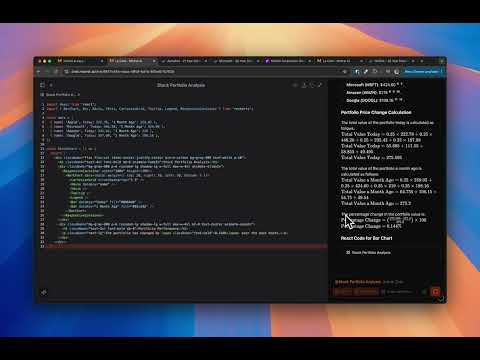
With it, you can develop, optimize, and deploy your applications on GPU-accelerated embedded systems, desktop workstations, enterprise data centers, cloud-based platforms, and supercomputers. The toolkit includes GPU-accelerated libraries, debugging and optimization tools, a C/C++ compiler, and a runtime library.
By inputting a single character image and template pose video, our method can generate vocal avatar videos featuring not only pose-accurate rendering but also realistic body shapes.
Given an input video and a simple user-provided text instruction describing the desired content, our method synthesizes dynamic objects or complex scene effects that naturally interact with the existing scene over time. The position, appearance, and motion of the new content are seamlessly integrated into the original footage while accounting for camera motion, occlusions, and interactions with other dynamic objects in the scene, resulting in a cohesive and realistic output video.
They propose an end-to-end multimodality-conditioned human video generation framework named OmniHuman, which can generate human videos based on a single human image and motion signals (e.g., audio only, video only, or a combination of audio and video). In OmniHuman, we introduce a multimodality motion conditioning mixed training strategy, allowing the model to benefit from data scaling up of mixed conditioning. This overcomes the issue that previous end-to-end approaches faced due to the scarcity of high-quality data. OmniHuman significantly outperforms existing methods, generating extremely realistic human videos based on weak signal inputs, especially audio. It supports image inputs of any aspect ratio, whether they are portraits, half-body, or full-body images, delivering more lifelike and high-quality results across various scenarios.
Depth of field is the range within which focusing is resolved in a photo.
Aperture has a huge affect on to the depth of field.
Changing the f-stops (f/#) of a lens will change aperture and as such the DOF.
f-stops are a just certain number which is telling you the size of the aperture. That’s how f-stop is related to aperture (and DOF).
If you increase f-stops, it will increase DOF, the area in focus (and decrease the aperture). On the other hand, decreasing the f-stop it will decrease DOF (and increase the aperture).
The red cone in the figure is an angular representation of the resolution of the system. Versus the dotted lines, which indicate the aperture coverage. Where the lines of the two cones intersect defines the total range of the depth of field.
This image explains why the longer the depth of field, the greater the range of clarity.
GaiaNet is a decentralized computing infrastructure that enables everyone to create, deploy, scale, and monetize their own AI agents that reflect their styles, values, knowledge, and expertise. It allows individuals and businesses to create AI agents. Each GaiaNet node provides
a web-based chatbot UI.
an OpenAI compatible API. See how to use a GaiaNet node as a drop-in OpenAI replacement in your favorite AI agent app.
About 576 megapixels for the entire field of view.
Consider a view in front of you that is 90 degrees by 90 degrees, like looking through an open window at a scene. The number of pixels would be:
90 degrees * 60 arc-minutes/degree * 1/0.3 * 90 * 60 * 1/0.3 = 324,000,000 pixels (324 megapixels).
At any one moment, you actually do not perceive that many pixels, but your eye moves around the scene to see all the detail you want. But the human eye really sees a larger field of view, close to 180 degrees. Let’s be conservative and use 120 degrees for the field of view. Then we would see:
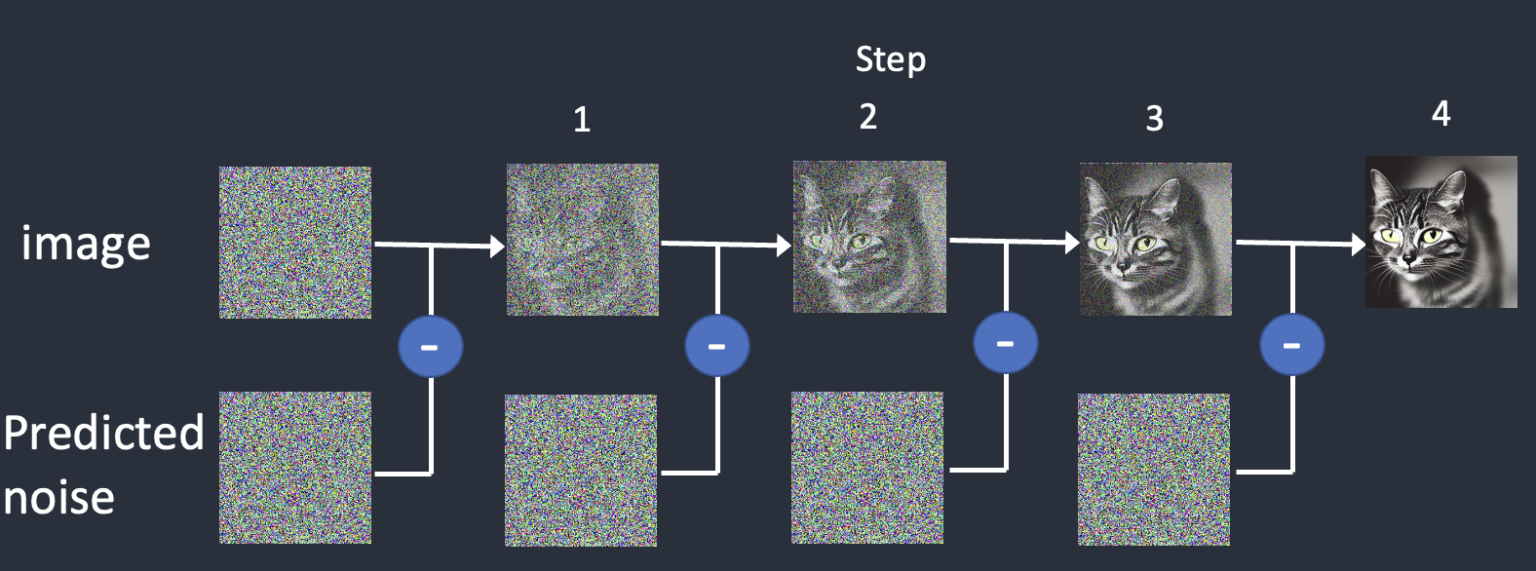
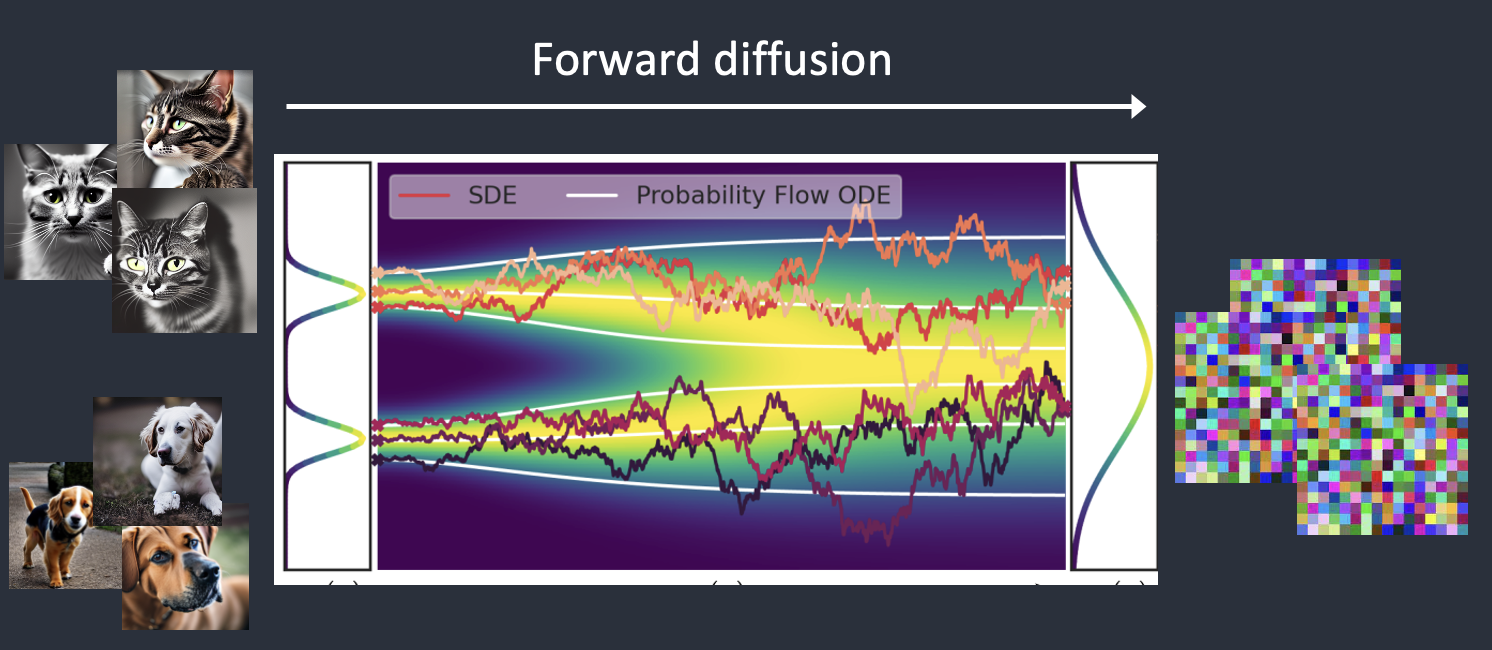
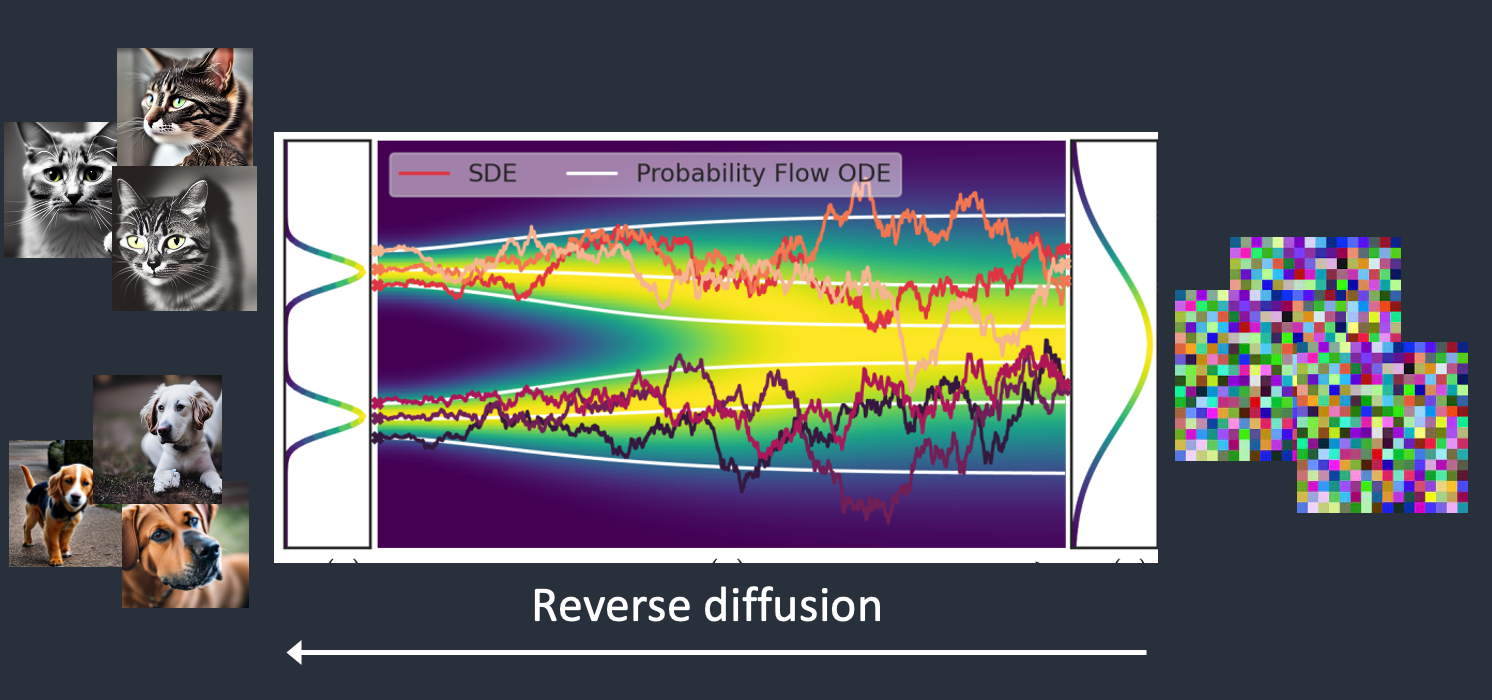
Stable Diffusion is a latent diffusion model that generates AI images from text. Instead of operating in the high-dimensional image space, it first compresses the image into the latent space.
Stable Diffusion belongs to a class of deep learning models called diffusion models. They are generative models, meaning they are designed to generate new data similar to what they have seen in training. In the case of Stable Diffusion, the data are images.
Why is it called the diffusion model? Because its math looks very much like diffusion in physics. Let’s go through the idea.