



BREAKING NEWS
LATEST POSTS
-
Black Forest Labs released FLUX.1 Kontext
https://replicate.com/blog/flux-kontext
https://replicate.com/black-forest-labs/flux-kontext-pro
There are three models, two are available now, and a third open-weight version is coming soon:
- FLUX.1 Kontext [pro]: State-of-the-art performance for image editing. High-quality outputs, great prompt following, and consistent results.
- FLUX.1 Kontext [max]: A premium model that brings maximum performance, improved prompt adherence, and high-quality typography generation without compromise on speed.
- Coming soon: FLUX.1 Kontext [dev]: An open-weight, guidance-distilled version of Kontext.
We’re so excited with what Kontext can do, we’ve created a collection of models on Replicate to give you ideas:
- Multi-image kontext: Combine two images into one.
- Portrait series: Generate a series of portraits from a single image
- Change haircut: Change a person’s hair style and color
- Iconic locations: Put yourself in front of famous landmarks
- Professional headshot: Generate a professional headshot from any image

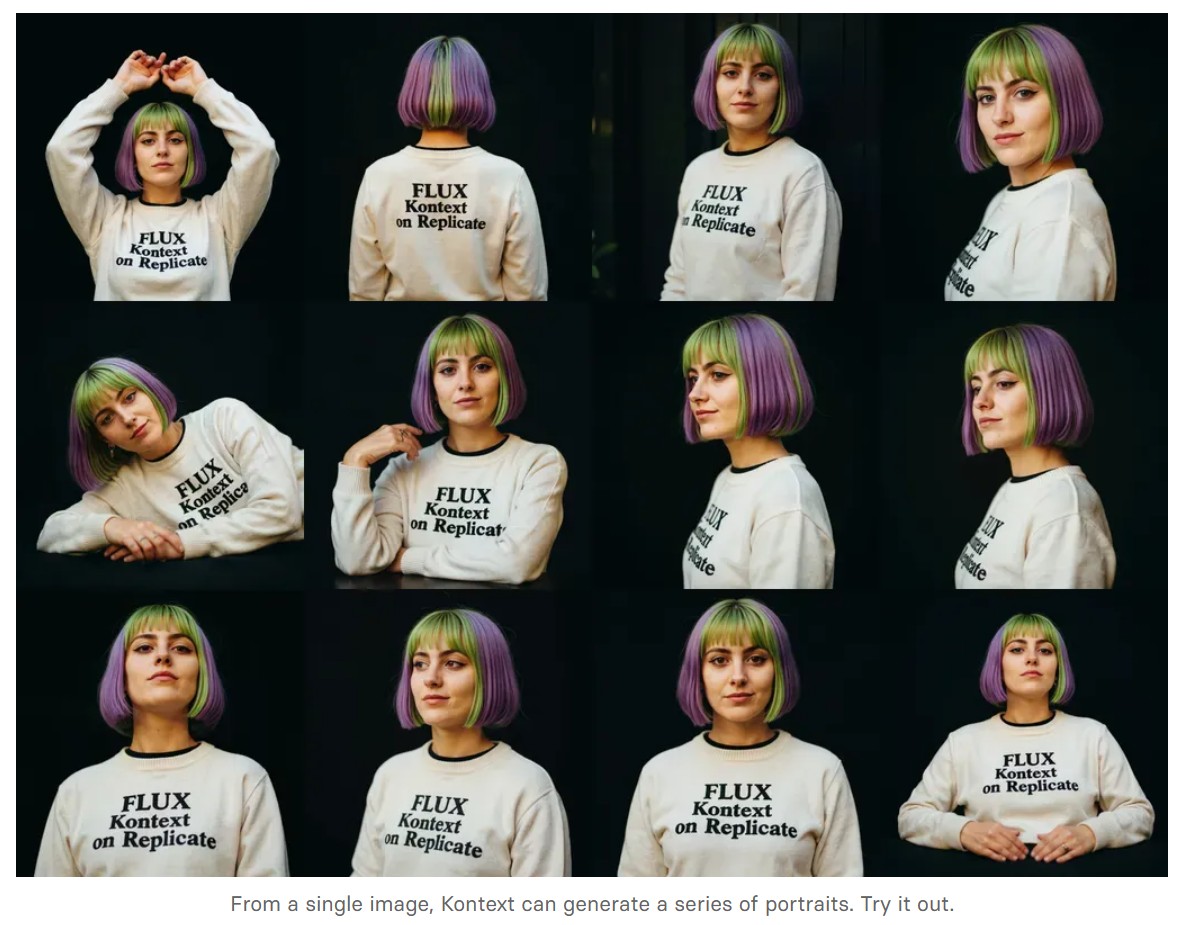
-
AI Models – A walkthrough by Andreas Horn
the 8 most important model types and what they’re actually built to do: ⬇️
1. 𝗟𝗟𝗠 – 𝗟𝗮𝗿𝗴𝗲 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹
→ Your ChatGPT-style model.
Handles text, predicts the next token, and powers 90% of GenAI hype.
🛠 Use case: content, code, convos.
2. 𝗟𝗖𝗠 – 𝗟𝗮𝘁𝗲𝗻𝘁 𝗖𝗼𝗻𝘀𝗶𝘀𝘁𝗲𝗻𝗰𝘆 𝗠𝗼𝗱𝗲𝗹
→ Lightweight, diffusion-style models.
Fast, quantized, and efficient — perfect for real-time or edge deployment.
🛠 Use case: image generation, optimized inference.
3. 𝗟𝗔𝗠 – 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗔𝗰𝘁𝗶𝗼𝗻 𝗠𝗼𝗱𝗲𝗹
→ Where LLM meets planning.
Adds memory, task breakdown, and intent recognition.
🛠 Use case: AI agents, tool use, step-by-step execution.
4. 𝗠𝗼𝗘 – 𝗠𝗶𝘅𝘁𝘂𝗿𝗲 𝗼𝗳 𝗘𝘅𝗽𝗲𝗿𝘁𝘀
→ One model, many minds.
Routes input to the right “expert” model slice — dynamic, scalable, efficient.
🛠 Use case: high-performance model serving at low compute cost.
5. 𝗩𝗟𝗠 – 𝗩𝗶𝘀𝗶𝗼𝗻 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹
→ Multimodal beast.
Combines image + text understanding via shared embeddings.
🛠 Use case: Gemini, GPT-4o, search, robotics, assistive tech.
6. 𝗦𝗟𝗠 – 𝗦𝗺𝗮𝗹𝗹 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹
→ Tiny but mighty.
Designed for edge use, fast inference, low latency, efficient memory.
🛠 Use case: on-device AI, chatbots, privacy-first GenAI.
7. 𝗠𝗟𝗠 – 𝗠𝗮𝘀𝗸𝗲𝗱 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹
→ The OG foundation model.
Predicts masked tokens using bidirectional context.
🛠 Use case: search, classification, embeddings, pretraining.
8. 𝗦𝗔𝗠 – 𝗦𝗲𝗴𝗺𝗲𝗻𝘁 𝗔𝗻𝘆𝘁𝗵𝗶𝗻𝗴 𝗠𝗼𝗱𝗲𝗹
→ Vision model for pixel-level understanding.
Highlights, segments, and understands *everything* in an image.
🛠 Use case: medical imaging, AR, robotics, visual agents.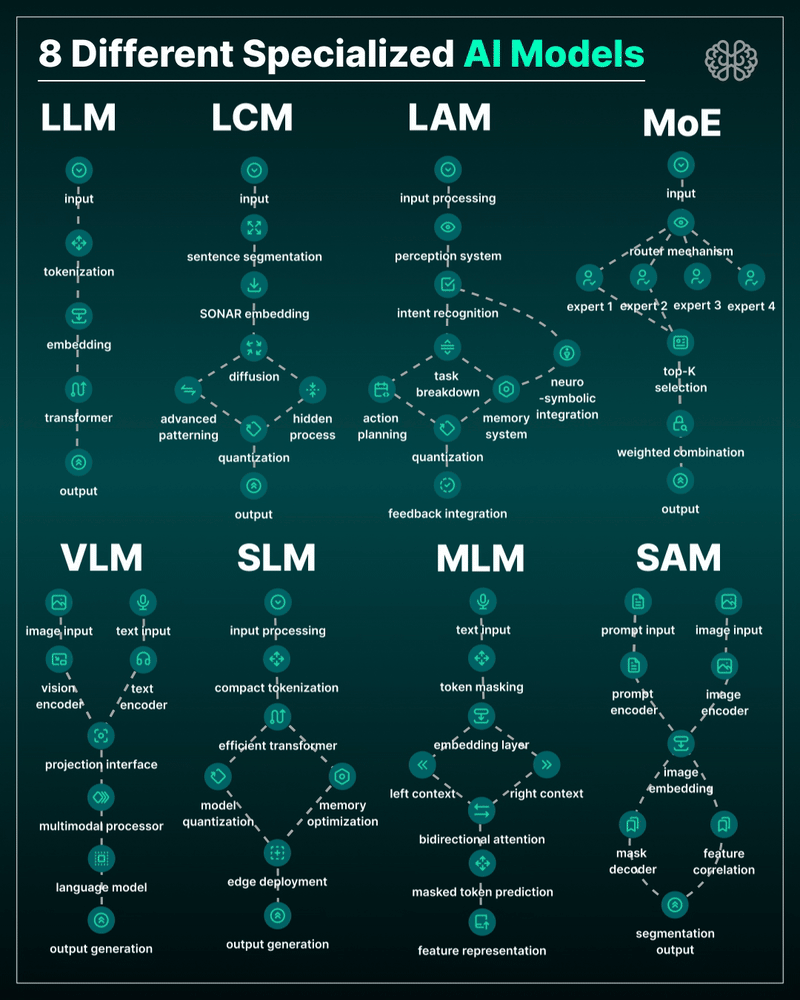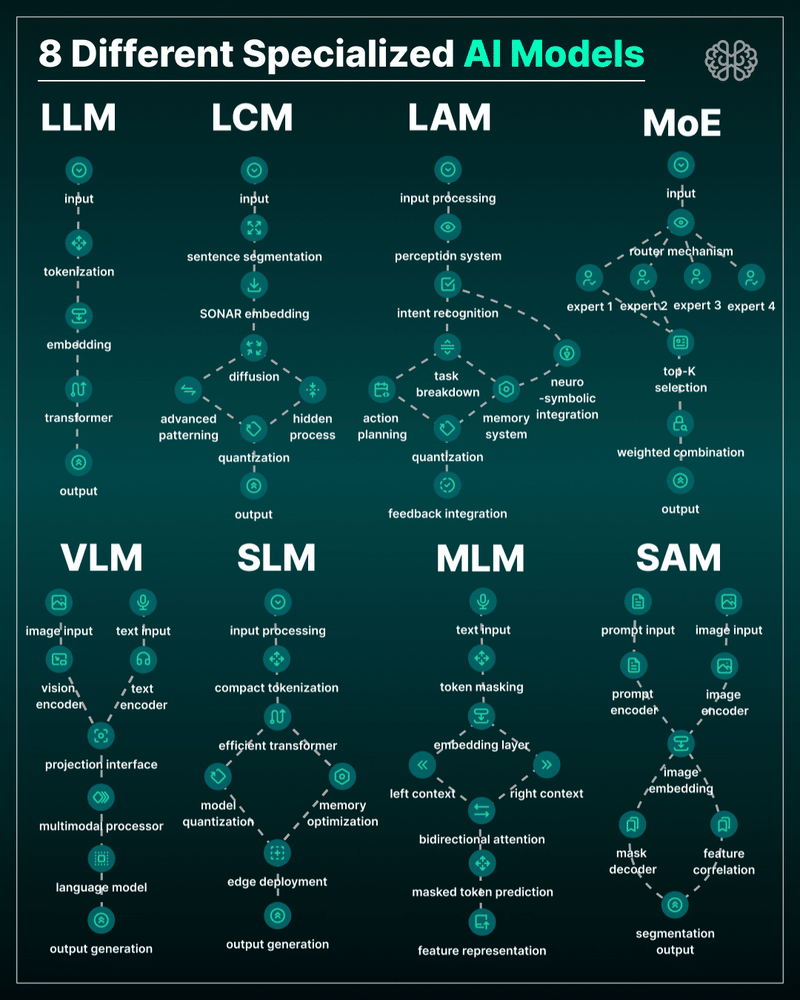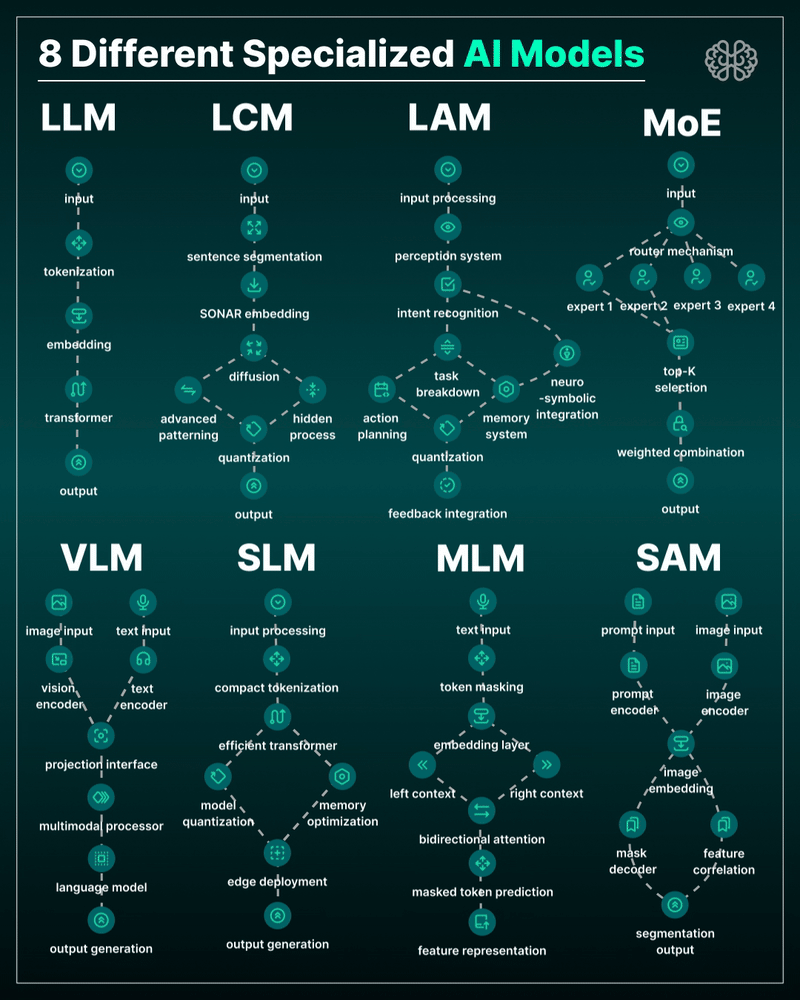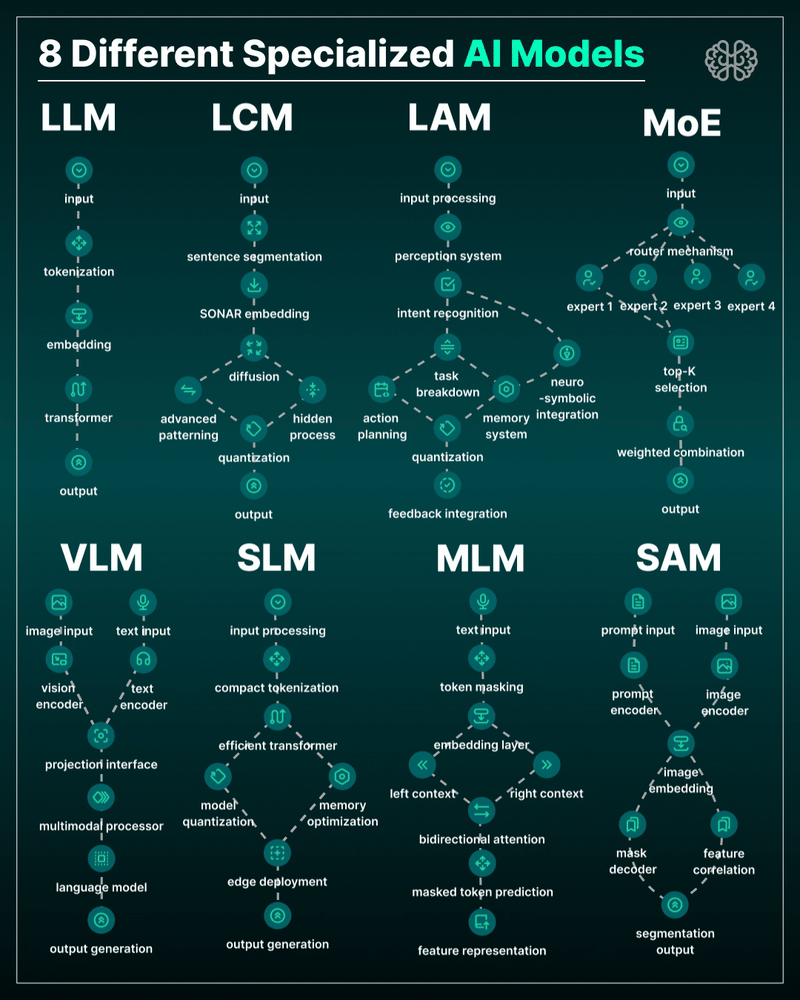
-
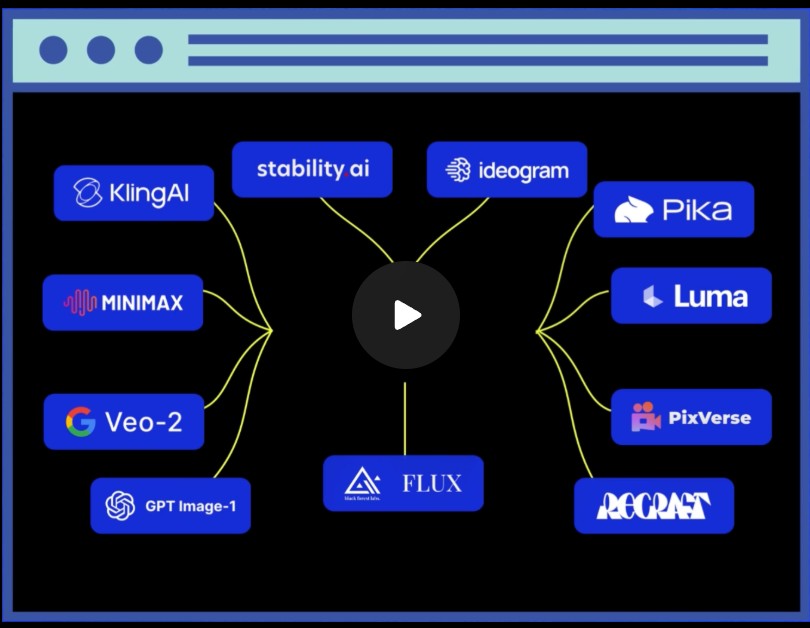
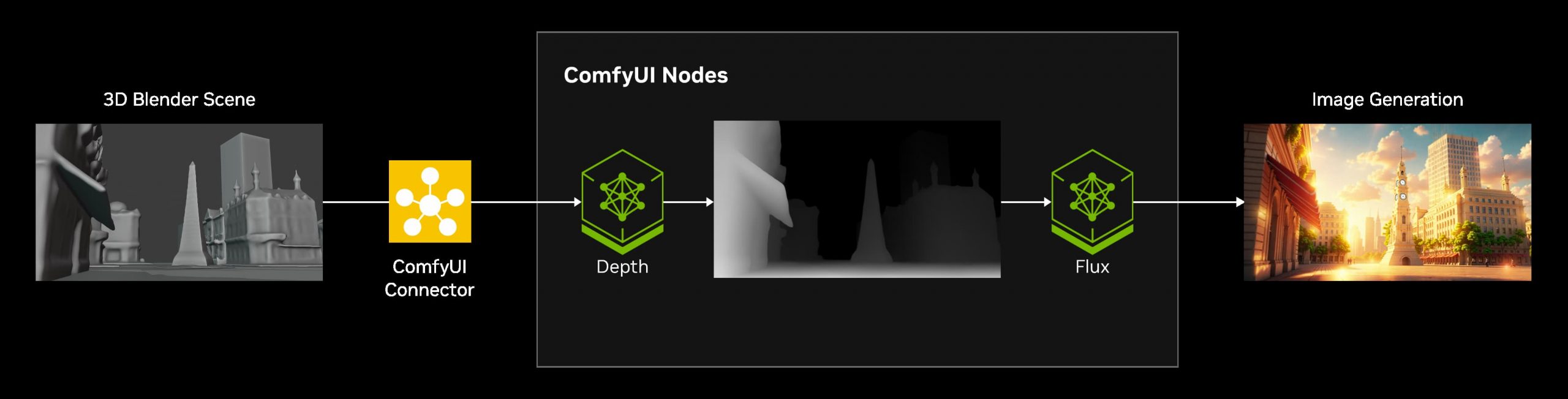
Introducting ComfyUI Native API Nodes
https://blog.comfy.org/p/comfyui-native-api-nodes
Models Supported
- Black Forest Labs Flux 1.1[pro] Ultra, Flux .1[pro]
- Kling 2.0, 1.6, 1.5 & Various Effects
- Luma Photon, Ray2, Ray1.6
- MiniMax Text-to-Video, Image-to-Video
- PixVerse V4 & Effects
- Recraft V3, V2 & Various Tools
- Stability AI Stable Image Ultra, Stable Diffusion 3.5 Large
- Google Veo2
- Ideogram V3, V2, V1
- OpenAI GPT4o image
- Pika 2.2
-
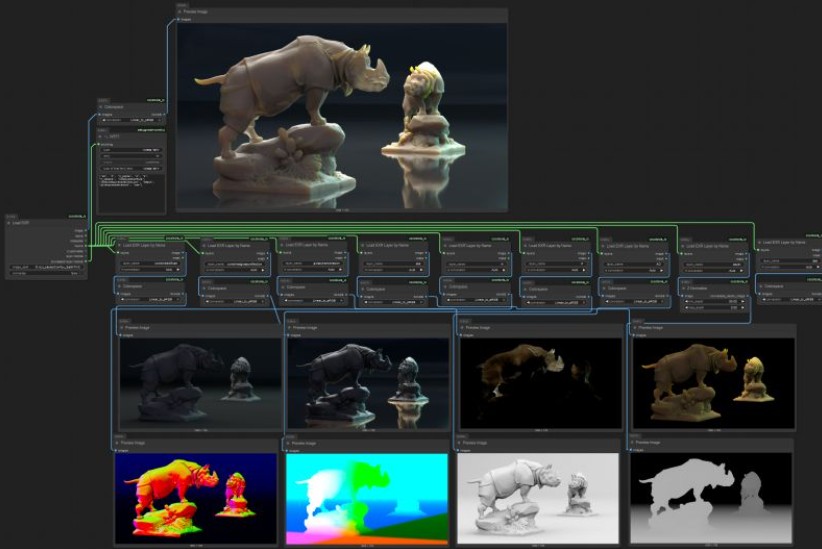
ComfyUI-CoCoTools_IO – A set of nodes focused on advanced image I/O operations, particularly for EXR file handling
https://github.com/Conor-Collins/ComfyUI-CoCoTools_IO
Features
- Advanced EXR image input with multilayer support
- EXR layer extraction and manipulation
- High-quality image saving with format-specific options
- Standard image format loading with bit depth awareness
Current Nodes
Image I/O
- Image Loader: Load standard image formats (PNG, JPG, WebP, etc.) with proper bit depth handling
- Load EXR: Comprehensive EXR file loading with support for multiple layers, channels, and cryptomatte data
- Load EXR Layer by Name: Extract specific layers from EXR files (similar to Nuke’s Shuffle node)
- Cryptomatte Layer: Specialized handling for cryptomatte layers in EXR files
- Image Saver: Save images in various formats with format-specific options (bit depth, compression, etc.)
Image Processing
- Colorspace: Convert between sRGB and Linear colorspaces
- Z Normalize: Normalize depth maps and other single-channel data
-
Claudio Tosti – La vita pittoresca dell’abate Uggeri
https://vivariumnovum.it/saggistica/varia/la-vita-pittoresca-dellabate-uggeri
Book author: Claudio Tosti
Title: La vita pittoresca dell’abate Uggeri – Vol. I – La Giornata Tuscolana- ISBN: 978-8895611990
Video made with Pixverse.ai and DaVinci Resolve










FEATURED POSTS


-
Photorealistic AI Pocket Guide

Prompt Example:
“editorial cinematic, Ibiza aesthetic, a man wearing a brown t-shirt, hero-view, fashion photography, medium-shot, detailed, Sony A7 IV, 100mm, muted colors –ar 21:9 –c 10 –v 5.2 –style raw”
-
Tencent Hunyuan3D 2.1 goes Open Source and adds MV (Multi-view) and MV Mini
https://huggingface.co/tencent/Hunyuan3D-2mv
https://huggingface.co/tencent/Hunyuan3D-2mini
https://github.com/Tencent/Hunyuan3D-2
Tencent just made Hunyuan3D 2.1 open-source.
This is the first fully open-source, production-ready PBR 3D generative model with cinema-grade quality.
https://github.com/Tencent-Hunyuan/Hunyuan3D-2.1
What makes it special?
• Advanced PBR material synthesis brings realistic materials like leather, bronze, and more to life with stunning light interactions.
• Complete access to model weights, training/inference code, data pipelines.
• Optimized to run on accessible hardware.
• Built for real-world applications with professional-grade output quality.
They’re making it accessible to everyone:
• Complete open-source ecosystem with full documentation.
• Ready-to-use model weights and training infrastructure.
• Live demo available for instant testing.
• Comprehensive GitHub repository with implementation details.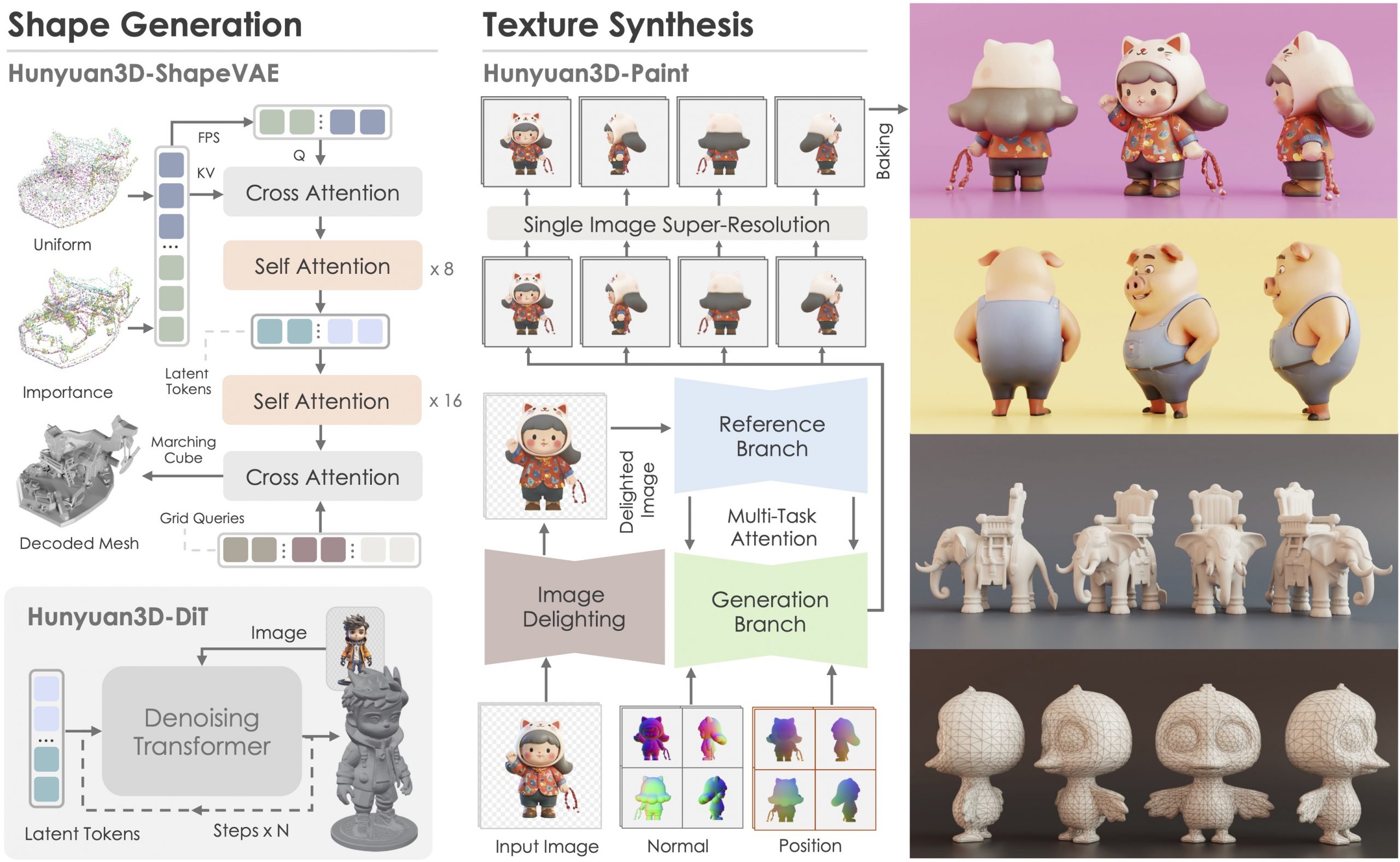

-
Embedding frame ranges into Quicktime movies with FFmpeg
QuickTime (.mov) files are fundamentally time-based, not frame-based, and so don’t have a built-in, uniform “first frame/last frame” field you can set as numeric frame IDs. Instead, tools like Shotgun Create rely on the timecode track and the movie’s duration to infer frame numbers. If you want Shotgun to pick up a non-default frame range (e.g. start at 1001, end at 1064), you must bake in an SMPTE timecode that corresponds to your desired start frame, and ensure the movie’s duration matches your clip length.
How Shotgun Reads Frame Ranges
- Default start frame is 1. If no timecode metadata is present, Shotgun assumes the movie begins at frame 1.
- Timecode ⇒ frame number. Shotgun Create “honors the timecodes of media sources,” mapping the embedded TC to frame IDs. For example, a 24 fps QuickTime tagged with a start timecode of 00:00:41:17 will be interpreted as beginning on frame 1001 (1001 ÷ 24 fps ≈ 41.71 s).
Embedding a Start Timecode
QuickTime uses a
tmcd(timecode) track. You can bake in an SMPTE track via FFmpeg’s-timecodeflag or via Compressor/encoder settings:- Compute your start TC.
- Desired start frame = 1001
- Frame 1001 at 24 fps ⇒ 1001 ÷ 24 ≈ 41.708 s ⇒ TC 00:00:41:17
- FFmpeg example:
ffmpeg -i input.mov \ -c copy \ -timecode 00:00:41:17 \ output.movThis adds a timecode track beginning at 00:00:41:17, which Shotgun maps to frame 1001.
Ensuring the Correct End Frame
Shotgun infers the last frame from the movie’s duration. To end on frame 1064:
- Frame count = 1064 – 1001 + 1 = 64 frames
- Duration = 64 ÷ 24 fps ≈ 2.667 s
FFmpeg trim example:
ffmpeg -i input.mov \ -c copy \ -timecode 00:00:41:17 \ -t 00:00:02.667 \ output_trimmed.movThis results in a 64-frame clip (1001→1064) at 24 fps.




