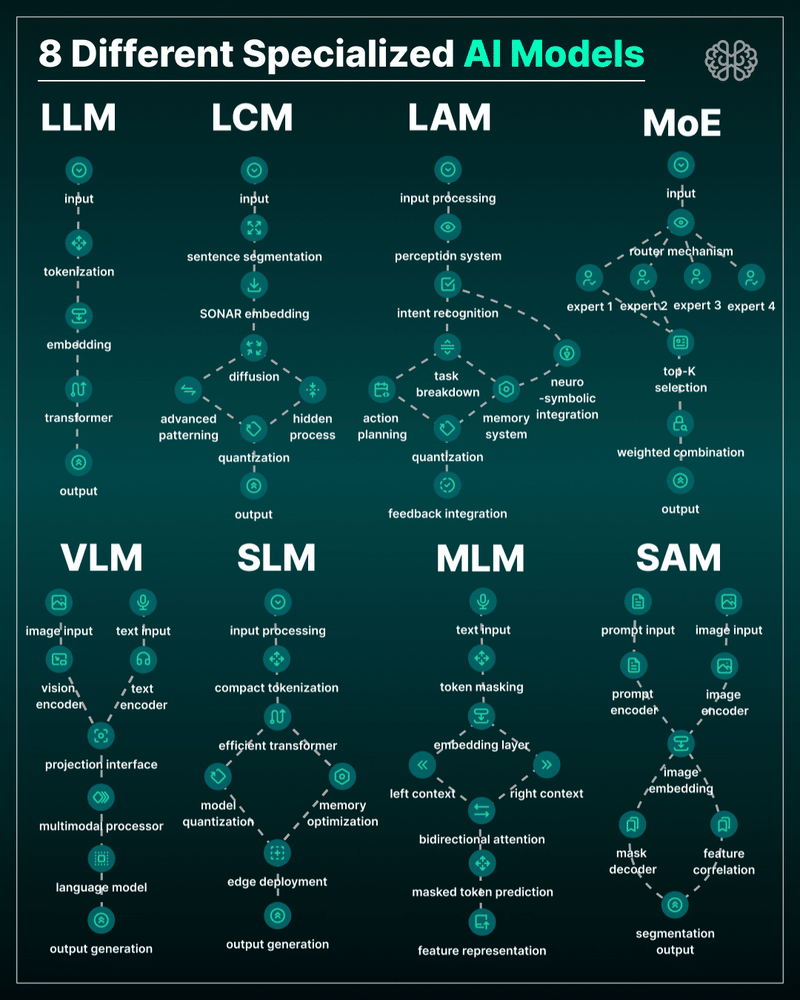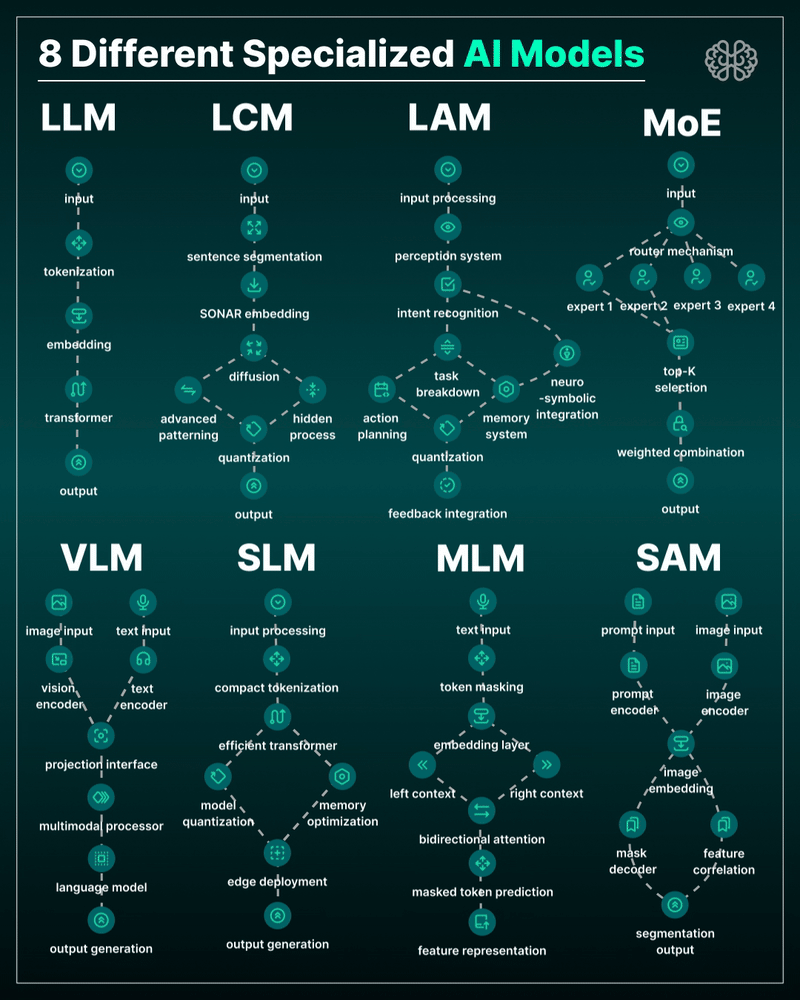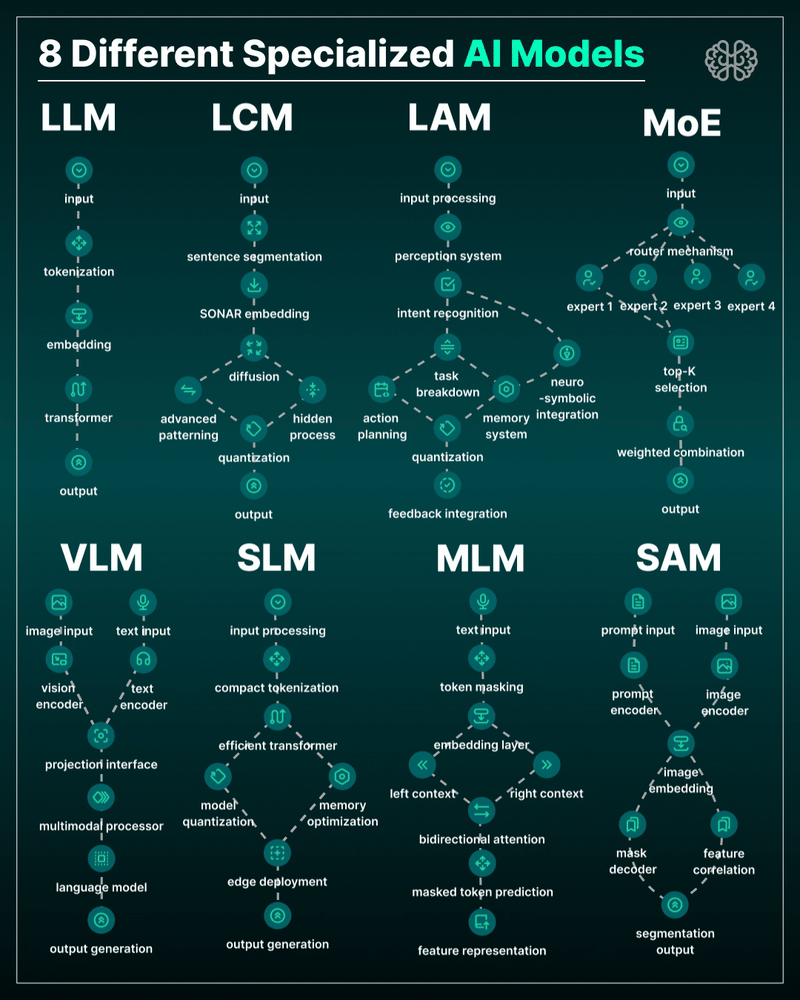
the 8 most important model types and what they’re actually built to do: ⬇️
1. 𝗟𝗟𝗠 – 𝗟𝗮𝗿𝗴𝗲 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹 → Your ChatGPT-style model. Handles text, predicts the next token, and powers 90% of GenAI hype. 🛠 Use case: content, code, convos.
2. 𝗟𝗖𝗠 – 𝗟𝗮𝘁𝗲𝗻𝘁 𝗖𝗼𝗻𝘀𝗶𝘀𝘁𝗲𝗻𝗰𝘆 𝗠𝗼𝗱𝗲𝗹 → Lightweight, diffusion-style models. Fast, quantized, and efficient — perfect for real-time or edge deployment. 🛠 Use case: image generation, optimized inference.
3. 𝗟𝗔𝗠 – 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗔𝗰𝘁𝗶𝗼𝗻 𝗠𝗼𝗱𝗲𝗹 → Where LLM meets planning. Adds memory, task breakdown, and intent recognition. 🛠 Use case: AI agents, tool use, step-by-step execution.
4. 𝗠𝗼𝗘 – 𝗠𝗶𝘅𝘁𝘂𝗿𝗲 𝗼𝗳 𝗘𝘅𝗽𝗲𝗿𝘁𝘀 → One model, many minds. Routes input to the right “expert” model slice — dynamic, scalable, efficient. 🛠 Use case: high-performance model serving at low compute cost.
5. 𝗩𝗟𝗠 – 𝗩𝗶𝘀𝗶𝗼𝗻 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹 → Multimodal beast. Combines image + text understanding via shared embeddings. 🛠 Use case: Gemini, GPT-4o, search, robotics, assistive tech.
6. 𝗦𝗟𝗠 – 𝗦𝗺𝗮𝗹𝗹 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹 → Tiny but mighty. Designed for edge use, fast inference, low latency, efficient memory. 🛠 Use case: on-device AI, chatbots, privacy-first GenAI.
7. 𝗠𝗟𝗠 – 𝗠𝗮𝘀𝗸𝗲𝗱 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹 → The OG foundation model. Predicts masked tokens using bidirectional context. 🛠 Use case: search, classification, embeddings, pretraining.
8. 𝗦𝗔𝗠 – 𝗦𝗲𝗴𝗺𝗲𝗻𝘁 𝗔𝗻𝘆𝘁𝗵𝗶𝗻𝗴 𝗠𝗼𝗱𝗲𝗹 → Vision model for pixel-level understanding. Highlights, segments, and understands *everything* in an image. 🛠 Use case: medical imaging, AR, robotics, visual agents.
David Sandberg has responded and said “This was an internal promo video that was never supposed to be seen by the public. I feel bad because it contains a bunch of plot points and temp VFX,” Sandberg told Variety in a statement. “I hope at least people can see the passion that we poured into the movie, the world deserves to see it as it was meant to be seen. This movie has been held hostage for the past 5 years but I promise to keep fighting for it and make sure this film gets the chance it truly deserves.”
Maya blue is a highly unusual pigment because it is a mix of organic indigo and an inorganic clay mineral called palygorskite.
Echoing the color of an azure sky, the indelible pigment was used to accentuate everything from ceramics to human sacrifices in the Late Preclassic period (300 B.C. to A.D. 300).
A team of researchers led by Dean Arnold, an adjunct curator of anthropology at the Field Museum in Chicago, determined that the key to Maya blue was actually a sacred incense called copal. By heating the mixture of indigo, copal and palygorskite over a fire, the Maya produced the unique pigment, he reported at the time.
To measure the contrast ratio you will need a light meter. The process starts with you measuring the main source of light, or the key light.
Get a reading from the brightest area on the face of your subject. Then, measure the area lit by the secondary light, or fill light. To make sense of what you have just measured you have to understand that the information you have just gathered is in F-stops, a measure of light. With each additional F-stop, for example going one stop from f/1.4 to f/2.0, you create a doubling of light. The reverse is also true; moving one stop from f/8.0 to f/5.6 results in a halving of the light.