Benchmarks don’t capture real-world complexity like latency, domain-specific tasks, or edge cases. Enterprises often need more than raw performance, also needing reliability, ease of integration, and robust vendor support. Enterprise money will support the industries providing these services.
… it is also reasonable to assume that anything you put into the app or their website will be going to the Chinese government as well, so factor that in as well.
Tneration models can create high-quality images from input prompts. However, they struggle to support the consistent generation of identity-preserving requirements for storytelling.
Our approach 1Prompt1Story concatenates all prompts into a single input for T2I diffusion models, initially preserving character identities.
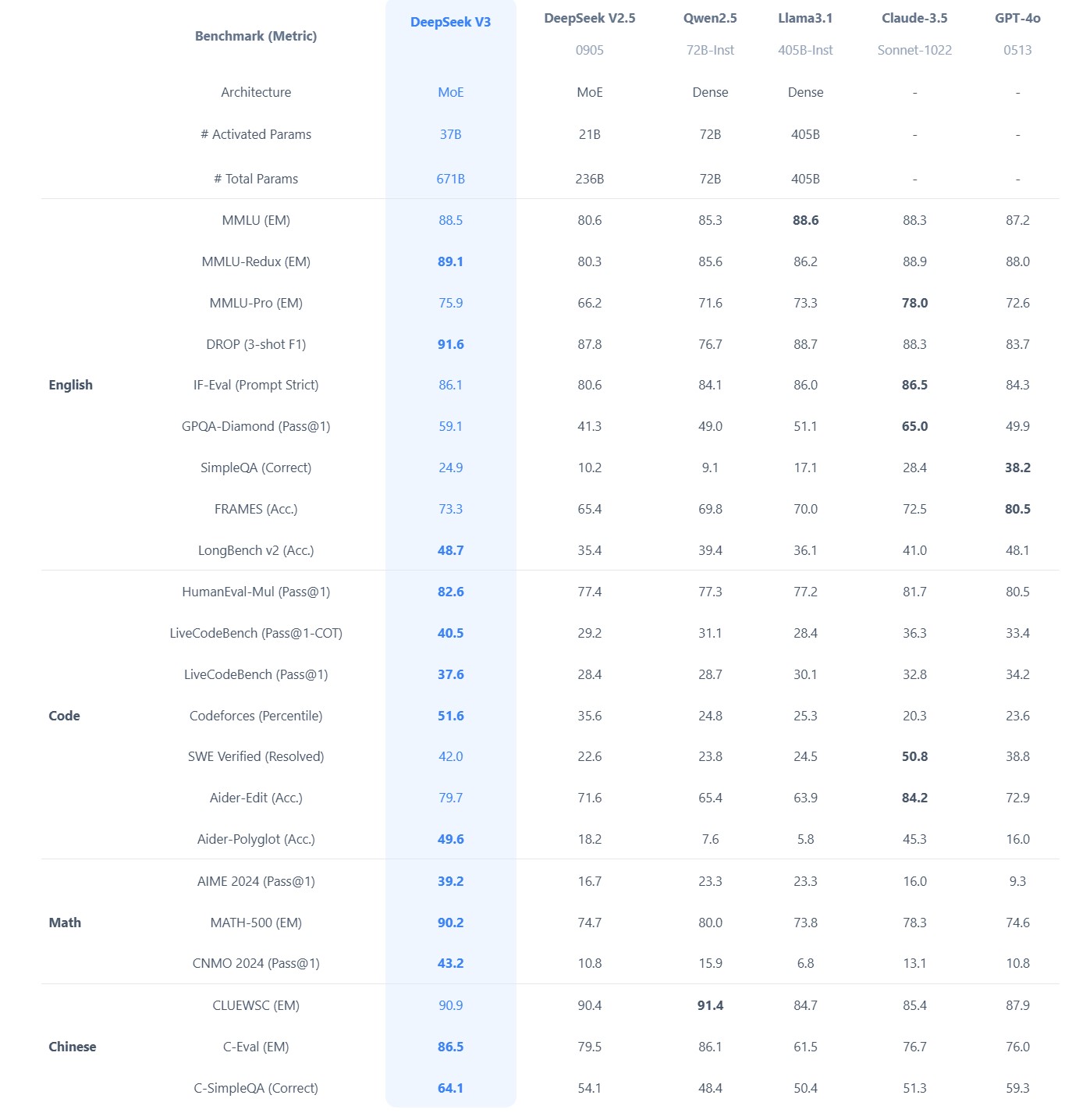
The Chinese AI lab DeepSeek recently released their new reasoning model R1, which is supposedly (a) better than the current best reasoning models (OpenAI’s o1- series), and (b) was trained on a GPU cluster a fraction the size of any of the big western AI labs.
DeepSeek uses a reinforcement learning approach, not a fine-tuning approach. There’s no need to generate a huge body of chain-of-thought data ahead of time, and there’s no need to run an expensive answer-checking model. Instead, the model generates its own chains-of-thought as it goes.
The secret behind their success? A bold move to train their models using FP8 (8-bit floating-point precision) instead of the standard FP32 (32-bit floating-point precision). … By using a clever system that applies high precision only when absolutely necessary, they achieved incredible efficiency without losing accuracy. … The impressive part? These multi-token predictions are about 85–90% accurate, meaning DeepSeek R1 can deliver high-quality answers at double the speed of its competitors.
a novel method for generating hyper-quality 4K textured mesh under only 30 seconds, providing 3D assets ready for commercial applications such as games, movies, and VR/AR.
“Simon Willison created a Datasette browser to explore WebVid-10M, one of the two datasets used to train the video generation model, and quickly learned that all 10.7 million video clips were scraped from Shutterstock, watermarks and all.”
“In addition to the Shutterstock clips, Meta also used 10 million video clips from this 100M video dataset from Microsoft Research Asia. It’s not mentioned on their GitHub, but if you dig into the paper, you learn that every clip came from over 3 million YouTube videos.”
“It’s become standard practice for technology companies working with AI to commercially use datasets and models collected and trained by non-commercial research entities like universities or non-profits.”
“Like with the artists, photographers, and other creators found in the 2.3 billion images that trained Stable Diffusion, I can’t help but wonder how the creators of those 3 million YouTube videos feel about Meta using their work to train their new model.”