By inputting a single character image and template pose video, our method can generate vocal avatar videos featuring not only pose-accurate rendering but also realistic body shapes.
Given an input video and a simple user-provided text instruction describing the desired content, our method synthesizes dynamic objects or complex scene effects that naturally interact with the existing scene over time. The position, appearance, and motion of the new content are seamlessly integrated into the original footage while accounting for camera motion, occlusions, and interactions with other dynamic objects in the scene, resulting in a cohesive and realistic output video.
They propose an end-to-end multimodality-conditioned human video generation framework named OmniHuman, which can generate human videos based on a single human image and motion signals (e.g., audio only, video only, or a combination of audio and video). In OmniHuman, we introduce a multimodality motion conditioning mixed training strategy, allowing the model to benefit from data scaling up of mixed conditioning. This overcomes the issue that previous end-to-end approaches faced due to the scarcity of high-quality data. OmniHuman significantly outperforms existing methods, generating extremely realistic human videos based on weak signal inputs, especially audio. It supports image inputs of any aspect ratio, whether they are portraits, half-body, or full-body images, delivering more lifelike and high-quality results across various scenarios.
In the Golden Age of Hollywood (1930-1959), a 10:1 shooting ratio was the norm—a 90-minute film meant about 15 hours of footage. Directors like Alfred Hitchcock famously kept it tight with a 3:1 ratio, giving studios little wiggle room in the edit.
Fast forward to today: the digital era has sent shooting ratios skyrocketing. Affordable cameras roll endlessly, capturing multiple takes, resets, and everything in between. Gone are the disciplined “Action to Cut” days of film.
GOT-OCR2 works on a wide range of tasks, including plain document OCR, scene text OCR, formatted document OCR, and even OCR for tables, charts, mathematical formulas, geometric shapes, molecular formulas and sheet music.
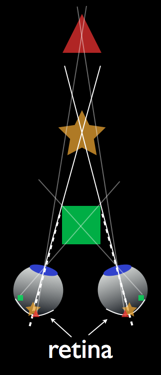
The average interocular of humans is considered to be about 65mm (2.5 inches.) When this same distance is used as the interaxial distance between two shooting cameras then the resulting stereoscopic effect is typically known as “Ortho-stereo.” Many stereographers choose 2.5” as a stereo-base for this reason.
If the interaxial distance used to shoot is smaller than 2.5 inches then you are shooting “Hypo-stereo.” This technique is common for theatrically released films to accommodate the effects of the big screen. It is also used for macro stereoscopic photography.
Hyper-stereo refers to interaxial distances greater than 2.5 inches. As I mentioned earlier the greater the interaxial separation, the greater the depth effect. An elephant can perceive much more depth than a human, and a human can perceive more depth than a mouse.
However, using this same analogy, the mouse can get close and peer inside the petals of a flower with very good depth perception, and the human will just go “cross-eyed.” Therefore decreasing the interaxial separation between two cameras to 1” or less will allow you to shoot amazing macro stereo-photos and separating the cameras to several feet apart will allow great depth on mountain ranges, city skylines and other vistas.
The trouble with using hyper-stereo is that scenes with gigantic objects in real-life may appear as small models. This phenomenon is known as dwarfism and we perceive it this way because the exaggerated separation between the taking lenses allows us to see around big objects much more that we do in the real world. Our brain interprets this as meaning the object must be small.
The opposite happens with hypo-stereo, where normal sized objects appear gigantic. (Gigantism.)
Tired of having iTunes messing up your mp3 library? … Time to try MiniTunes!
– Arrange your library by Genre, Artists or Albums. – Change UI colors at will. – Edit tags and create playlists. – Consolidate your library once for all. – Windows 64 only
5.10 of this tool includes excellent tools to clean up cr2 and cr3 used on set to support HDRI processing.
Converting raw to AcesCG 32 bit tiffs with metadata.