Given sparse-view videos, Diffuman4D (1) generates 4D-consistent multi-view videos conditioned on these inputs, and (2) reconstructs a high-fidelity 4DGS model of the human performance using both the input and the generated videos.
Truly Infinite Videos This isn’t a gimmick. You can generate incredibly long videos without frying your VRAM. Perfect for podcasts, presentations, or full-on virtual influencers.
More Than Just Lips This is the best part. It doesn’t just sync the mouth; it generates realistic head movements, body posture, and facial expressions that match the audio’s emotion. It makes characters feel alive.
Keeps Everything Consistent It preserves the character’s identity, the background, and even camera movements from your original video, so everything looks seamless.
Completely Open Source & Ready for Business The code, the weights, and the paper are all out there for you to use. Best of all, it’s released under an Apache 2.0 license, which means you are free to use what you create for commercial projects!
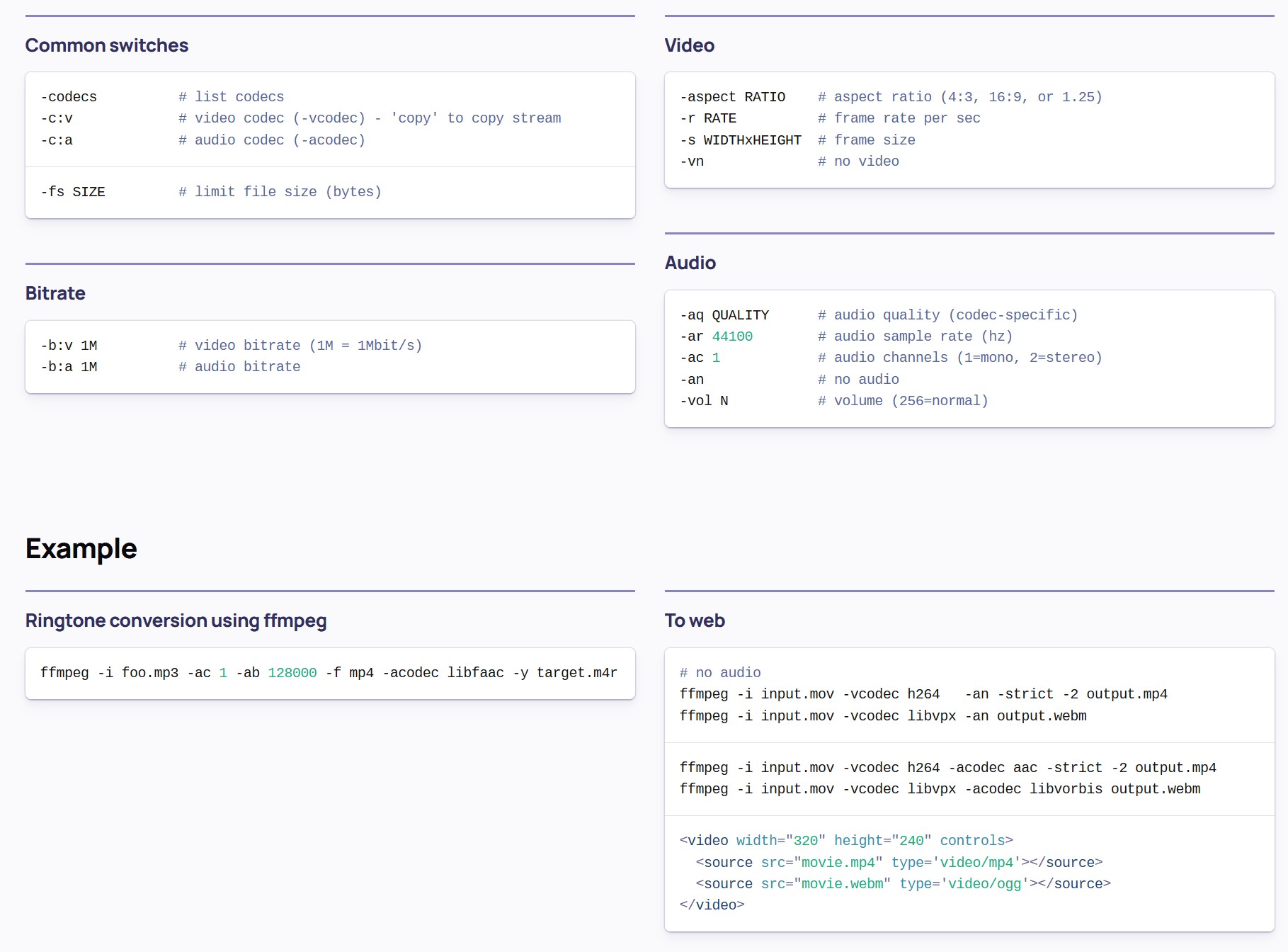
# extract one frame at the end of a video ffmpeg -sseof -0.1 -i intro_1.mp4 -frames:v 1 -q:v 1 intro_end.jpg
-sseof -0.1: This option tells FFmpeg to seek to 0.1 seconds before the end of the file. This approach is often more reliable for extracting the last frame, especially if the video’s duration isn’t an exact multiple of the frame interval. Super User -frames:v 1: Extracts a single frame. -q:v 1: Sets the quality of the output image; 1 is the highest quality.
# extract one frame at the beginning of a video ffmpeg -i speaking_4.mp4 -frames:v 1 speaking_beginning.jpg
# check video length ffmpeg -i C:\myvideo.mp4 -f null –
# Convert mov/mp4 to animated gifEdit ffmpeg -i input.mp4 -pix_fmt rgb24 output.gif Other useful ffmpeg commandsEdit
MiniMax-Remover is a fast and effective video object remover based on minimax optimization. It operates in two stages: the first stage trains a remover using a simplified DiT architecture, while the second stage distills a robust remover with CFG removal and fewer inference steps.
Bella works in spectral space, allowing effects such as BSDF wavelength dependency, diffraction, or atmosphere to be modeled far more accurately than in color space.