2- Self-Hosting
If you have GPU infrastructure (on-premises or cloud), you can run Llama 3 internally at your desired scale.
→ Deploy Llama 3 on Amazon SageMaker: https://www.philschmid.de/sagemaker-llama3
3- Desktop (Offline)
Tools like Ollama allow you to run the small model offline on consumer hardware like current MacBooks.
→ Tutorial for Mac: https://ollama.com/blog/llama3
Panelists include Author and Distinguished Research Scientist in DL/ML & CG at Wētā FX Dr. Andrew Glassner, VFX, Post & Technology Recruiter and VES 1st Vice Chair Susan O’Neal, CTO at Cinesite Group and VES Technology Committee member Michele Sciolette and Shareholder & Co-Chair of Buchalter’s Entertainment Industry Group and Adjunct Professor at Southwestern Law School Stephen Strauss, moderated by VES Technology Committee member and Media & Entertainment Executive, CTO & Industry Advisor Barbara Ford Grant.
This foundational polariton particle breakthrough could lead to significant improvements in displays using an entirely novel approach compared to all previous ones. One significant difference is the ability of each polaritron to emit any wavelength, eliminating the need for separate red, green and blue (RGB) emitters intermixed in a grid. They are also able the achieve significantly greater energy levels, in other words, brightness.
Sam Altman, CEO of OpenAI, dropped a 💣 at a recent MIT event, declaring that the era of gigantic AI models like GPT-4 is coming to an end. He believes that future progress in AI needs new ideas, not just bigger models.
So why is that revolutionary? Well, this is how OpenAI’s LLMs (the models that ‘feed’ chatbots like ChatGPT & Google Bard) grew exponentially over the years: ➡️GPT-2 (2019): 1.5 billion parameters ➡️GPT-3 (2020): 175 billion parameters ➡️GPT-4: (2023): amount undisclosed – but likely trillions of parameters
That kind of parameter growth is no longer tenable, feels Altman.
Why?: ➡️RETURNS: scaling up model size comes with diminishing returns. ➡️PHYSICAL LIMITS: there’s a limit to how many & how quickly data centers can be built. ➡️COST: ChatGPT cost over over 100 million dollars to develop.
What is he NOT saying? That access to data is becoming damned hard & expensive. So if you have a model that keeps needing more data to become better, that’s a problem.
Why is it becoming harder and more expensive to access data?
🎨Copyright conundrums: Getty Images, individual artists like Sarah Andersen, Kelly McKernan & Karloa Otiz are suing AI companies over unauthorized use of their content. Universal Music asked Spotify & Apple Music to stop AI companies from accessing their songs for training.
🔐Privacy matters & regulation: Italy banned ChatGPT over privacy concerns (now back after changes). Germany, France, Ireland, Canada, and Spain remain suspicious. Samsung even warned employees not to use AI tools like ChatGPT for security reasons.
💸Data monetization: Twitter, Reddit, Stack Overflow & others want AI companies to pay up for training on their data. Contrary to most artists, Grimes is allowing anyone to use her voice for AI-generated songs … for a 50% profit share.
🕸️Web3’s impact: If Web3 fulfills its promise, users could store data in personal vaults or cryptocurrency wallets, making it harder for LLMs to access the data they crave.
🌎Geopolitics: it’s increasingly difficult for data to cross country borders. Just think about China and TikTok.
😷Data contamination: We have this huge amount of ‘new’ – and sometimes hallucinated – data that is being generated by generative AI chatbots. What will happen if we feed that data back into their LLMs?
No wonder that people like Sam Altman are looking for ways to make the models better without having to use more data. If you want to know more, check our brand new Radar podcast episode (link in the comments), where I talked about this & more with Steven Van Belleghem, Peter Hinssen, Pascal Coppens & Julie Vens – De Vos. We also discussed Twitter, TikTok, Walmart, Amazon, Schmidt Futures, our Never Normal Tour with Mediafin in New York (link in the comments), the human energy crisis, Apple’s new high-yield savings account, the return of China, BYD, AI investment strategies, the power of proximity, the end of Buzzfeed news & much more.
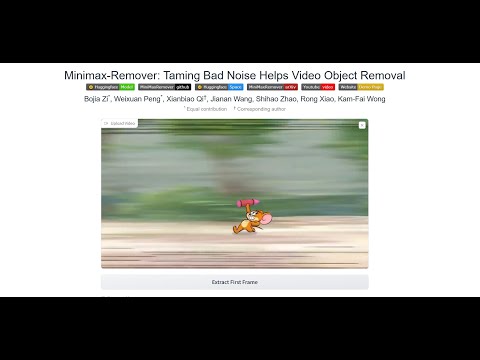
MiniMax-Remover is a fast and effective video object remover based on minimax optimization. It operates in two stages: the first stage trains a remover using a simplified DiT architecture, while the second stage distills a robust remover with CFG removal and fewer inference steps.