Finn Jäger has spent some time in making a sleeker tool for all you VFX nerds out there, it takes a HEIC iPhone still and exports a Multichannel EXR – the cool thing is it also converts it to acesCG and it merges the SDR base image with the gain map according to apples math hdr_rgb = sdr_rgb * (1.0 + (headroom – 1.0) * gainmap)
Brandolini’s law (or the bullshit asymmetry principle) is an internet adage coined in 2013 by Italian programmer Alberto Brandolini. It compares the considerable effort of debunking misinformation to the relative ease of creating it in the first place.
The law states: “The amount of energy needed to refute bullshit is an order of magnitude bigger than to produce it.”
This is why every time you kill a lie, it feels like nothing changed. It’s why no matter how many facts you post, how many sources you cite, how many receipts you show—the swarm just keeps coming. Because while you’re out in the open doing surgery, the machine is behind the curtain spraying aerosol deceit into every vent.
The lie takes ten seconds. The truth takes ten paragraphs. And by the time you’ve written the tenth, the people you’re trying to reach have already scrolled past.
Every viral deception—the fake quote, the rigged video, the synthetic outrage—takes almost nothing to create. And once it’s out there, you’re not just correcting a fact—you’re prying it out of someone’s identity. Because people don’t adopt lies just for information. They adopt them for belonging. The lie becomes part of who they are, and your correction becomes an attack.
And still—you must correct it. Still, you must fight.
Because even if truth doesn’t spread as fast, it roots deeper. Even if it doesn’t go viral, it endures. And eventually, it makes people bulletproof to the next wave of narrative sewage.
You’re not here to win a one-day war. You’re here to outlast a never-ending invasion.
The lies are roaches. You kill one, and a hundred more scramble behind the drywall.The lies are Hydra heads. You cut one off, and two grow back. But you keep swinging anyway.
Because this isn’t about instant wins. It’s about making the cost of lying higher. It’s about being the resistance that doesn’t fold. You don’t fight because it’s easy. You fight because it’s right.
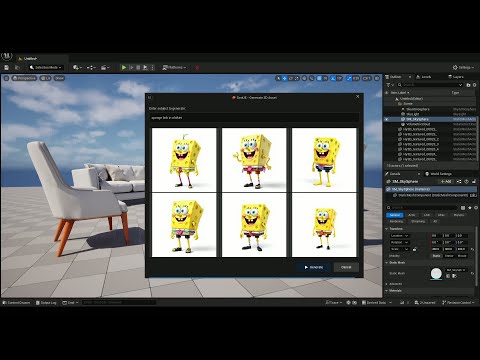
GenUE brings prompt-driven 3D asset creation directly into Unreal Engine using ComfyUI as a flexible backend. • Generate high-quality images from text prompts. • Choose from a catalog of batch-generated images – no style limitations. • Convert the selected image to a fully textured 3D mesh. • Automatically import and place the model into your Unreal Engine scene. This modular pipeline gives you full control over the image and 3D generation stages, with support for any ComfyUI workflow or model. Full generation (image + mesh + import) completes in under 2 minutes on a high-end consumer GPU.
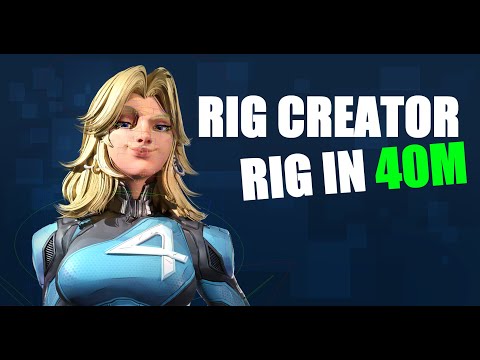
What it offers: • Base rigs for multiple character types • Automatic weight application • Built-in facial rigging system • Bone generators with FK and IK options • Streamlined constraint panel
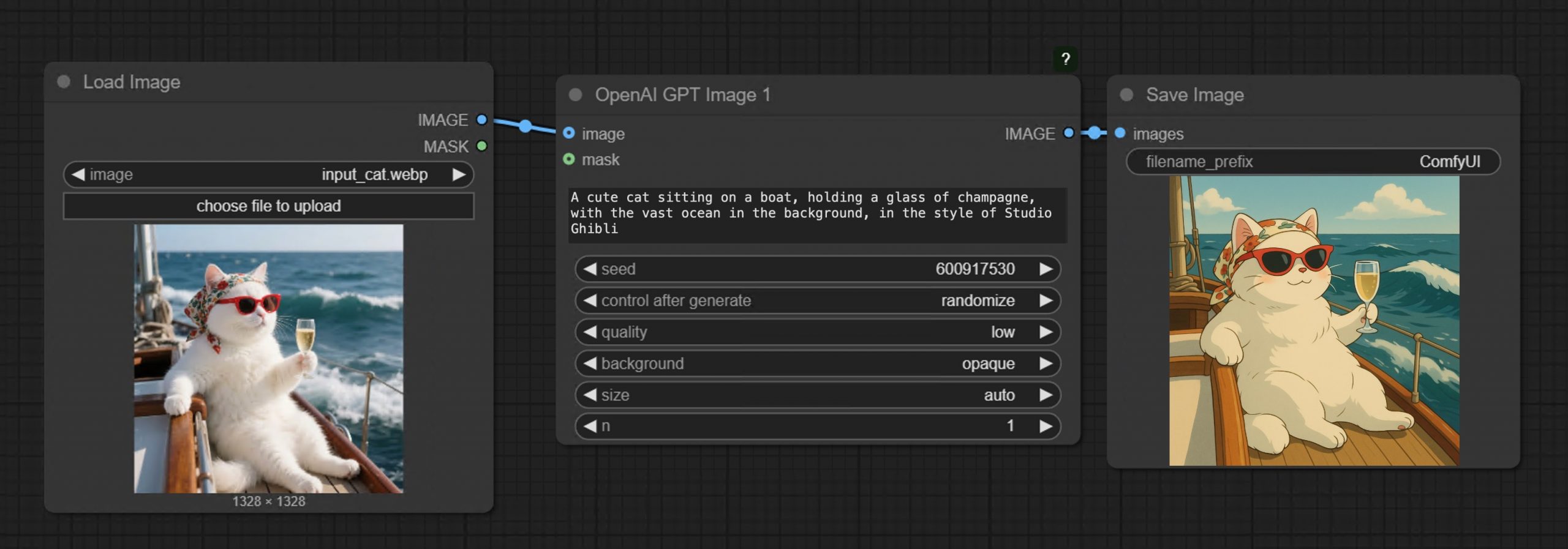
• Prompt GPT-Image-1 directly in ComfyUI using text or image inputs • Set resolution and quality • Supports image editing + transparent backgrounds • Seamlessly mix with local workflows like WAN 2.1, FLUX Tools, and more
What makes it special? • Massive 10B parameter geometric model with 10x more mesh faces. • High-quality textures with industry-first multi-view PBR generation. • Optimized skeletal rigging for streamlined animation workflows. • Flexible pipeline for text-to-3D and image-to-3D generation.
They’re making it accessible to everyone: • Open-source code and pre-trained models. • Easy-to-use API and intuitive web interface. • Free daily quota doubled to 20 generations!
Video try-on replaces clothing in videos with target garments. Existing methods struggle to generate high-quality and temporally consistent results when handling complex clothing patterns and diverse body poses. We present 3DV-TON, a novel diffusion-based framework for generating high-fidelity and temporally consistent video try-on results. Our approach employs generated animatable textured 3D meshes as explicit frame-level guidance, alleviating the issue of models over-focusing on appearance fidelity at the expanse of motion coherence. This is achieved by enabling direct reference to consistent garment texture movements throughout video sequences. The proposed method features an adaptive pipeline for generating dynamic 3D guidance: (1) selecting a keyframe for initial 2D image try-on, followed by (2) reconstructing and animating a textured 3D mesh synchronized with original video poses. We further introduce a robust rectangular masking strategy that successfully mitigates artifact propagation caused by leaking clothing information during dynamic human and garment movements. To advance video try-on research, we introduce HR-VVT, a high-resolution benchmark dataset containing 130 videos with diverse clothing types and scenarios. Quantitative and qualitative results demonstrate our superior performance over existing methods.
AutoGPT is a remarkable AI technology that utilizes GPT-4 and GPT-3.5 through API to create full-fledged projects by iterating on its own prompts and building upon them in each iteration. It can read and write files, browse the web, review the results of its prompts, and combine them with the prompt history.
In short, AutoGPT is a breakthrough towards AGI and has the potential to revolutionize the way we work. It can be given an AI name such as RecipeBuilder and 5 goals that it has to meet. Once the goals are set, AutoGPT can start working on the project until completion.
It is worth noting that AutoGPT is prone to fall into loops and make pointless requests when given complicated tasks. However, for simple jobs, the outcomes are amazing. AutoGPT uses credits from your OpenAI account, and the free version includes $18. Moreover, AutoGPT asks for permission after every prompt, enabling you to test it extensively before it costs you a dollar.
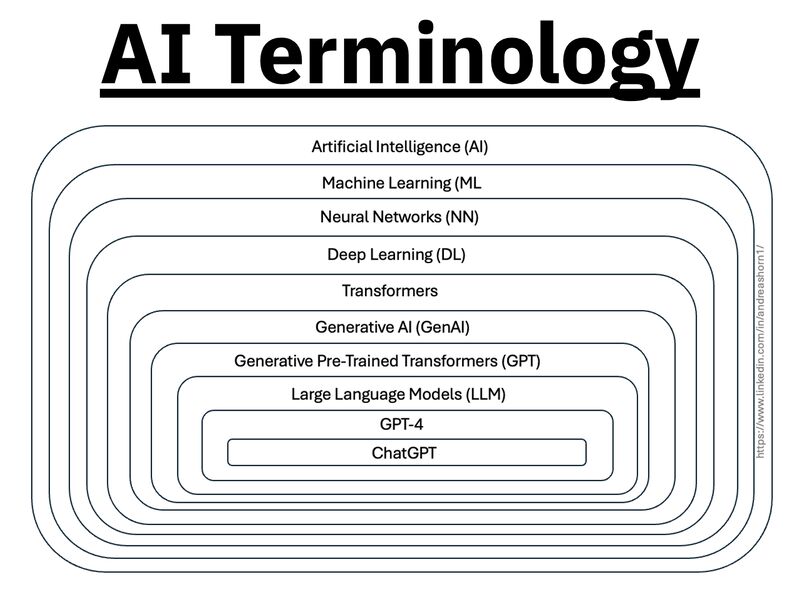
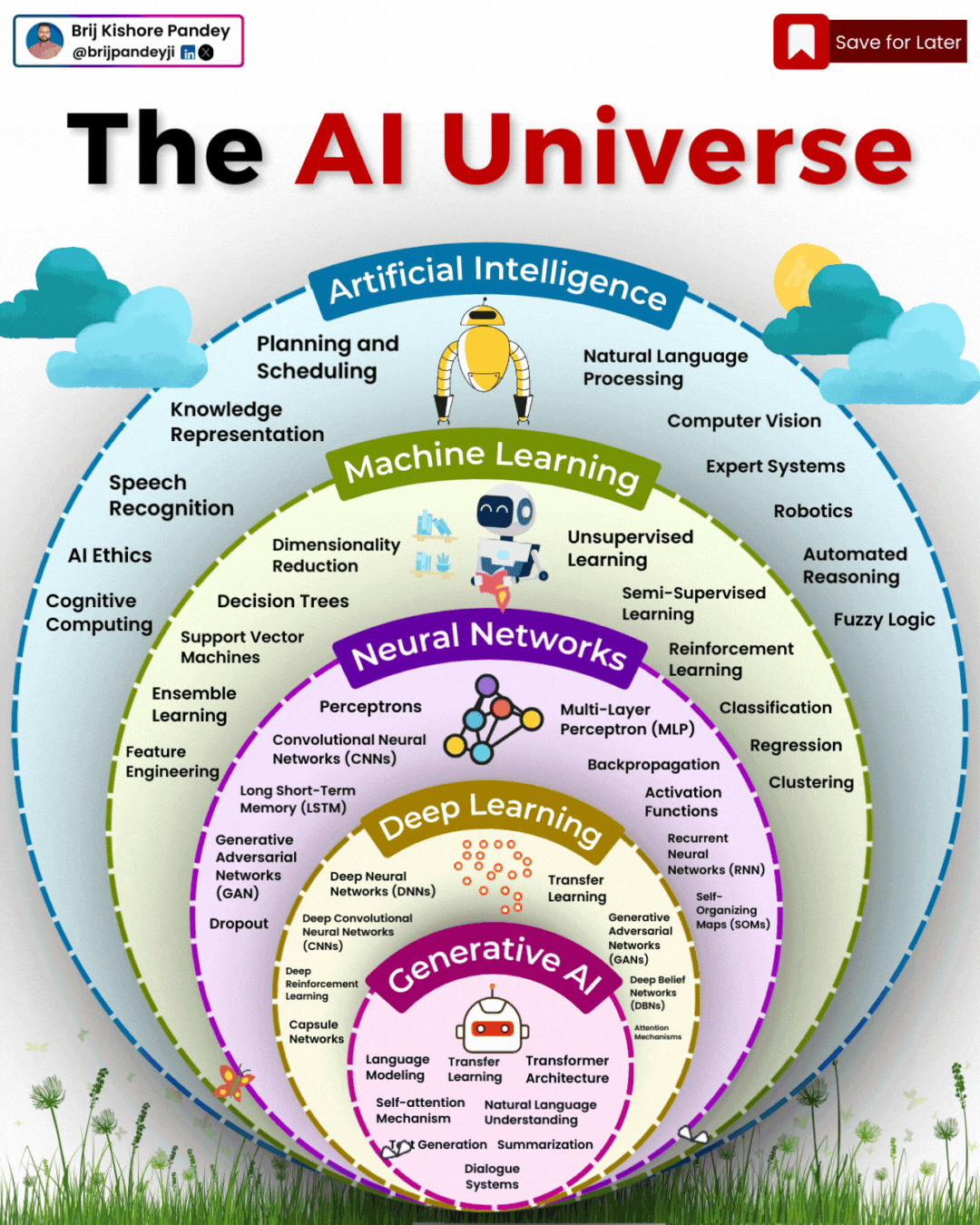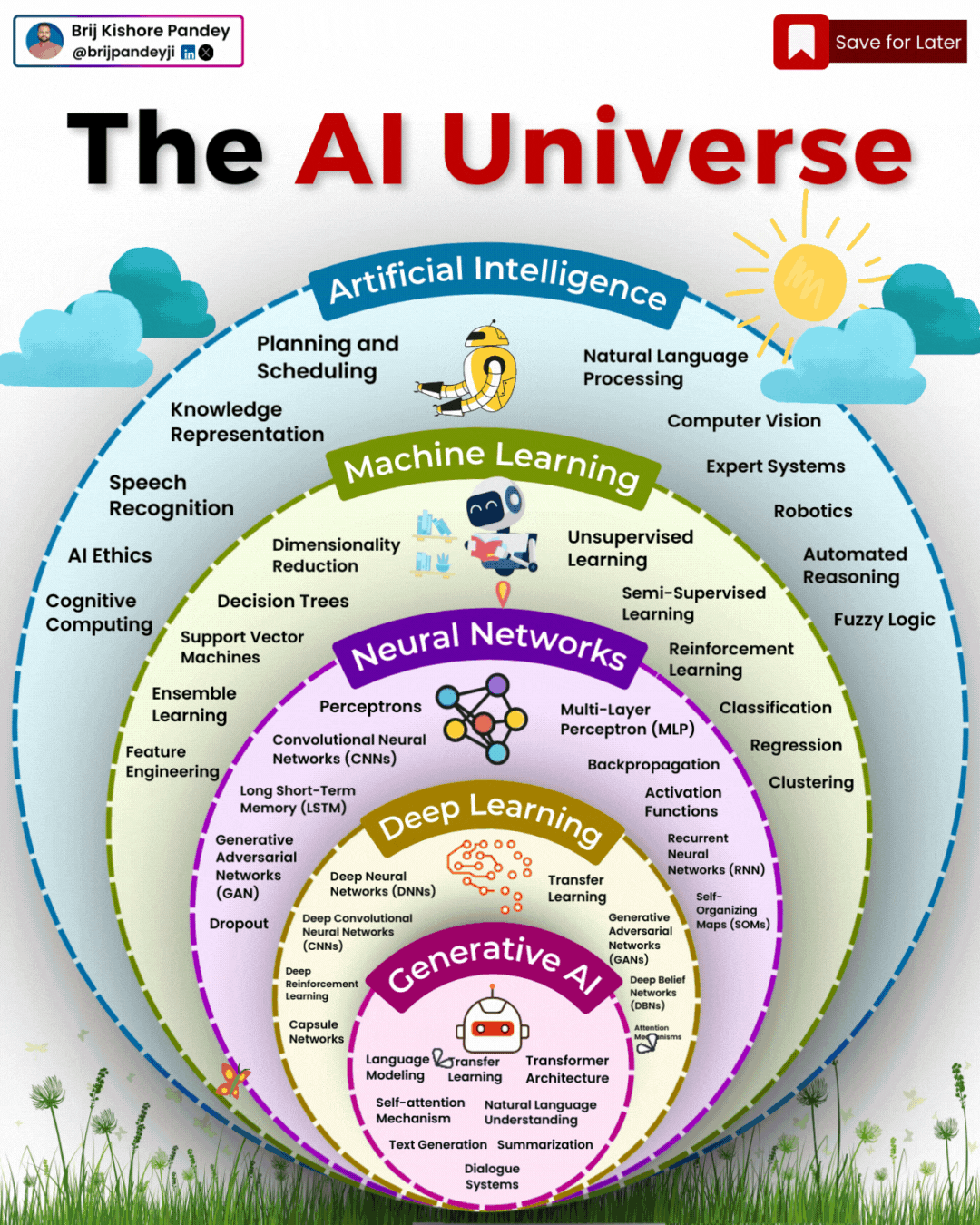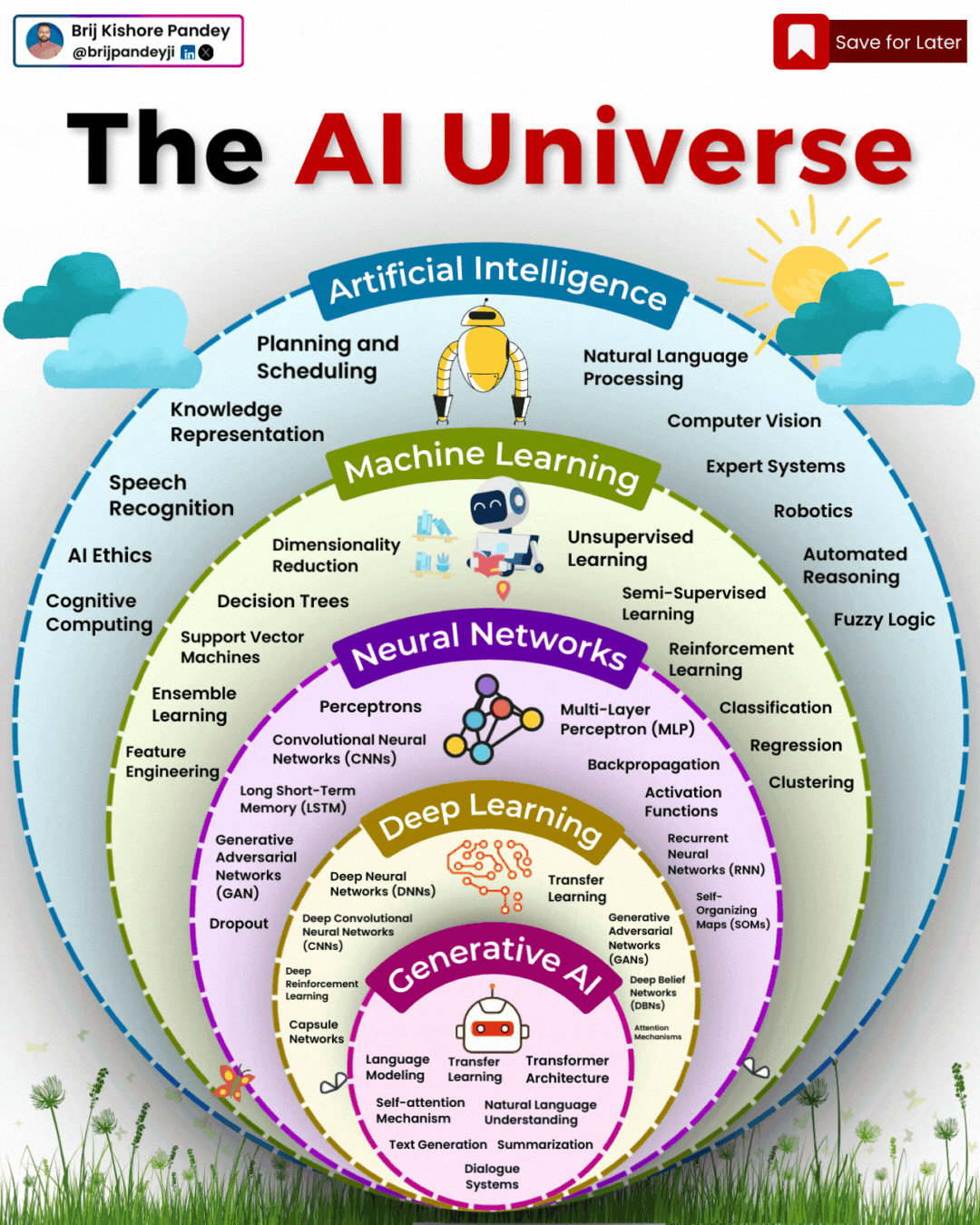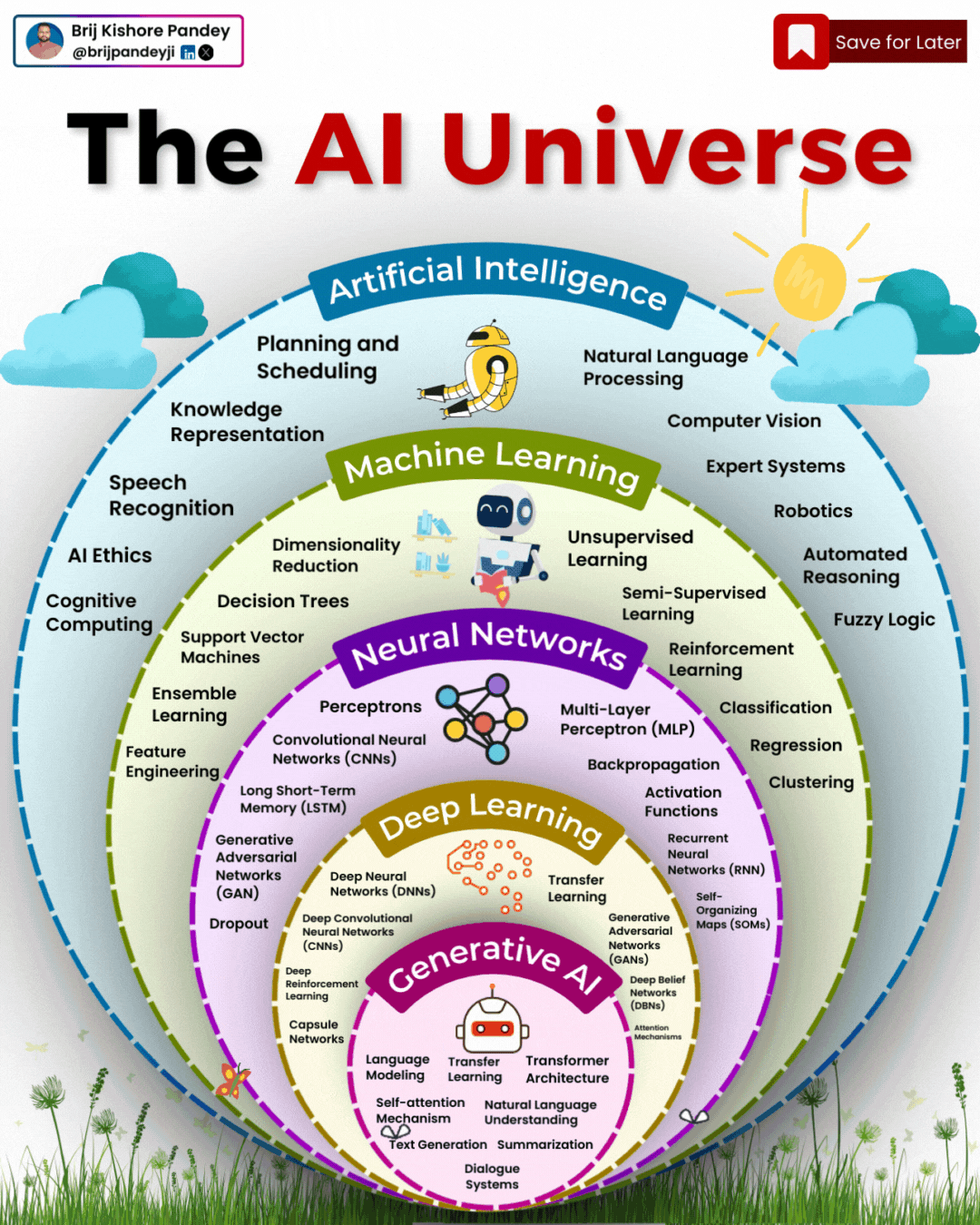
1️⃣ 𝗔𝗿𝘁𝗶𝗳𝗶𝗰𝗶𝗮𝗹 𝗜𝗻𝘁𝗲𝗹𝗹𝗶𝗴𝗲𝗻𝗰𝗲 (𝗔𝗜) – The broadest category, covering automation, reasoning, and decision-making. Early AI was rule-based, but today, it’s mainly data-driven. 2️⃣ 𝗠𝗮𝗰𝗵𝗶𝗻𝗲 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 (𝗠𝗟) – AI that learns patterns from data without explicit programming. Includes decision trees, clustering, and regression models. 3️⃣ 𝗡𝗲𝘂𝗿𝗮𝗹 𝗡𝗲𝘁𝘄𝗼𝗿𝗸𝘀 (𝗡𝗡) – A subset of ML, inspired by the human brain, designed for pattern recognition and feature extraction. 4️⃣ 𝗗𝗲𝗲𝗽 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 (𝗗𝗟) – Multi-layered neural networks that drives a lot of modern AI advancements, for example enabling image recognition, speech processing, and more. 5️⃣ 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗲𝗿𝘀 – A revolutionary deep learning architecture introduced by Google in 2017 that allows models to understand and generate language efficiently. 6️⃣ 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝘃𝗲 𝗔𝗜 (𝗚𝗲𝗻𝗔𝗜) – AI that doesn’t just analyze data—it creates. From text and images to music and code, this layer powers today’s most advanced AI models. 7️⃣ 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝘃𝗲 𝗣𝗿𝗲-𝗧𝗿𝗮𝗶𝗻𝗲𝗱 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗲𝗿𝘀 (𝗚𝗣𝗧) – A specific subset of Generative AI that uses transformers for text generation. 8️⃣ 𝗟𝗮𝗿𝗴𝗲 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹𝘀 (𝗟𝗟𝗠) – Massive AI models trained on extensive datasets to understand and generate human-like language. 9️⃣ 𝗚𝗣𝗧-4 – One of the most advanced LLMs, built on transformer architecture, trained on vast datasets to generate human-like responses. 🔟 𝗖𝗵𝗮𝘁𝗚𝗣𝗧 – A specific application of GPT-4, optimized for conversational AI and interactive use.
Spectral sensitivity of eye is influenced by light intensity. And the light intensity determines the level of activity of cones cell and rod cell. This is the main characteristic of human vision. Sensitivity to individual colors, in other words, wavelengths of the light spectrum, is explained by the RGB (red-green-blue) theory. This theory assumed that there are three kinds of cones. It’s selectively sensitive to red (700-630 nm), green (560-500 nm), and blue (490-450 nm) light. And their mutual interaction allow to perceive all colors of the spectrum.
Spectral sensitivity of eye is influenced by light intensity. And the light intensity determines the level of activity of cones cell and rod cell. This is the main characteristic of human vision. Sensitivity to individual colors, in other words, wavelengths of the light spectrum, is explained by the RGB (red-green-blue) theory. This theory assumed that there are three kinds of cones. It’s selectively sensitive to red (700-630 nm), green (560-500 nm), and blue (490-450 nm) light. And their mutual interaction allow to perceive all colors of the spectrum.
An exposure stop is a unit measurement of Exposure as such it provides a universal linear scale to measure the increase and decrease in light, exposed to the image sensor, due to changes in shutter speed, iso and f-stop.
+-1 stop is a doubling or halving of the amount of light let in when taking a photo
1 EV (exposure value) is just another way to say one stop of exposure change.
Same applies to shutter speed, iso and aperture.
Doubling or halving your shutter speed produces an increase or decrease of 1 stop of exposure.
Doubling or halving your iso speed produces an increase or decrease of 1 stop of exposure.


























{kind=link}


