



BREAKING NEWS
LATEST POSTS
-
Brian Gallagher – Why Almost Everybody Is Wrong About DeepSeek vs. All the Other AI Companies
Benchmarks don’t capture real-world complexity like latency, domain-specific tasks, or edge cases. Enterprises often need more than raw performance, also needing reliability, ease of integration, and robust vendor support. Enterprise money will support the industries providing these services.
… it is also reasonable to assume that anything you put into the app or their website will be going to the Chinese government as well, so factor that in as well.
-
One-Prompt-One-Story – Free-Lunch Consistent Text-to-Image Generation Using a Single Prompt
https://byliutao.github.io/1Prompt1Story.github.io
Tneration models can create high-quality images from input prompts. However, they struggle to support the consistent generation of identity-preserving requirements for storytelling.
Our approach 1Prompt1Story concatenates all prompts into a single input for T2I diffusion models, initially preserving character identities.

-
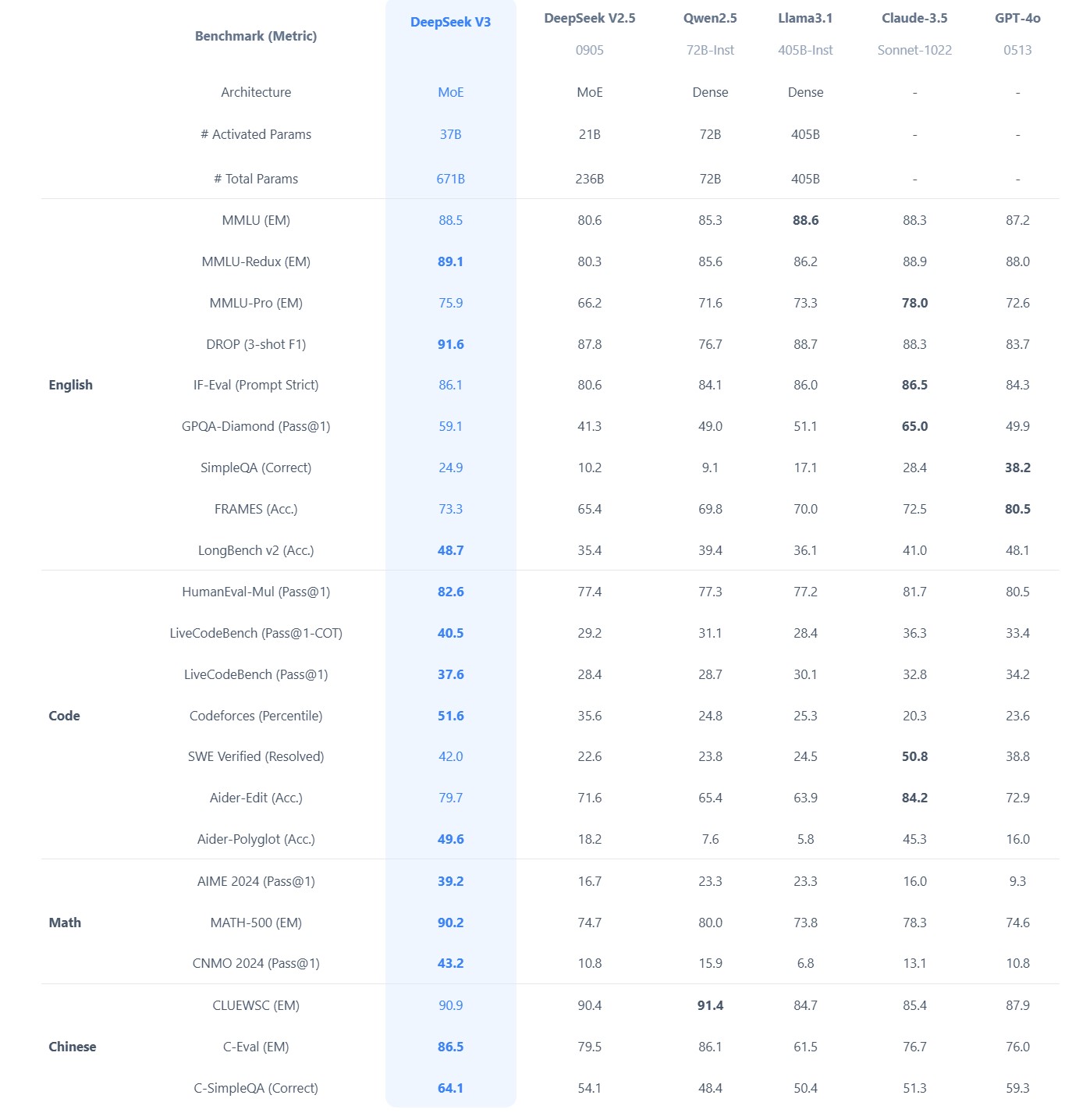
What did DeepSeek figure out about reasoning with DeepSeek-R1?
https://www.seangoedecke.com/deepseek-r1
The Chinese AI lab DeepSeek recently released their new reasoning model R1, which is supposedly (a) better than the current best reasoning models (OpenAI’s o1- series), and (b) was trained on a GPU cluster a fraction the size of any of the big western AI labs.
DeepSeek uses a reinforcement learning approach, not a fine-tuning approach. There’s no need to generate a huge body of chain-of-thought data ahead of time, and there’s no need to run an expensive answer-checking model. Instead, the model generates its own chains-of-thought as it goes.
The secret behind their success? A bold move to train their models using FP8 (8-bit floating-point precision) instead of the standard FP32 (32-bit floating-point precision).
…
By using a clever system that applies high precision only when absolutely necessary, they achieved incredible efficiency without losing accuracy.
…
The impressive part? These multi-token predictions are about 85–90% accurate, meaning DeepSeek R1 can deliver high-quality answers at double the speed of its competitors.Chinese AI firm DeepSeek has 50,000 NVIDIA H100 AI GPUs

-
CaPa – Carve-n-Paint Synthesisfor Efficient 4K Textured Mesh Generation
https://github.com/ncsoft/CaPa
a novel method for generating hyper-quality 4K textured mesh under only 30 seconds, providing 3D assets ready for commercial applications such as games, movies, and VR/AR.

-
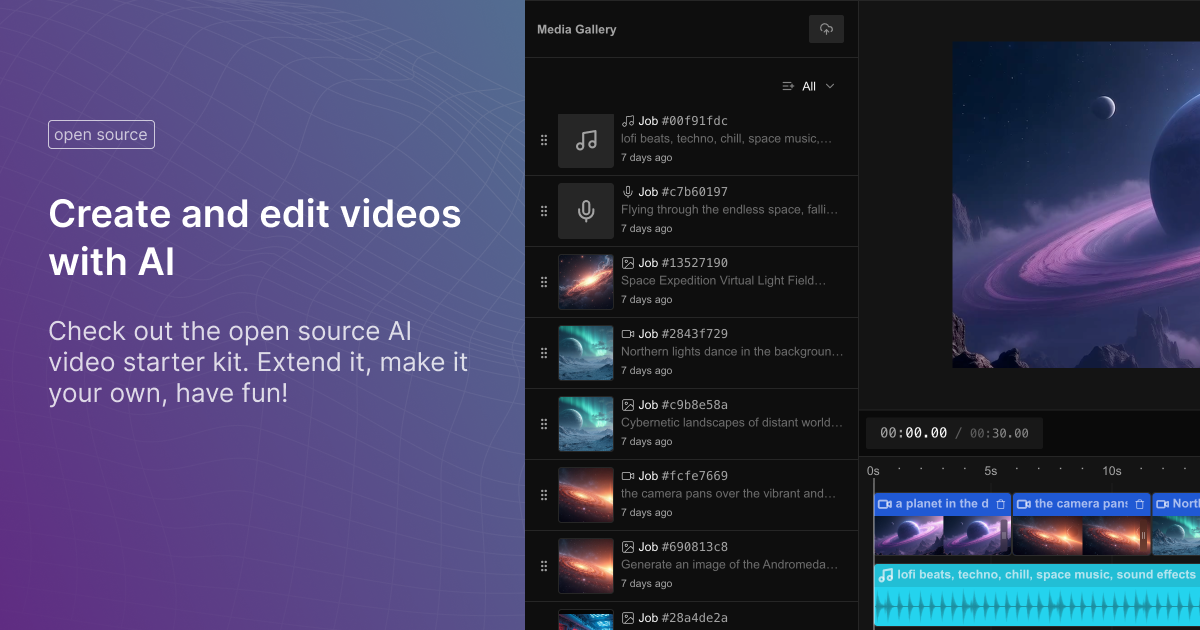
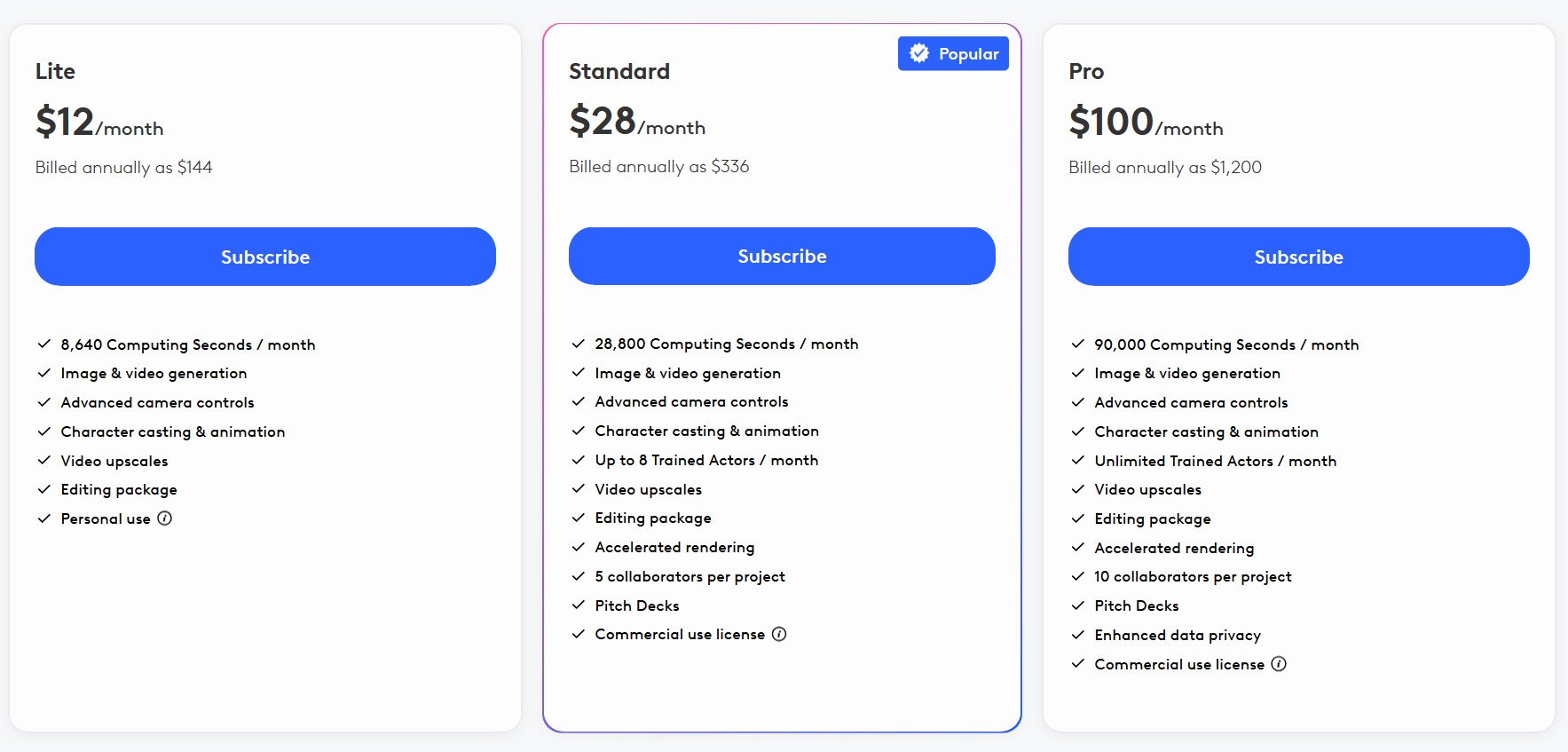
Fal Video Studio – The first open-source AI toolkit for video editing
https://github.com/fal-ai-community/video-starter-kit
https://fal-video-studio.vercel.app
- 🎬 Browser-Native Video Processing: Seamless video handling and composition in the browser
- 🤖 AI Model Integration: Direct access to state-of-the-art video models through fal.ai
- Minimax for video generation
- Hunyuan for visual synthesis
- LTX for video manipulation
- 🎵 Advanced Media Capabilities:
- Multi-clip video composition
- Audio track integration
- Voiceover support
- Extended video duration handling
- 🛠️ Developer Utilities:
- Metadata encoding
- Video processing pipeline
- Ready-to-use UI components
- TypeScript support






FEATURED POSTS




-
STOP FCC – SAVE THE FREE NET
Help saving free sites like this one.
The FCC voted to kill net neutrality and let ISPs like Comcast ruin the web with throttling, censorship, and new fees. Congress has 60 legislative days to overrule them and save the Internet using the Congressional Review Act
https://www.battleforthenet.com/http://mashable.com/2012/01/17/sopa-dangerous-opinion/

-
Zibra.AI – Real-Time Volumetric Effects in Virtual Production. Now free for Indies!


A New Era for Volumetrics
For a long time, volumetric visual effects were viable only in high-end offline VFX workflows. Large data footprints and poor real-time rendering performance limited their use: most teams simply avoided volumetrics altogether. It’s similar to the early days of online video: limited computational power and low network bandwidth made video content hard to share or stream. Today, of course, we can’t imagine the internet without it, and we believe volumetrics are on a similar path.
With advanced data compression and real-time, GPU-driven decompression, anyone can now bring CGI-class visual effects into Unreal Engine.
From now on, it’s completely free for individual creators!
What it means for you?
(more…)
-
Weta Digital – Manuka Raytracer and Gazebo GPU renderers – pipeline
https://jo.dreggn.org/home/2018_manuka.pdf
http://www.fxguide.com/featured/manuka-weta-digitals-new-renderer/

The Manuka rendering architecture has been designed in the spirit of the classic reyes rendering architecture. In its core, reyes is based on stochastic rasterisation of micropolygons, facilitating depth of field, motion blur, high geometric complexity,and programmable shading.
This is commonly achieved with Monte Carlo path tracing, using a paradigm often called shade-on-hit, in which the renderer alternates tracing rays with running shaders on the various ray hits. The shaders take the role of generating the inputs of the local material structure which is then used bypath sampling logic to evaluate contributions and to inform what further rays to cast through the scene.
Over the years, however, the expectations have risen substantially when it comes to image quality. Computing pictures which are indistinguishable from real footage requires accurate simulation of light transport, which is most often performed using some variant of Monte Carlo path tracing. Unfortunately this paradigm requires random memory accesses to the whole scene and does not lend itself well to a rasterisation approach at all.
Manuka is both a uni-directional and bidirectional path tracer and encompasses multiple importance sampling (MIS). Interestingly, and importantly for production character skin work, it is the first major production renderer to incorporate spectral MIS in the form of a new ‘Hero Spectral Sampling’ technique, which was recently published at Eurographics Symposium on Rendering 2014.
Manuka propose a shade-before-hit paradigm in-stead and minimise I/O strain (and some memory costs) on the system, leveraging locality of reference by running pattern generation shaders before we execute light transport simulation by path sampling, “compressing” any bvh structure as needed, and as such also limiting duplication of source data.
The difference with reyes is that instead of baking colors into the geometry like in Reyes, manuka bakes surface closures. This means that light transport is still calculated with path tracing, but all texture lookups etc. are done up-front and baked into the geometry.The main drawback with this method is that geometry has to be tessellated to its highest, stable topology before shading can be evaluated properly. As such, the high cost to first pixel. Even a basic 4 vertices square becomes a much more complex model with this approach.

Manuka use the RenderMan Shading Language (rsl) for programmable shading [Pixar Animation Studios 2015], but we do not invoke rsl shaders when intersecting a ray with a surface (often called shade-on-hit). Instead, we pre-tessellate and pre-shade all the input geometry in the front end of the renderer.
This way, we can efficiently order shading computations to sup-port near-optimal texture locality, vectorisation, and parallelism. This system avoids repeated evaluation of shaders at the same surface point, and presents a minimal amount of memory to be accessed during light transport time. An added benefit is that the acceleration structure for ray tracing (abounding volume hierarchy, bvh) is built once on the final tessellated geometry, which allows us to ray trace more efficiently than multi-level bvhs and avoids costly caching of on-demand tessellated micropolygons and the associated scheduling issues.For the shading reasons above, in terms of AOVs, the studio approach is to succeed at combining complex shading with ray paths in the render rather than pass a multi-pass render to compositing.
For the Spectral Rendering component. The light transport stage is fully spectral, using a continuously sampled wavelength which is traced with each path and used to apply the spectral camera sensitivity of the sensor. This allows for faithfully support any degree of observer metamerism as the camera footage they are intended to match as well as complex materials which require wavelength dependent phenomena such as diffraction, dispersion, interference, iridescence, or chromatic extinction and Rayleigh scattering in participating media.
As opposed to the original reyes paper, we use bilinear interpolation of these bsdf inputs later when evaluating bsdfs per pathv ertex during light transport4. This improves temporal stability of geometry which moves very slowly with respect to the pixel raster
In terms of the pipeline, everything rendered at Weta was already completely interwoven with their deep data pipeline. Manuka very much was written with deep data in mind. Here, Manuka not so much extends the deep capabilities, rather it fully matches the already extremely complex and powerful setup Weta Digital already enjoy with RenderMan. For example, an ape in a scene can be selected, its ID is available and a NUKE artist can then paint in 3D say a hand and part of the way up the neutral posed ape.
We called our system Manuka, as a respectful nod to reyes: we had heard a story froma former ILM employee about how reyes got its name from how fond the early Pixar people were of their lunches at Point Reyes, and decided to name our system after our surrounding natural environment, too. Manuka is a kind of tea tree very common in New Zealand which has very many very small leaves, in analogy to micropolygons ina tree structure for ray tracing. It also happens to be the case that Weta Digital’s main site is on Manuka Street.


