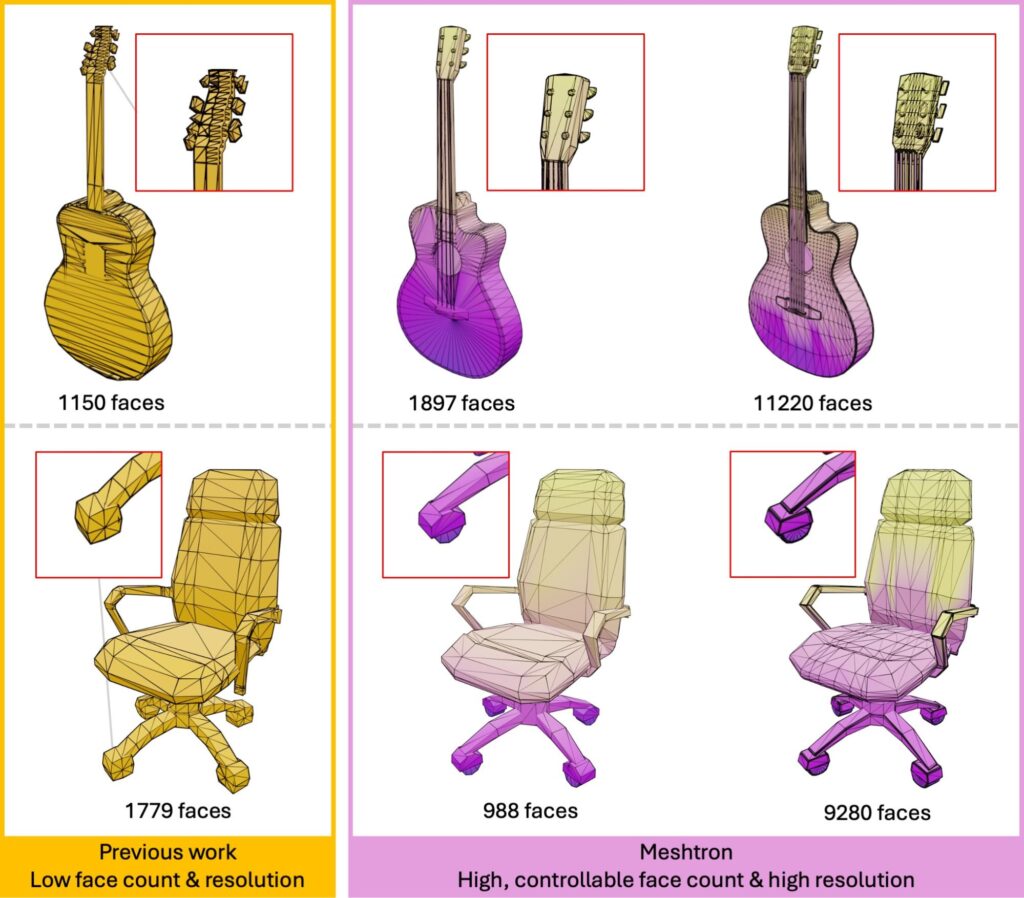
Meshtron provides a simple and scalable, data-driven solution for generating intricate, artist-like meshes of up to 64K faces at 1024-level coordinate resolution. This is over an order of magnitude higher face count and 8x higher coordinate resolution compared to existing methods.
A model that can generate the next frame of a 3D scene based on the previous frame(s) and user input, trained on video data, and running in real-time.
World models enable AI systems to simulate and reason about their environments, pushing forward autonomous decision-making and real-world problem-solving.
The key insight is that by training on video data, these models learn not just how to generate images, but also:
the physics of our world (objects fall down, water flows, etc)
how objects look from different angles (that chair should look the same as you walk around it)
how things move and interact (a ball bouncing off a wall, a character walking on sand)
basic spatial understanding (you can’t walk through walls)
Some companies, like World Labs, are taking a hybrid approach: using World Models to generate static 3D representations that can then be rendered using traditional 3D engines (in this case, Gaussian Splatting). This gives you the best of both worlds: the creative power of AI generation with the multiview consistency and performance of traditional rendering.
His insight (and how it can change yours): During World War II, the U.S. wanted to add reinforcement armor to specific areas of its planes. Analysts examined returning bombers, plotted the bullet holes and damage on them (as in the image below), and came to the conclusion that adding armor to the tail, body, and wings would improve their odds of survival.
But a young statistician named Abraham Wald noted that this would be a tragic mistake. By only plotting data on the planes that returned, they were systematically omitting the data on a critical, informative subset: The planes that were damaged and unable to return.