BREAKING NEWS
LATEST POSTS
-
VillageRoadShow production studio files for bankruptcy
Village Roadshow (prod company/financier: Wonka, the Matrix series, and Ocean’s 11) has filed for bankruptcy.
It’s a rough indicator of where we are in 2025 when one of the last independent production companies working with the studios goes under.
Here’s their balance sheet:
$400 M in library value of 100+ films (89 of which they co-own with Warner Bros.)
$500 M – $1bn total debt
$1.4 M in debt to WGA, whose members were told to stop working with Roadshow in December
$794 K owed to Bryan Cranston’s prod company
$250 K owed to Sony Pictures TV
$300 K/month overhead
The crowning expense that brought down this 36-year-old production company is the $18 M in (unpaid) legal fees from a lengthy and currently unresolved arbitration with their long-time partner Warner Bros, who they’ve had a co-financing arrangement since the late 90s.
Roadshow sued when WBD released their Matrix Resurrections (2021) film in theaters and on Max simultaneously, causing Roadshow to withhold their portion of the $190 M production costs.
Due to mounting financial pressures, Village Roadshow’s CEO, Steve Mosko, a veteran film and TV exec, left the company in January.
Now, this all falls on the shoulders of Jim Moore, CEO of Vine, an equity firm that owns Village Roadshow, as well as Luc Besson’s prod company EuropaCorp.
-
Google Gemini Robotics

For safety considerations, Google mentions a “layered, holistic approach” that maintains traditional robot safety measures like collision avoidance and force limitations. The company describes developing a “Robot Constitution” framework inspired by Isaac Asimov’s Three Laws of Robotics and releasing a dataset unsurprisingly called “ASIMOV” to help researchers evaluate safety implications of robotic actions.
This new ASIMOV dataset represents Google’s attempt to create standardized ways to assess robot safety beyond physical harm prevention. The dataset appears designed to help researchers test how well AI models understand the potential consequences of actions a robot might take in various scenarios. According to Google’s announcement, the dataset will “help researchers to rigorously measure the safety implications of robotic actions in real-world scenarios.”

-
Personalize Anything – For Free with Diffusion Transformer
https://fenghora.github.io/Personalize-Anything-Page
Customize any subject with advanced DiT without additional fine-tuning.

-
Google Gemini 2.0 Flash new AI model extremely proficient at removing watermarks from images
Gemini 2.0 Flash won’t just remove watermarks, but will also attempt to fill in any gaps created by a watermark’s deletion. Other AI-powered tools do this, too, but Gemini 2.0 Flash seems to be exceptionally skilled at it — and free to use.

-
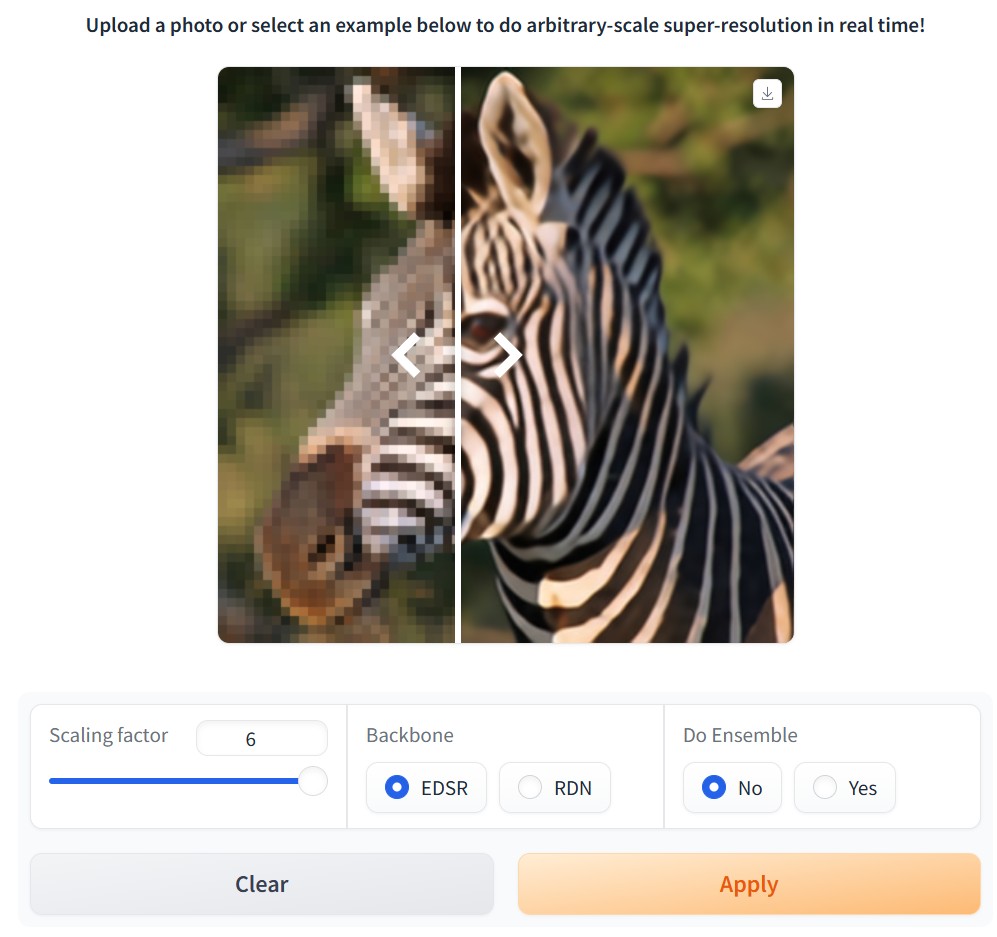
Stability.ai – Introducing Stable Virtual Camera: Multi-View Video Generation with 3D Camera Control
Capabilities
Stable Virtual Camera offers advanced capabilities for generating 3D videos, including:
- Dynamic Camera Control: Supports user-defined camera trajectories as well as multiple dynamic camera paths, including: 360°, Lemniscate (∞ shaped path), Spiral, Dolly Zoom In, Dolly Zoom Out, Zoom In, Zoom Out, Move Forward, Move Backward, Pan Up, Pan Down, Pan Left, Pan Right, and Roll.
- Flexible Inputs: Generates 3D videos from just one input image or up to 32.
- Multiple Aspect Ratios: Capable of producing videos in square (1:1), portrait (9:16), landscape (16:9), and other custom aspect ratios without additional training.
- Long Video Generation: Ensures 3D consistency in videos up to 1,000 frames, enabling seamless
Model limitations
In its initial version, Stable Virtual Camera may produce lower-quality results in certain scenarios. Input images featuring humans, animals, or dynamic textures like water often lead to degraded outputs. Additionally, highly ambiguous scenes, complex camera paths that intersect objects or surfaces, and irregularly shaped objects can cause flickering artifacts, especially when target viewpoints differ significantly from the input images.














FEATURED POSTS


-
Microsoft DAViD – Data-efficient and Accurate Vision Models from Synthetic Data
Our human-centric dense prediction model delivers high-quality, detailed (depth) results while achieving remarkable efficiency, running orders of magnitude faster than competing methods, with inference speeds as low as 21 milliseconds per frame (the large multi-task model on an NVIDIA A100). It reliably captures a wide range of human characteristics under diverse lighting conditions, preserving fine-grained details such as hair strands and subtle facial features. This demonstrates the model’s robustness and accuracy in complex, real-world scenarios.
https://microsoft.github.io/DAViD

The state of the art in human-centric computer vision achieves high accuracy and robustness across a diverse range of tasks. The most effective models in this domain have billions of parameters, thus requiring extremely large datasets, expensive training regimes, and compute-intensive inference. In this paper, we demonstrate that it is possible to train models on much smaller but high-fidelity synthetic datasets, with no loss in accuracy and higher efficiency. Using synthetic training data provides us with excellent levels of detail and perfect labels, while providing strong guarantees for data provenance, usage rights, and user consent. Procedural data synthesis also provides us with explicit control on data diversity, that we can use to address unfairness in the models we train. Extensive quantitative assessment on real input images demonstrates accuracy of our models on three dense prediction tasks: depth estimation, surface normal estimation, and soft foreground segmentation. Our models require only a fraction of the cost of training and inference when compared with foundational models of similar accuracy.
-
Paul Debevec, Chloe LeGendre, Lukas Lepicovsky – Jointly Optimizing Color Rendition and In-Camera Backgrounds in an RGB Virtual Production Stage
https://arxiv.org/pdf/2205.12403.pdf
RGB LEDs vs RGBWP (RGB + lime + phospor converted amber) LEDs
Local copy:
-
Google – Artificial Intelligence free courses
1. Introduction to Large Language Models: Learn about the use cases and how to enhance the performance of large language models.
https://www.cloudskillsboost.google/course_templates/5392. Introduction to Generative AI: Discover the differences between Generative AI and traditional machine learning methods.
https://www.cloudskillsboost.google/course_templates/5363. Generative AI Fundamentals: Earn a skill badge by demonstrating your understanding of foundational concepts in Generative AI.
https://www.cloudskillsboost.google/paths4. Introduction to Responsible AI: Learn about the importance of Responsible AI and how Google implements it in its products.
https://www.cloudskillsboost.google/course_templates/5545. Encoder-Decoder Architecture: Learn about the encoder-decoder architecture, a critical component of machine learning for sequence-to-sequence tasks.
https://www.cloudskillsboost.google/course_templates/5436. Introduction to Image Generation: Discover diffusion models, a promising family of machine learning models in the image generation space.
https://www.cloudskillsboost.google/course_templates/5417. Transformer Models and BERT Model: Get a comprehensive introduction to the Transformer architecture and the Bidirectional Encoder Representations from the Transformers (BERT) model.
https://www.cloudskillsboost.google/course_templates/5388. Attention Mechanism: Learn about the attention mechanism, which allows neural networks to focus on specific parts of an input sequence.
https://www.cloudskillsboost.google/course_templates/537
-
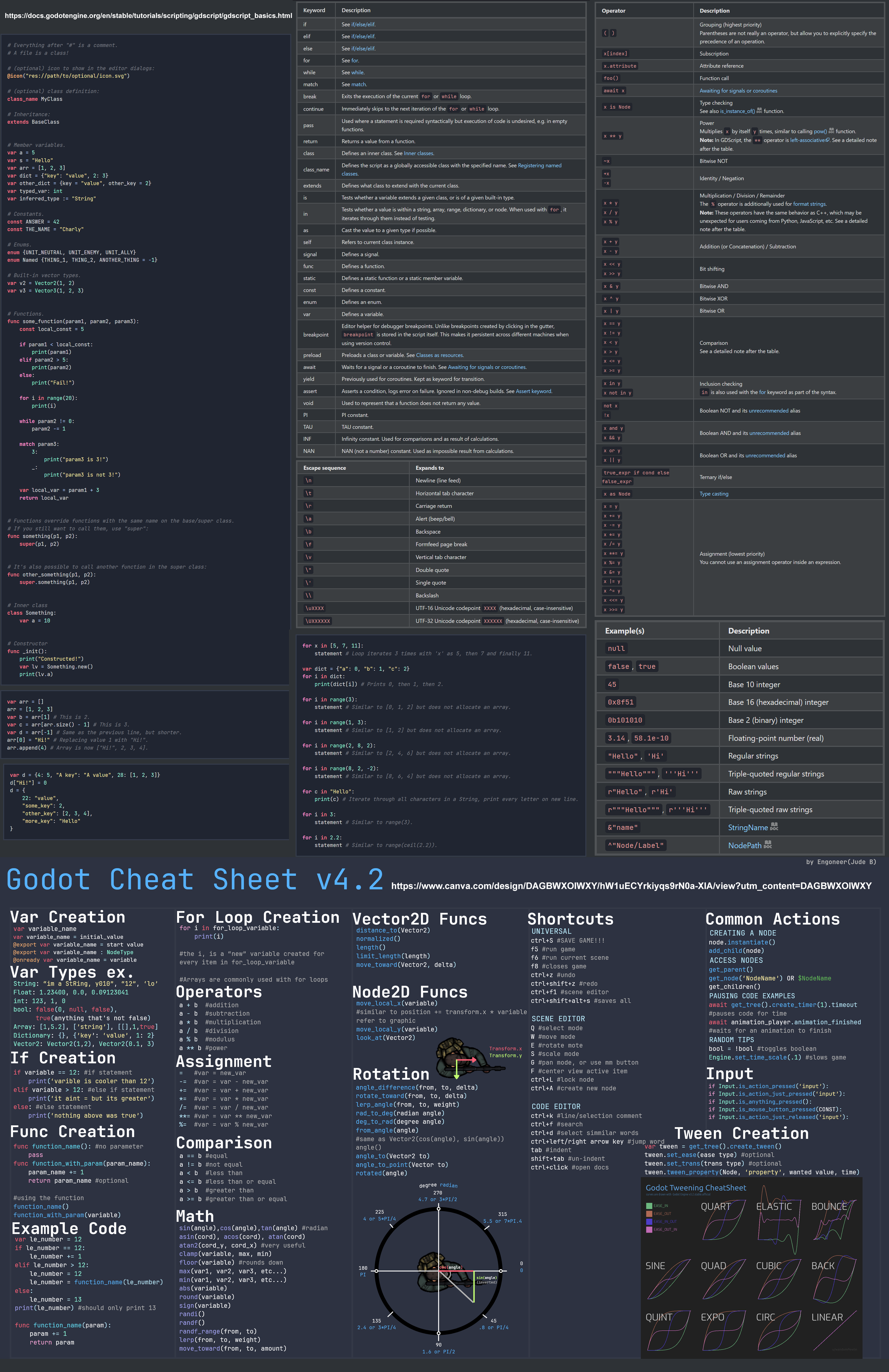
Godot Cheat Sheets
https://docs.godotengine.org/en/stable/tutorials/scripting/gdscript/gdscript_basics.html
https://www.canva.com/design/DAGBWXOIWXY/hW1uECYrkiyqs9rN0a-XIA/view?utm_content=DAGBWXOIWXY
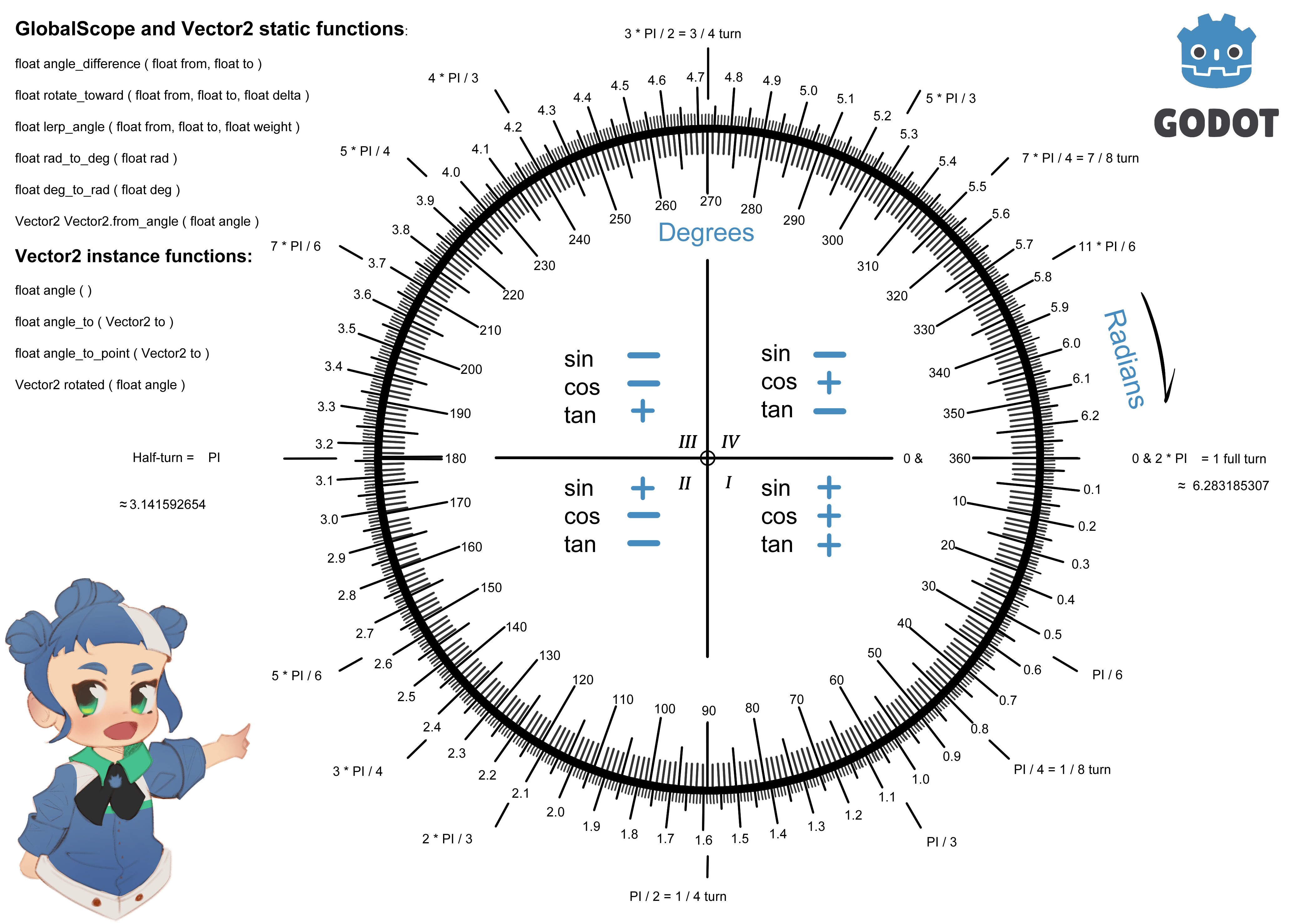
https://www.reddit.com/r/godot/comments/18aid4u/unit_circle_in_godot_format_version_2_by_foxsinart/
Images in the post
<!–more–>