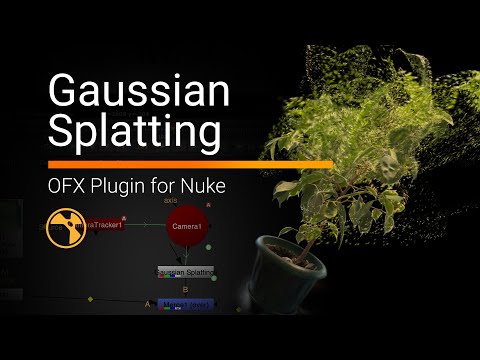
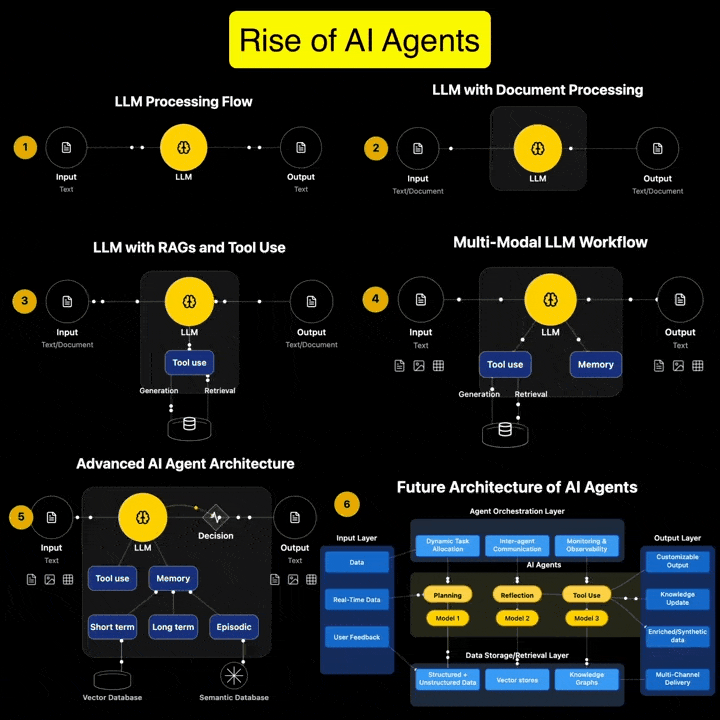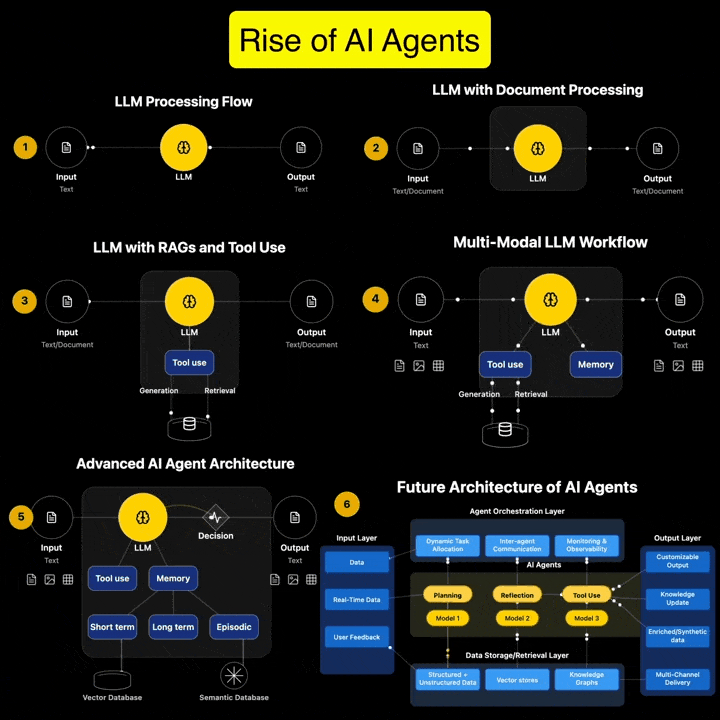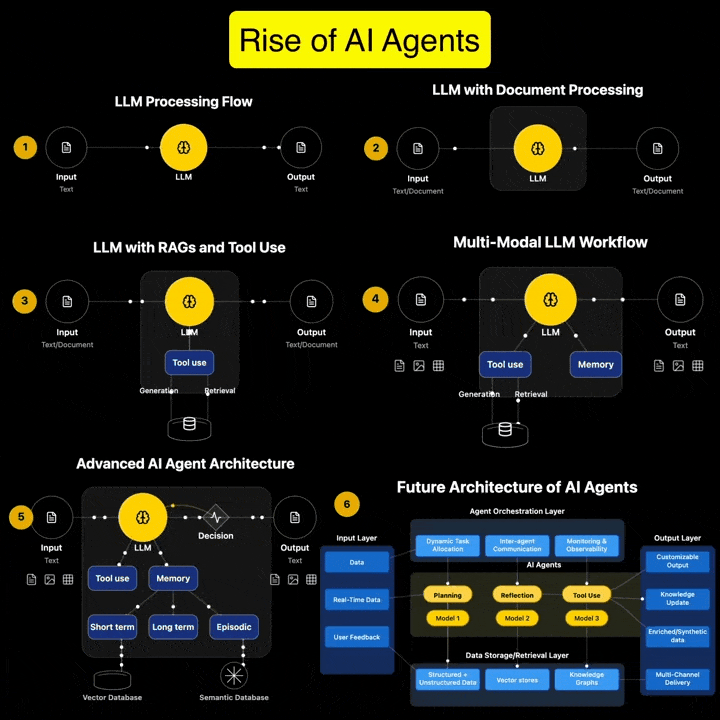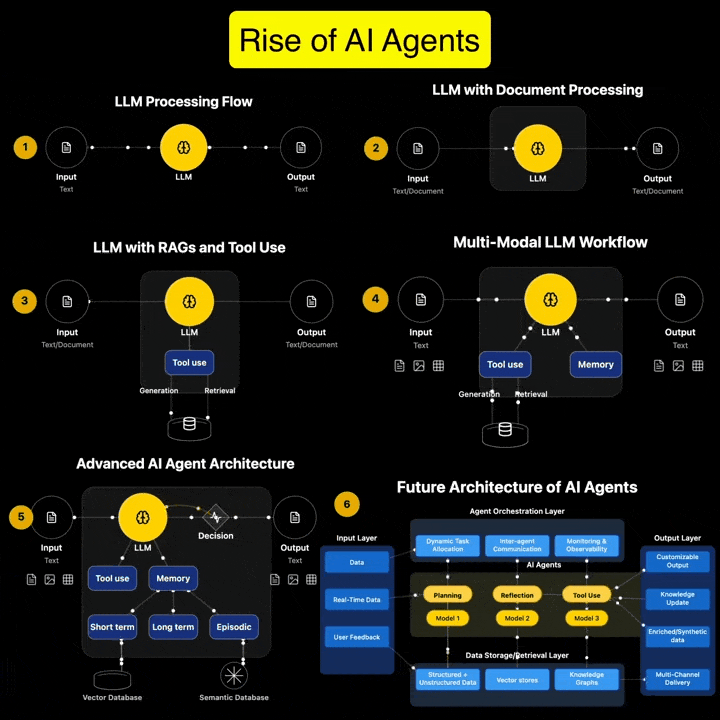
“There are many good reasons to be concerned about the rise of generative AI(…). Unfortunately, there are also many good reasons to be concerned about copyright’s growing prevalence in the policy discourse around AI’s regulation. Insisting that copyright protects an exclusive right to use materials for text and data mining practices (whether for informational analysis or machine learning to train generative AI models) is likely to do more harm than good. As many others have explained, imposing copyright constraints will certainly limit competition in the AI industry, creating cost-prohibitive barriers to quality data and ensuring that only the most powerful players have the means to build the best AI tools (provoking all of the usual monopoly concerns that accompany this kind of market reality but arguably on a greater scale than ever before). It will not, however, prevent the continued development and widespread use of generative AI.”
…
“(…) As Michal Shur-Ofry has explained, the technical traits of generative AI already mean that its outputs will tend towards the dominant, likely reflecting ‘a relatively narrow, mainstream view, prioritizing the popular and conventional over diverse contents and narratives.’ Perhaps, then, if the political goal is to push for equality, participation, and representation in the AI age, critics’ demands should focus not on exclusivity but inclusivity. If we want to encourage the development of ethical and responsible AI, maybe we should be asking what kind of material and training data must be included in the inputs and outputs of AI to advance that goal. Certainly, relying on copyright and the market to dictate what is in and what is out is unlikely to advance a public interest or equality-oriented agenda.”
…
“If copyright is not the solution, however, it might reasonably be asked: what is? The first step to answering that question—to producing a purposively sound prescription and evidence-based prognosis, is to correctly diagnose the problem. If, as I have argued, the problem is not that AI models are being trained on copyright works without their owners’ consent, then requiring copyright owners’ consent and/or compensation for the use of their work in AI-training datasets is not the appropriate solution. (…)If the only real copyright problem is that the outputs of generative AI may be substantially similar to specific human-authored and copyright-protected works, then copyright law as we know it already provides the solution.”
Narrative voice via Artlistai, News Reporter PlayAI, All other voices are V2V in Elevenlabs. Powered by (in order of amount) ‘HailuoAI’, ‘KlingAI’ and of course some of our special source. Performance capture by ‘Runway’s Act-One’. Edited and color graded in ‘DaVinci Resolve’. Composited with ‘After Effects’.
In this film, the ‘Newton’s Cradle’ isn’t just a symbolic object—it represents the fragile balance between control and freedom in a world where time itself is being manipulated. The oscillation of the cradle reflects the constant push and pull of power in this dystopian society. By the end of the film, we discover that this seemingly innocuous object holds the potential to disrupt the system, offering a glimmer of hope that time can be reset and balance restored.
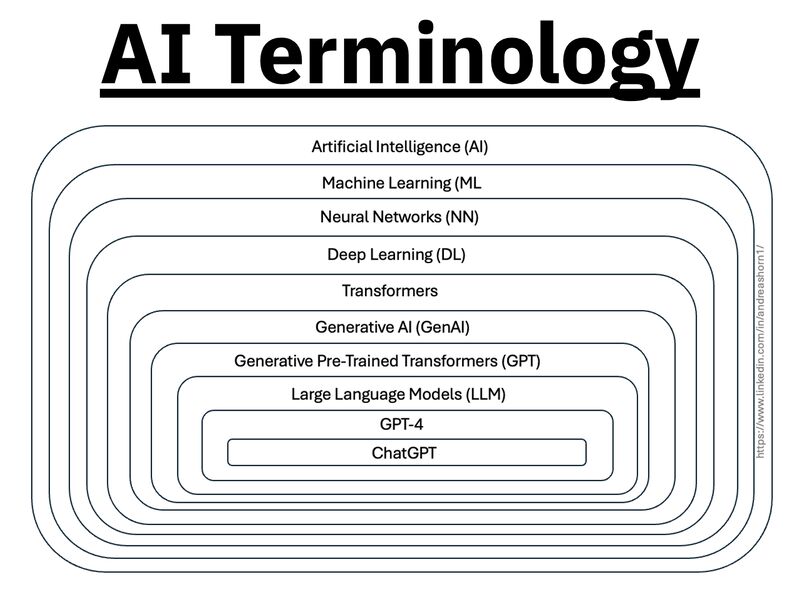
1️⃣ 𝗔𝗿𝘁𝗶𝗳𝗶𝗰𝗶𝗮𝗹 𝗜𝗻𝘁𝗲𝗹𝗹𝗶𝗴𝗲𝗻𝗰𝗲 (𝗔𝗜) – The broadest category, covering automation, reasoning, and decision-making. Early AI was rule-based, but today, it’s mainly data-driven. 2️⃣ 𝗠𝗮𝗰𝗵𝗶𝗻𝗲 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 (𝗠𝗟) – AI that learns patterns from data without explicit programming. Includes decision trees, clustering, and regression models. 3️⃣ 𝗡𝗲𝘂𝗿𝗮𝗹 𝗡𝗲𝘁𝘄𝗼𝗿𝗸𝘀 (𝗡𝗡) – A subset of ML, inspired by the human brain, designed for pattern recognition and feature extraction. 4️⃣ 𝗗𝗲𝗲𝗽 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 (𝗗𝗟) – Multi-layered neural networks that drives a lot of modern AI advancements, for example enabling image recognition, speech processing, and more. 5️⃣ 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗲𝗿𝘀 – A revolutionary deep learning architecture introduced by Google in 2017 that allows models to understand and generate language efficiently. 6️⃣ 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝘃𝗲 𝗔𝗜 (𝗚𝗲𝗻𝗔𝗜) – AI that doesn’t just analyze data—it creates. From text and images to music and code, this layer powers today’s most advanced AI models. 7️⃣ 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝘃𝗲 𝗣𝗿𝗲-𝗧𝗿𝗮𝗶𝗻𝗲𝗱 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗲𝗿𝘀 (𝗚𝗣𝗧) – A specific subset of Generative AI that uses transformers for text generation. 8️⃣ 𝗟𝗮𝗿𝗴𝗲 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹𝘀 (𝗟𝗟𝗠) – Massive AI models trained on extensive datasets to understand and generate human-like language. 9️⃣ 𝗚𝗣𝗧-4 – One of the most advanced LLMs, built on transformer architecture, trained on vast datasets to generate human-like responses. 🔟 𝗖𝗵𝗮𝘁𝗚𝗣𝗧 – A specific application of GPT-4, optimized for conversational AI and interactive use.
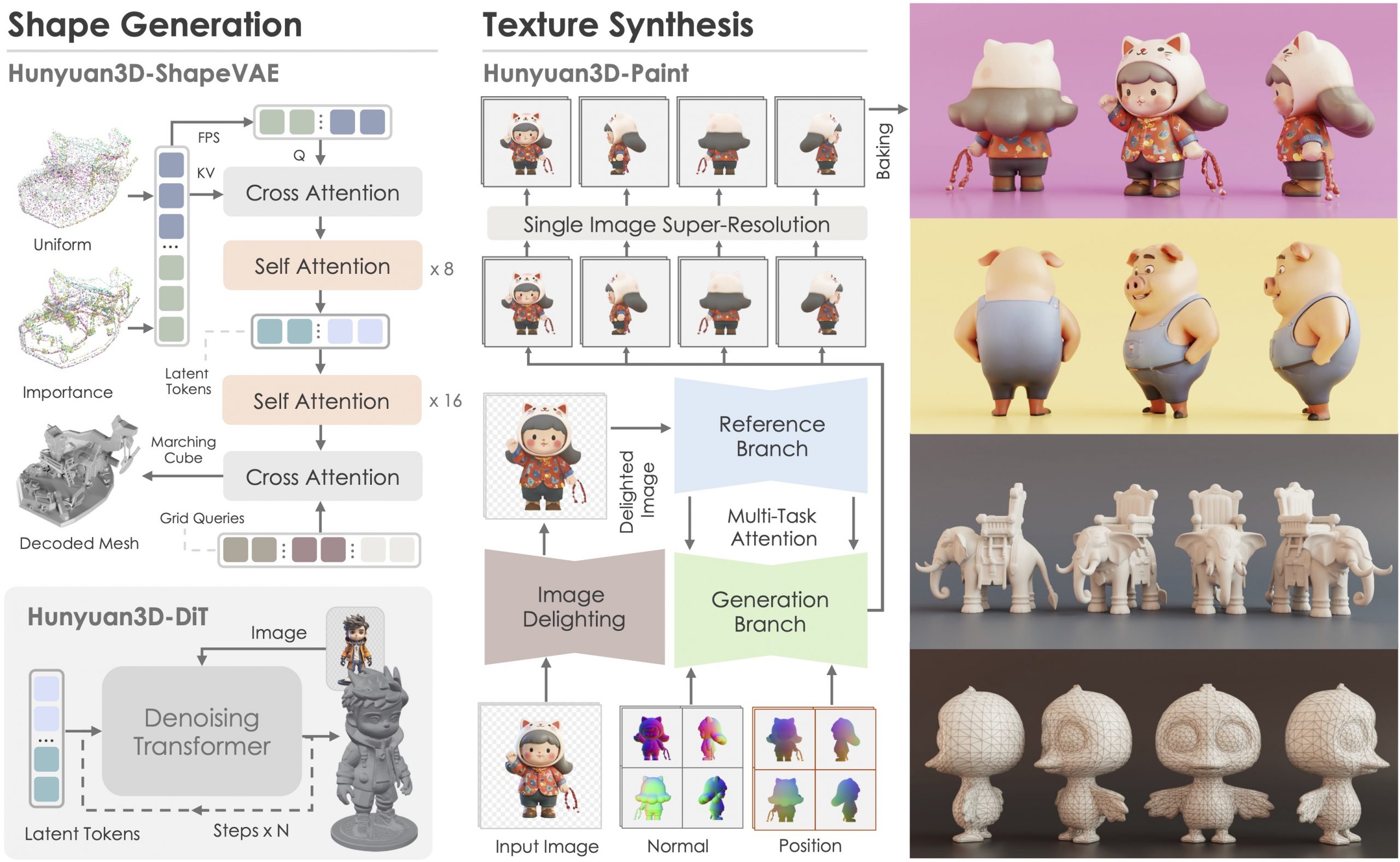
Tencent just made Hunyuan3D 2.1 open-source. This is the first fully open-source, production-ready PBR 3D generative model with cinema-grade quality. https://github.com/Tencent-Hunyuan/Hunyuan3D-2.1
What makes it special? • Advanced PBR material synthesis brings realistic materials like leather, bronze, and more to life with stunning light interactions. • Complete access to model weights, training/inference code, data pipelines. • Optimized to run on accessible hardware. • Built for real-world applications with professional-grade output quality.
They’re making it accessible to everyone: • Complete open-source ecosystem with full documentation. • Ready-to-use model weights and training infrastructure. • Live demo available for instant testing. • Comprehensive GitHub repository with implementation details.