ACES 2.0 is the second major release of the components that make up the ACES system. The most significant change is a new suite of rendering transforms whose design was informed by collected feedback and requests from users of ACES 1. The changes aim to improve the appearance of perceived artifacts and to complete previously unfinished components of the system, resulting in a more complete, robust, and consistent product.
Highlights of the key changes in ACES 2.0 are as follows:
New output transforms, including:
A less aggressive tone scale
More intuitive controls to create custom outputs to non-standard displays
Robust gamut mapping to improve perceptual uniformity
Improved performance of the inverse transforms
Enhanced AMF specification
An updated specification for ACES Transform IDs
OpenEXR compression recommendations
Enhanced tools for generating Input Transforms and recommended procedures for characterizing prosumer cameras
Look Transform Library
Expanded documentation
Rendering Transform
The most substantial change in ACES 2.0 is a complete redesign of the rendering transform.
ACES 2.0 was built as a unified system, rather than through piecemeal additions. Different deliverable outputs “match” better and making outputs to display setups other than the provided presets is intended to be user-driven. The rendering transforms are less likely to produce undesirable artifacts “out of the box”, which means less time can be spent fixing problematic images and more time making pictures look the way you want.
Key design goals
Improve consistency of tone scale and provide an easy to use parameter to allow for outputs between preset dynamic ranges
Minimize hue skews across exposure range in a region of same hue
Unify for structural consistency across transform type
Easy to use parameters to create outputs other than the presets
Robust gamut mapping to improve harsh clipping artifacts
Fill extents of output code value cube (where appropriate and expected)
Invertible – not necessarily reversible, but Output > ACES > Output round-trip should be possible
Accomplish all of the above while maintaining an acceptable “out-of-the box” rendering
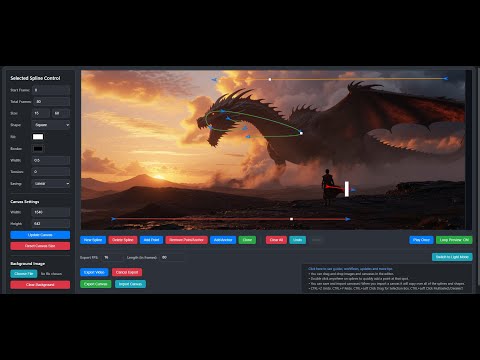
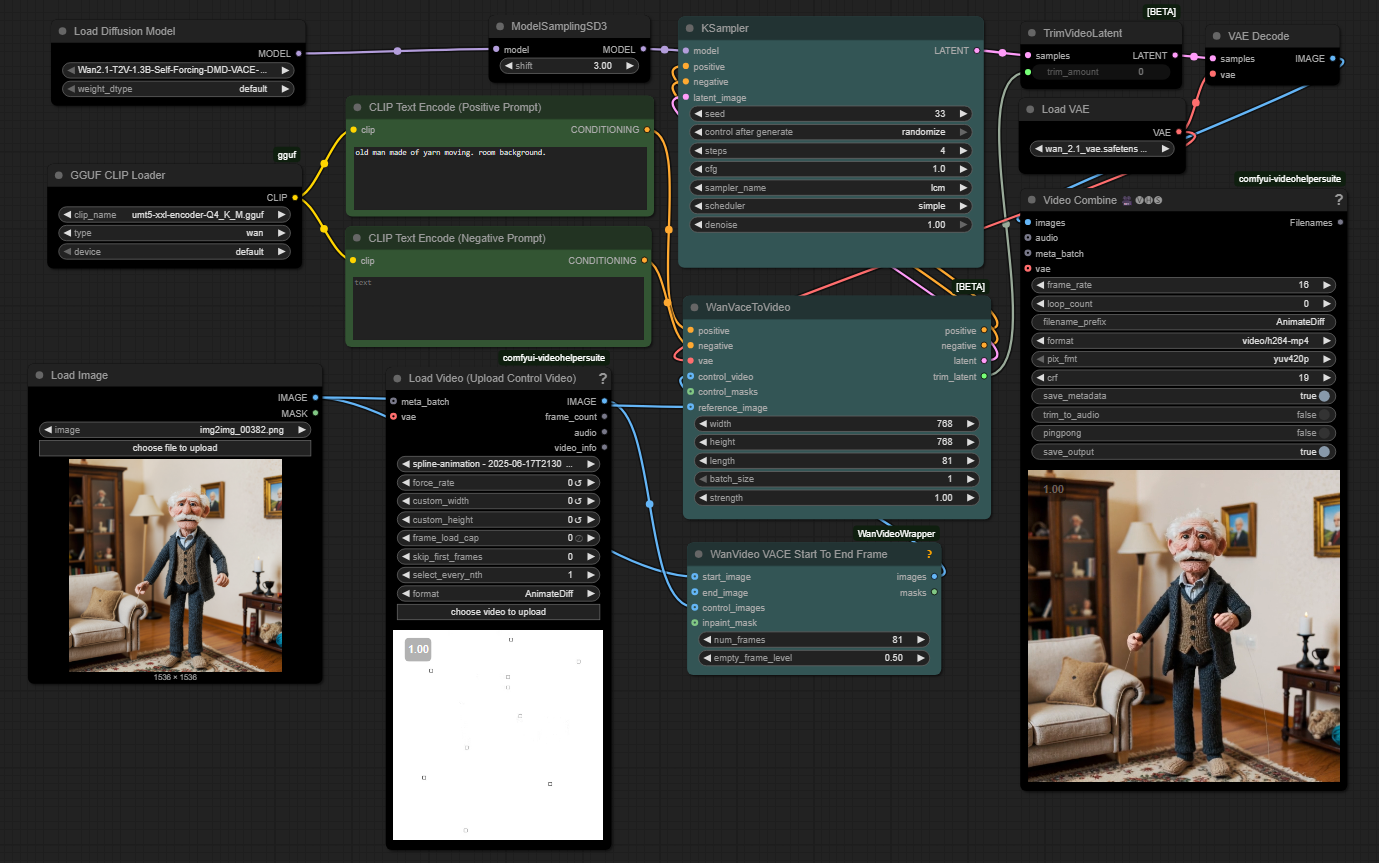
Spline Path Control is a simple tool designed to make it easy to create motion controls. It allows you to create and animate shapes that follow splines, and then export the result as a .webm video file. This project was created to simplify the process of generating control videos for tools like VACE. Use it to control the motion of anything (camera movement, objects, humans etc) all without extra prompting.
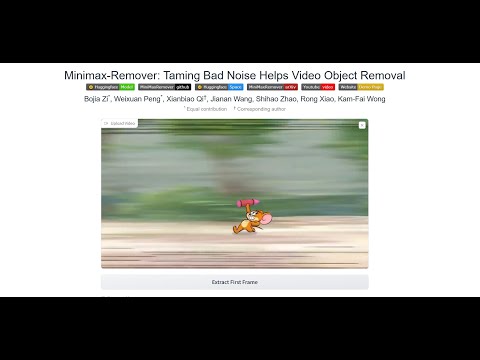
MiniMax-Remover is a fast and effective video object remover based on minimax optimization. It operates in two stages: the first stage trains a remover using a simplified DiT architecture, while the second stage distills a robust remover with CFG removal and fewer inference steps.
Our human-centric dense prediction model delivers high-quality, detailed (depth) results while achieving remarkable efficiency, running orders of magnitude faster than competing methods, with inference speeds as low as 21 milliseconds per frame (the large multi-task model on an NVIDIA A100). It reliably captures a wide range of human characteristics under diverse lighting conditions, preserving fine-grained details such as hair strands and subtle facial features. This demonstrates the model’s robustness and accuracy in complex, real-world scenarios.
The state of the art in human-centric computer vision achieves high accuracy and robustness across a diverse range of tasks. The most effective models in this domain have billions of parameters, thus requiring extremely large datasets, expensive training regimes, and compute-intensive inference. In this paper, we demonstrate that it is possible to train models on much smaller but high-fidelity synthetic datasets, with no loss in accuracy and higher efficiency. Using synthetic training data provides us with excellent levels of detail and perfect labels, while providing strong guarantees for data provenance, usage rights, and user consent. Procedural data synthesis also provides us with explicit control on data diversity, that we can use to address unfairness in the models we train. Extensive quantitative assessment on real input images demonstrates accuracy of our models on three dense prediction tasks: depth estimation, surface normal estimation, and soft foreground segmentation. Our models require only a fraction of the cost of training and inference when compared with foundational models of similar accuracy.
In the last 10 years, over 1,000 people have asked me how to start a business. The truth? They’re all paralyzed by limiting beliefs. What they are and how to break them today:
Before we get into the How, let’s first unpack why people think they can’t start a business. Here are the biggest reasons I’ve found:
Stable Diffusion is a latent diffusion model that generates AI images from text. Instead of operating in the high-dimensional image space, it first compresses the image into the latent space.
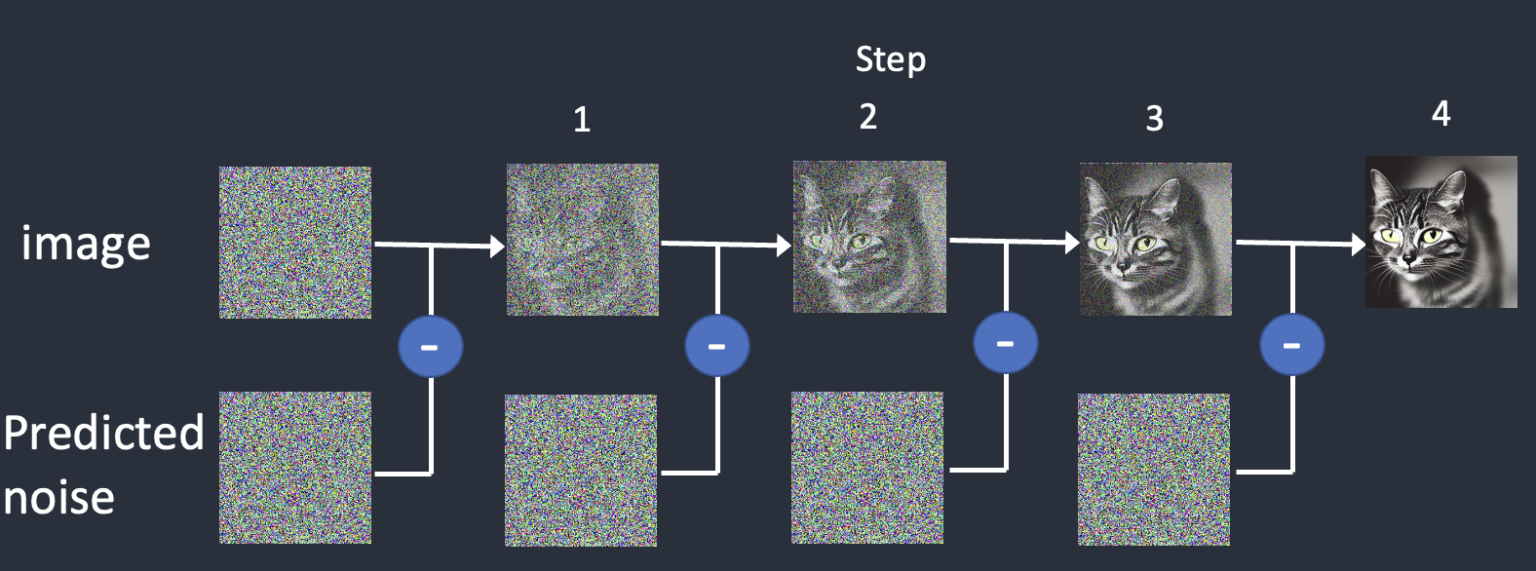
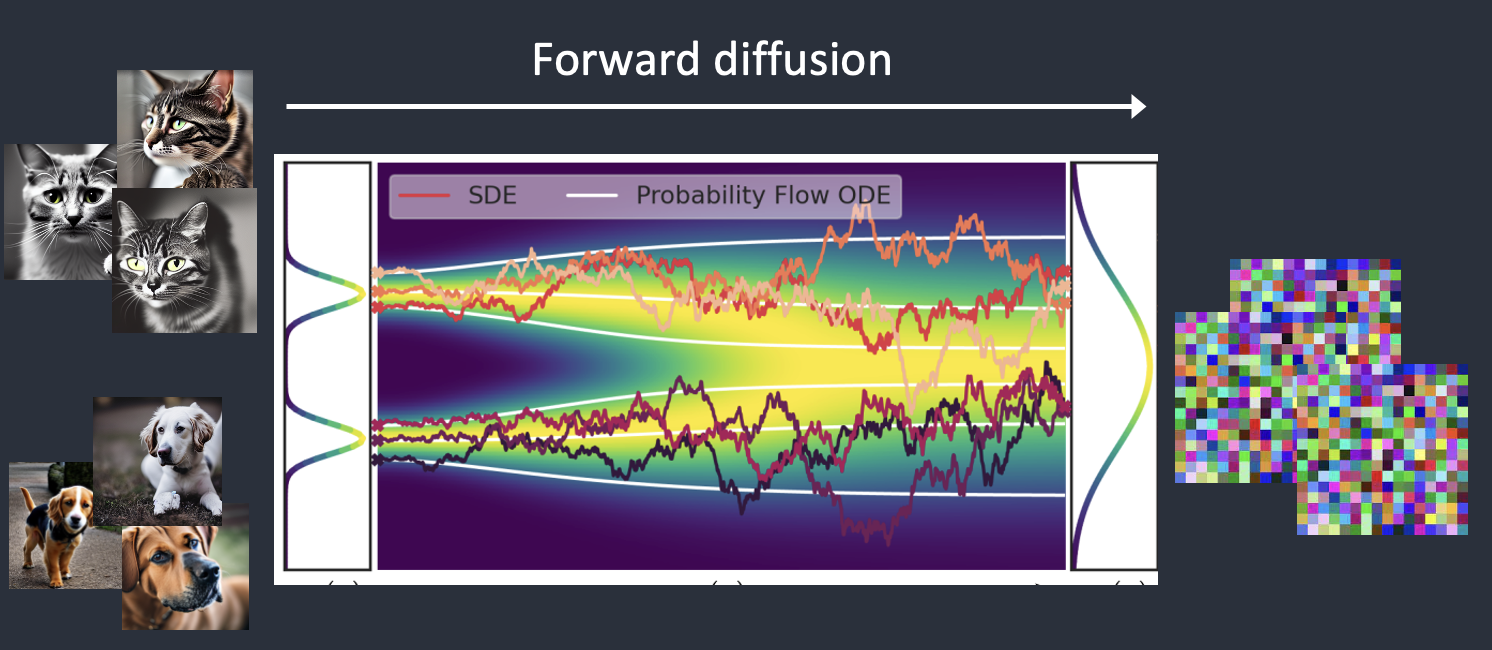
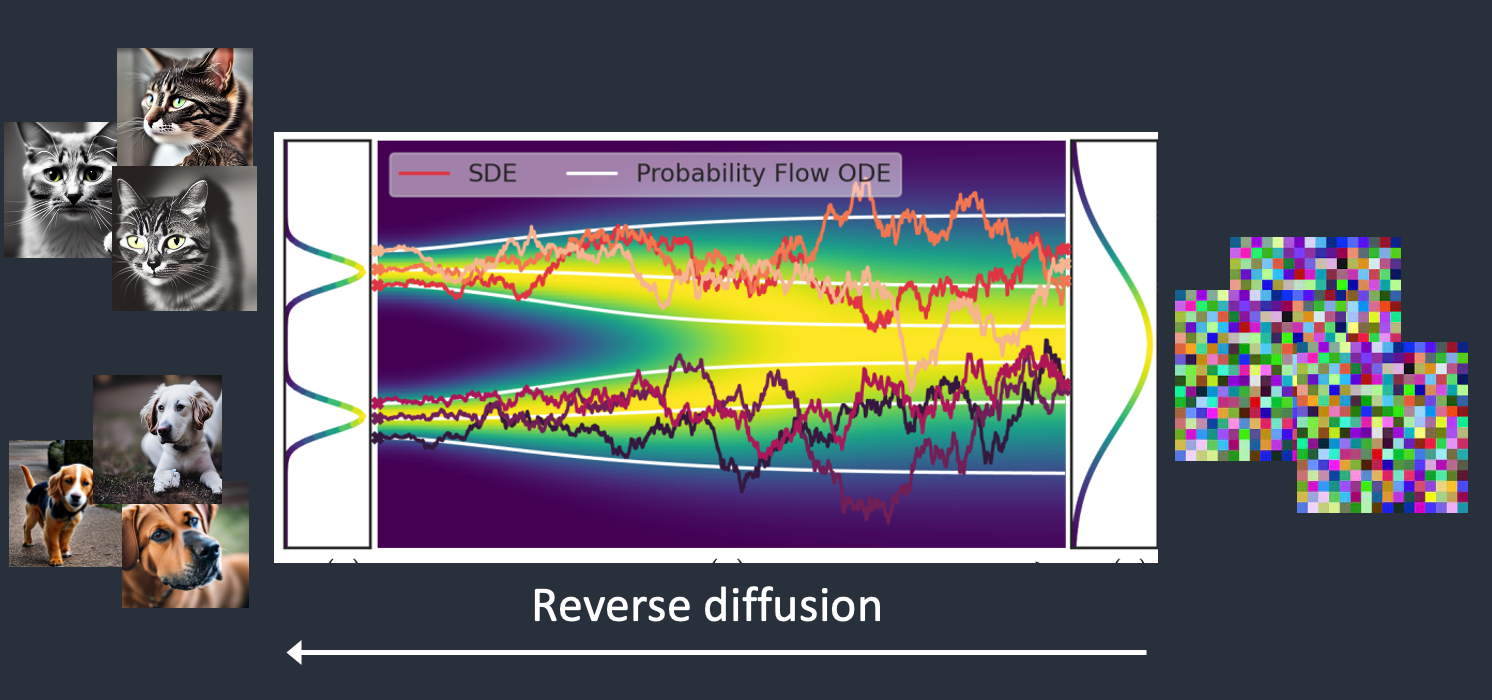
Stable Diffusion belongs to a class of deep learning models called diffusion models. They are generative models, meaning they are designed to generate new data similar to what they have seen in training. In the case of Stable Diffusion, the data are images.
Why is it called the diffusion model? Because its math looks very much like diffusion in physics. Let’s go through the idea.
“Not every light performs the same way. Lights and lighting are tricky to handle. You have to plan for every circumstance. But the good news is, lighting can be adjusted. Let’s look at different factors that affect lighting in every scene you shoot. “
Use CRI, Luminous Efficacy and color temperature controls to match your needs.
Color Temperature Color temperature describes the “color” of white light by a light source radiated by a perfect black body at a given temperature measured in degrees Kelvin
CRI “The Color Rendering Index is a measurement of how faithfully a light source reveals the colors of whatever it illuminates, it describes the ability of a light source to reveal the color of an object, as compared to the color a natural light source would provide. The highest possible CRI is 100. A CRI of 100 generally refers to a perfect black body, like a tungsten light source or the sun. “