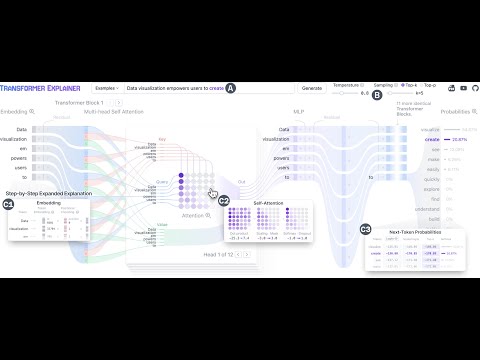
Transformer Explainer is an interactive visualization tool designed to help anyone learn how Transformer-based models like GPT work. It runs a live GPT-2 model right in your browser, allowing you to experiment with your own text and observe in real time how internal components and operations of the Transformer work together to predict the next tokens. Try Transformer Explainer at http://poloclub.github.io/transformer-explainer
If you prompt for a 360° video in VEO (like literally write “360°” ) it can generate a Monoscopic 360 video, then the next step is to inject the right metadata in your file so you can play it as an actual 360 video. Once it’s saved with the right Metadata, it will be recognized as an actual 360/VR video, meaning you can just play it in VLC and drag your mouse to look around.
There are three models, two are available now, and a third open-weight version is coming soon:
FLUX.1 Kontext [pro]: State-of-the-art performance for image editing. High-quality outputs, great prompt following, and consistent results.
FLUX.1 Kontext [max]: A premium model that brings maximum performance, improved prompt adherence, and high-quality typography generation without compromise on speed.
Coming soon: FLUX.1 Kontext [dev]: An open-weight, guidance-distilled version of Kontext.
We’re so excited with what Kontext can do, we’ve created a collection of models on Replicate to give you ideas:
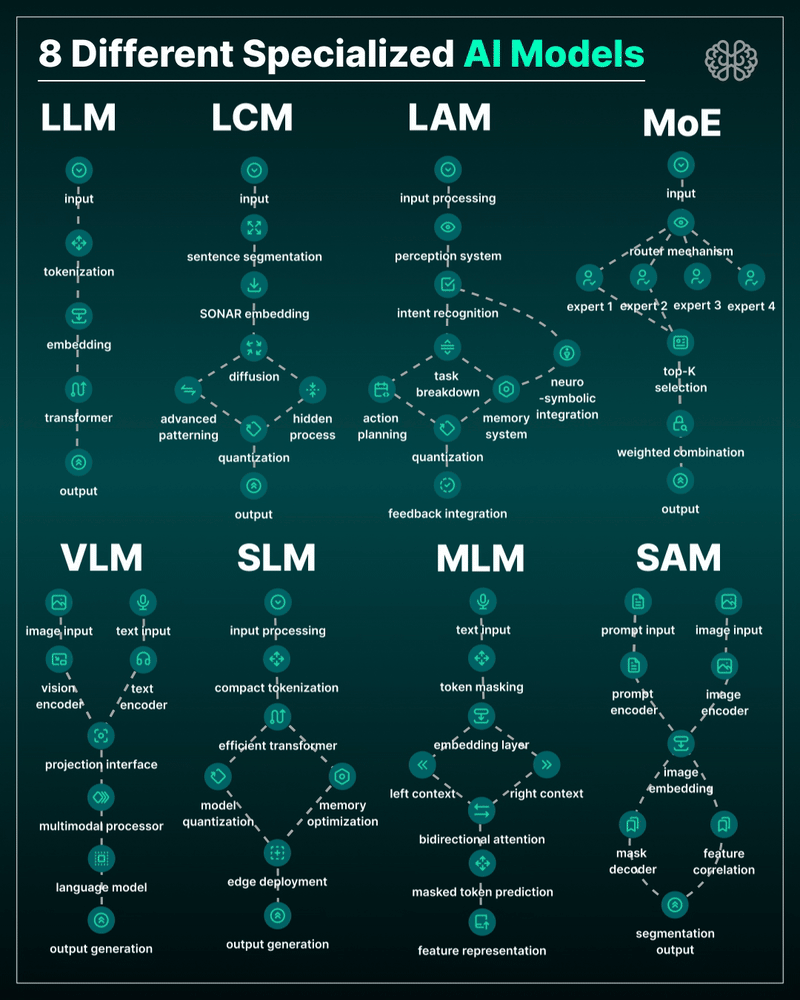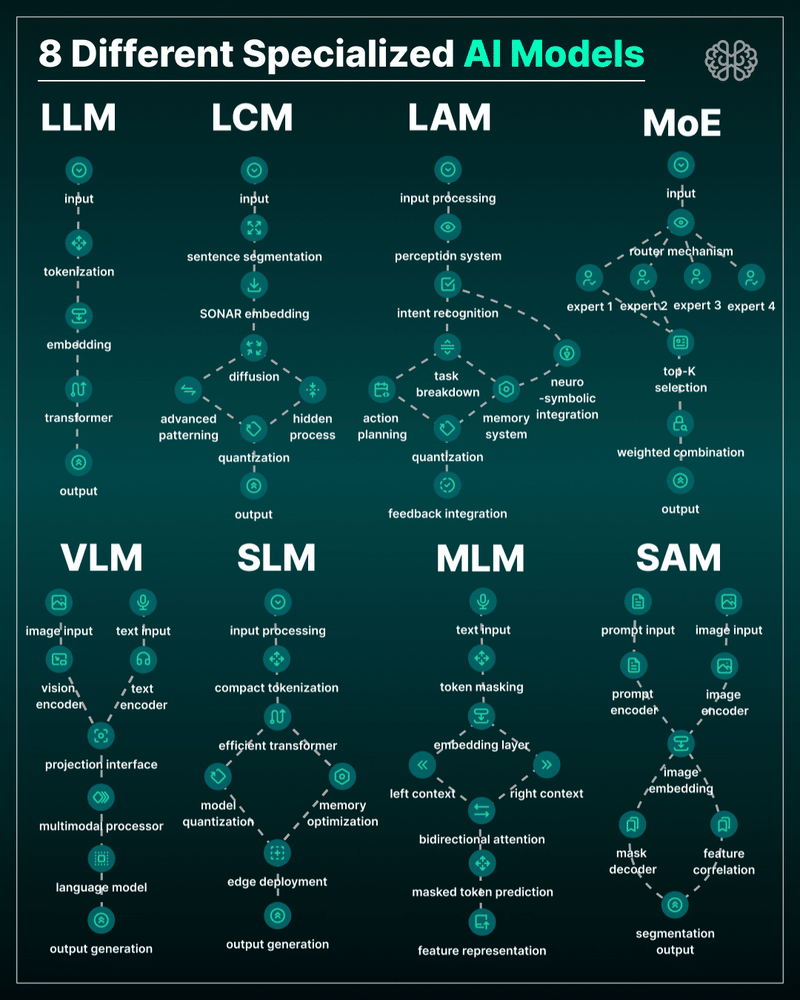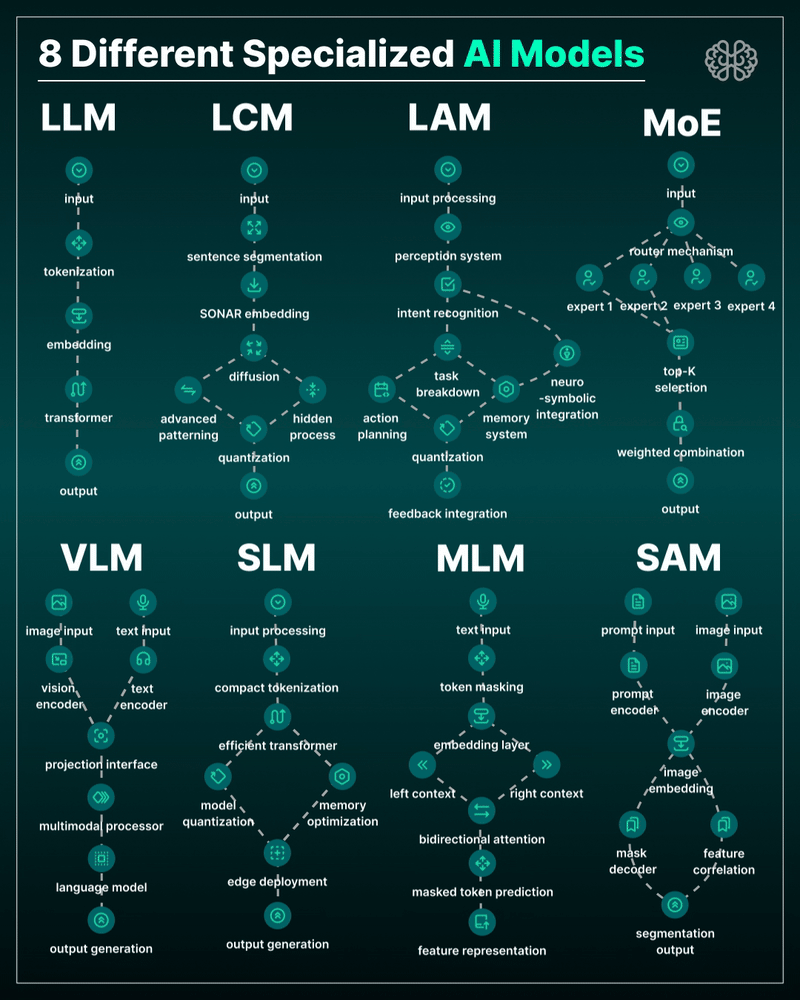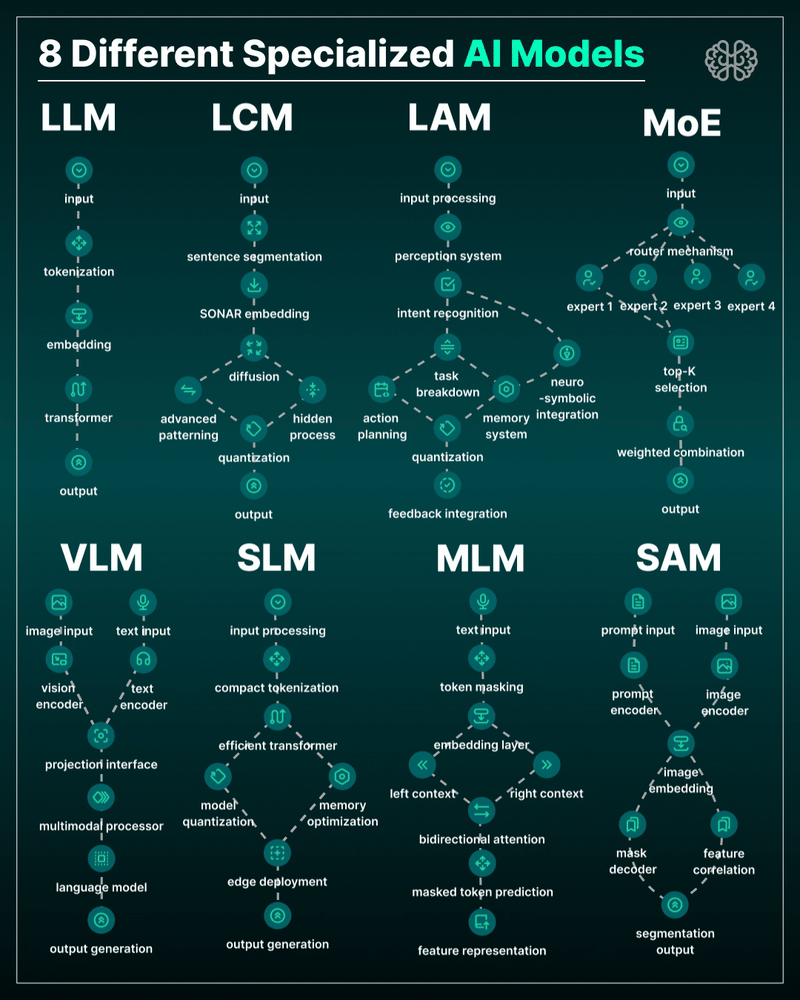
the 8 most important model types and what they’re actually built to do: ⬇️
1. 𝗟𝗟𝗠 – 𝗟𝗮𝗿𝗴𝗲 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹 → Your ChatGPT-style model. Handles text, predicts the next token, and powers 90% of GenAI hype. 🛠 Use case: content, code, convos.
2. 𝗟𝗖𝗠 – 𝗟𝗮𝘁𝗲𝗻𝘁 𝗖𝗼𝗻𝘀𝗶𝘀𝘁𝗲𝗻𝗰𝘆 𝗠𝗼𝗱𝗲𝗹 → Lightweight, diffusion-style models. Fast, quantized, and efficient — perfect for real-time or edge deployment. 🛠 Use case: image generation, optimized inference.
3. 𝗟𝗔𝗠 – 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗔𝗰𝘁𝗶𝗼𝗻 𝗠𝗼𝗱𝗲𝗹 → Where LLM meets planning. Adds memory, task breakdown, and intent recognition. 🛠 Use case: AI agents, tool use, step-by-step execution.
4. 𝗠𝗼𝗘 – 𝗠𝗶𝘅𝘁𝘂𝗿𝗲 𝗼𝗳 𝗘𝘅𝗽𝗲𝗿𝘁𝘀 → One model, many minds. Routes input to the right “expert” model slice — dynamic, scalable, efficient. 🛠 Use case: high-performance model serving at low compute cost.
5. 𝗩𝗟𝗠 – 𝗩𝗶𝘀𝗶𝗼𝗻 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹 → Multimodal beast. Combines image + text understanding via shared embeddings. 🛠 Use case: Gemini, GPT-4o, search, robotics, assistive tech.
6. 𝗦𝗟𝗠 – 𝗦𝗺𝗮𝗹𝗹 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹 → Tiny but mighty. Designed for edge use, fast inference, low latency, efficient memory. 🛠 Use case: on-device AI, chatbots, privacy-first GenAI.
7. 𝗠𝗟𝗠 – 𝗠𝗮𝘀𝗸𝗲𝗱 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹 → The OG foundation model. Predicts masked tokens using bidirectional context. 🛠 Use case: search, classification, embeddings, pretraining.
8. 𝗦𝗔𝗠 – 𝗦𝗲𝗴𝗺𝗲𝗻𝘁 𝗔𝗻𝘆𝘁𝗵𝗶𝗻𝗴 𝗠𝗼𝗱𝗲𝗹 → Vision model for pixel-level understanding. Highlights, segments, and understands *everything* in an image. 🛠 Use case: medical imaging, AR, robotics, visual agents.
The way humans see the world… until we have a way to describe something, even something so fundamental as a colour, we may not even notice that something it’s there.
Ancient languages didn’t have a word for blue — not Greek, not Chinese, not Japanese, not Hebrew, not Icelandic cultures. And without a word for the colour, there’s evidence that they may not have seen it at all. https://www.wnycstudios.org/story/211119-colors
Every language first had a word for black and for white, or dark and light. The next word for a colour to come into existence — in every language studied around the world — was red, the colour of blood and wine. After red, historically, yellow appears, and later, green (though in a couple of languages, yellow and green switch places). The last of these colours to appear in every language is blue.
The only ancient culture to develop a word for blue was the Egyptians — and as it happens, they were also the only culture that had a way to produce a blue dye. https://mymodernmet.com/shades-of-blue-color-history/
True blue hues are rare in the natural world because synthesizing pigments that absorb longer-wavelength light (reds and yellows) while reflecting shorter-wavelength blue light requires exceptionally elaborate molecular structures—biochemical feats that most plants and animals simply don’t undertake.
When you gaze at a blueberry’s deep blue surface, you’re actually seeing structural coloration rather than a true blue pigment. A fine, waxy bloom on the berry’s skin contains nanostructures that preferentially scatter blue and violet light, giving the fruit its signature blue sheen even though its inherent pigment is reddish.
Similarly, many of nature’s most striking blues—like those of blue jays and morpho butterflies—arise not from blue pigments but from microscopic architectures in feathers or wing scales. These tiny ridges and air pockets manipulate incoming light so that blue wavelengths emerge most prominently, creating vivid, angle-dependent colors through scattering rather than pigment alone.
Spectral sensitivity of eye is influenced by light intensity. And the light intensity determines the level of activity of cones cell and rod cell. This is the main characteristic of human vision. Sensitivity to individual colors, in other words, wavelengths of the light spectrum, is explained by the RGB (red-green-blue) theory. This theory assumed that there are three kinds of cones. It’s selectively sensitive to red (700-630 nm), green (560-500 nm), and blue (490-450 nm) light. And their mutual interaction allow to perceive all colors of the spectrum.
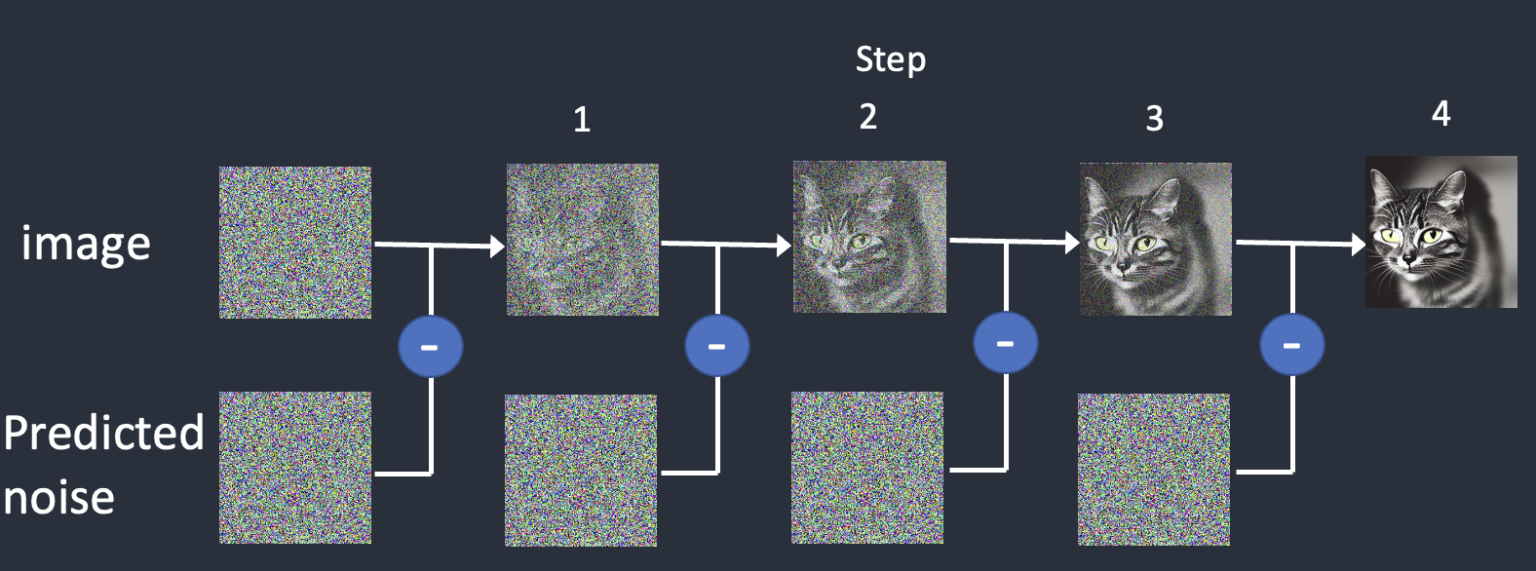
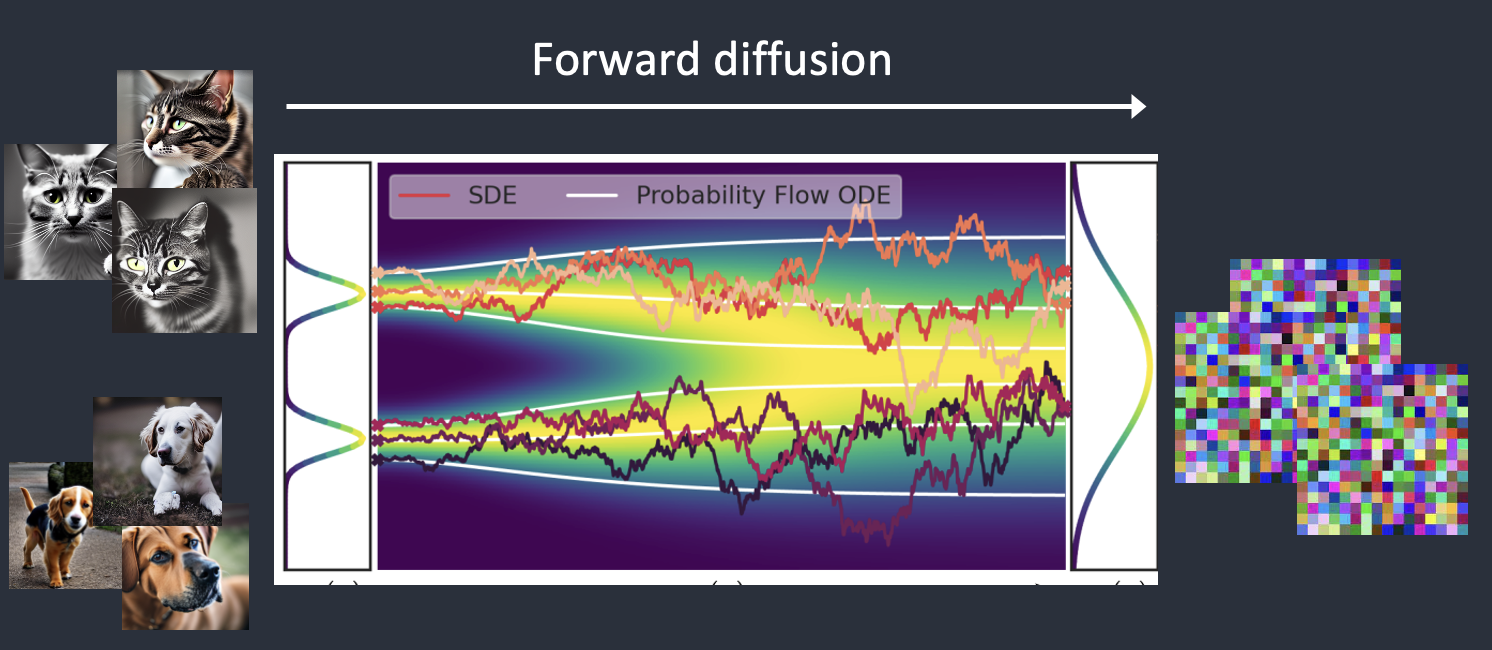
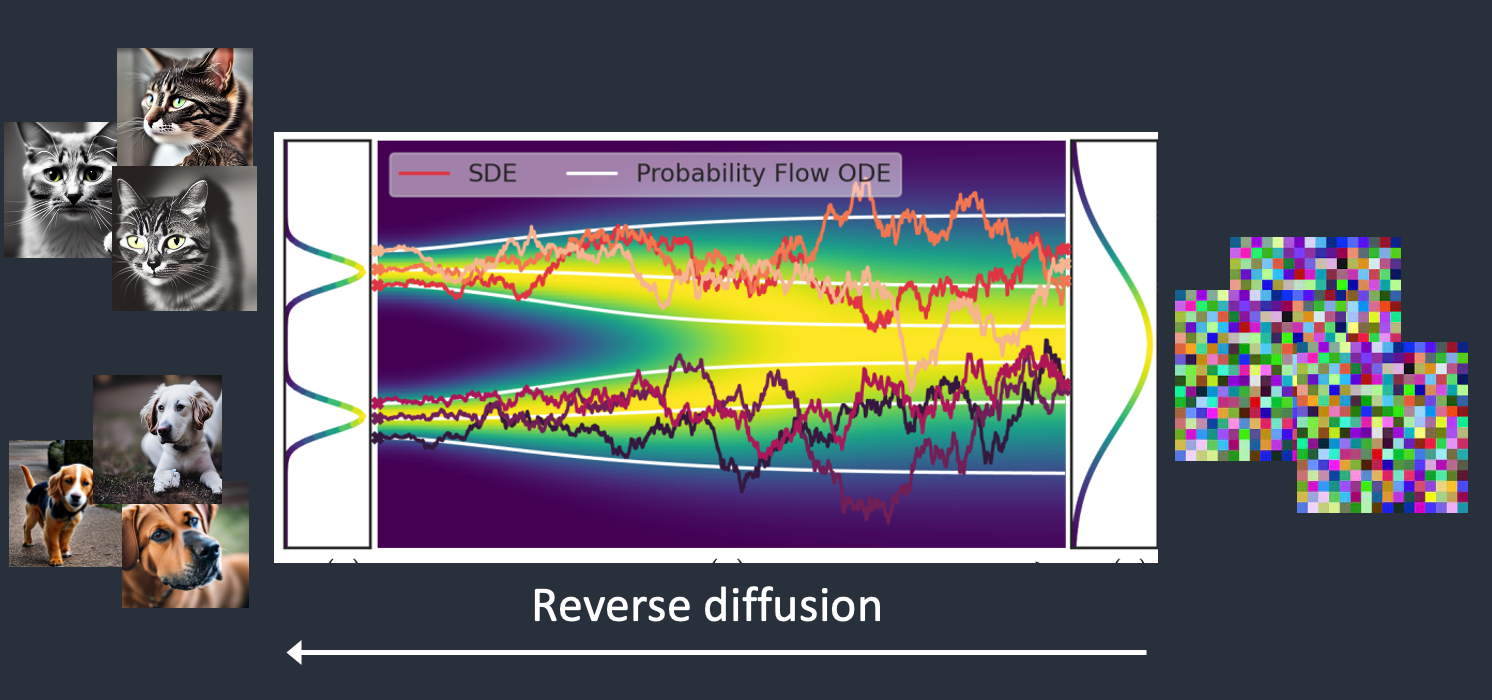
Stable Diffusion is a latent diffusion model that generates AI images from text. Instead of operating in the high-dimensional image space, it first compresses the image into the latent space.
Stable Diffusion belongs to a class of deep learning models called diffusion models. They are generative models, meaning they are designed to generate new data similar to what they have seen in training. In the case of Stable Diffusion, the data are images.
Why is it called the diffusion model? Because its math looks very much like diffusion in physics. Let’s go through the idea.
To measure the contrast ratio you will need a light meter. The process starts with you measuring the main source of light, or the key light.
Get a reading from the brightest area on the face of your subject. Then, measure the area lit by the secondary light, or fill light. To make sense of what you have just measured you have to understand that the information you have just gathered is in F-stops, a measure of light. With each additional F-stop, for example going one stop from f/1.4 to f/2.0, you create a doubling of light. The reverse is also true; moving one stop from f/8.0 to f/5.6 results in a halving of the light.





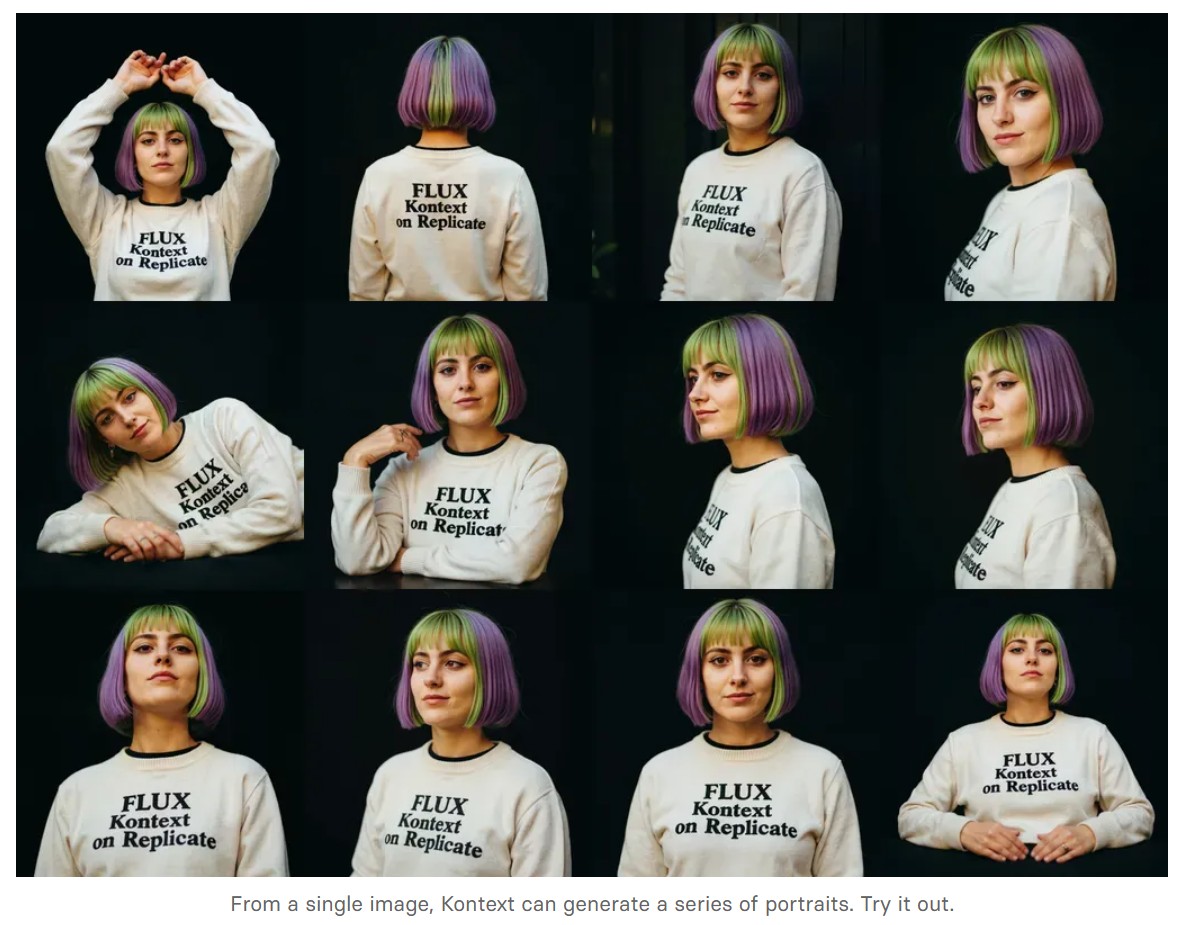




















{kind=link}

