BREAKING NEWS
LATEST POSTS
-
DeepBeepMeep – AI solutions specifically optimized for low spec GPUs
https://huggingface.co/DeepBeepMeep
https://github.com/deepbeepmeep
Wan2GP – A fast AI Video Generator for the GPU Poor. Supports Wan 2.1/2.2, Qwen Image, Hunyuan Video, LTX Video and Flux.
mmgp – Memory Management for the GPU Poor, run the latest open source frontier models on consumer Nvidia GPUs.
YuEGP – Open full-song generation foundation that transforms lyrics into complete songs.
HunyuanVideoGP – Large video generation model optimized for low-VRAM GPUs.
FluxFillGP – Flux-based inpainting and outpainting tool for low-VRAM GPUs.
Cosmos1GP – Text-to-world and image/video-to-world generator for the GPU Poor.
Hunyuan3D-2GP – GPU-friendly version of Hunyuan3D-2 for 3D content generation.
OminiControlGP – Lightweight version of OminiControl enabling 3D, pose, and control tasks with FLUX.
SageAttention – Quantized attention achieving 2.1–3.1× and 2.7–5.1× speedups over FlashAttention2 and xformers without losing end-to-end accuracy.
insightface – State-of-the-art 2D and 3D face analysis project for recognition, detection, and alignment.
















FEATURED POSTS



-
Free fonts
https://fontlibrary.org
https://fontsource.orgOpen-source fonts packaged into individual NPM packages for self-hosting in web applications. Self-hosting fonts can significantly improve website performance, remain version-locked, work offline, and offer more privacy.
https://www.awwwards.com/awwwards/collections/free-fonts
http://www.fontspace.com/popular/fonts
https://www.urbanfonts.com/free-fonts.htm
http://www.1001fonts.com/poster-fonts.html

How to use @font-face in CSS
The
@font-facerule allows custom fonts to be loaded on a webpage: https://css-tricks.com/snippets/css/using-font-face-in-css/
-
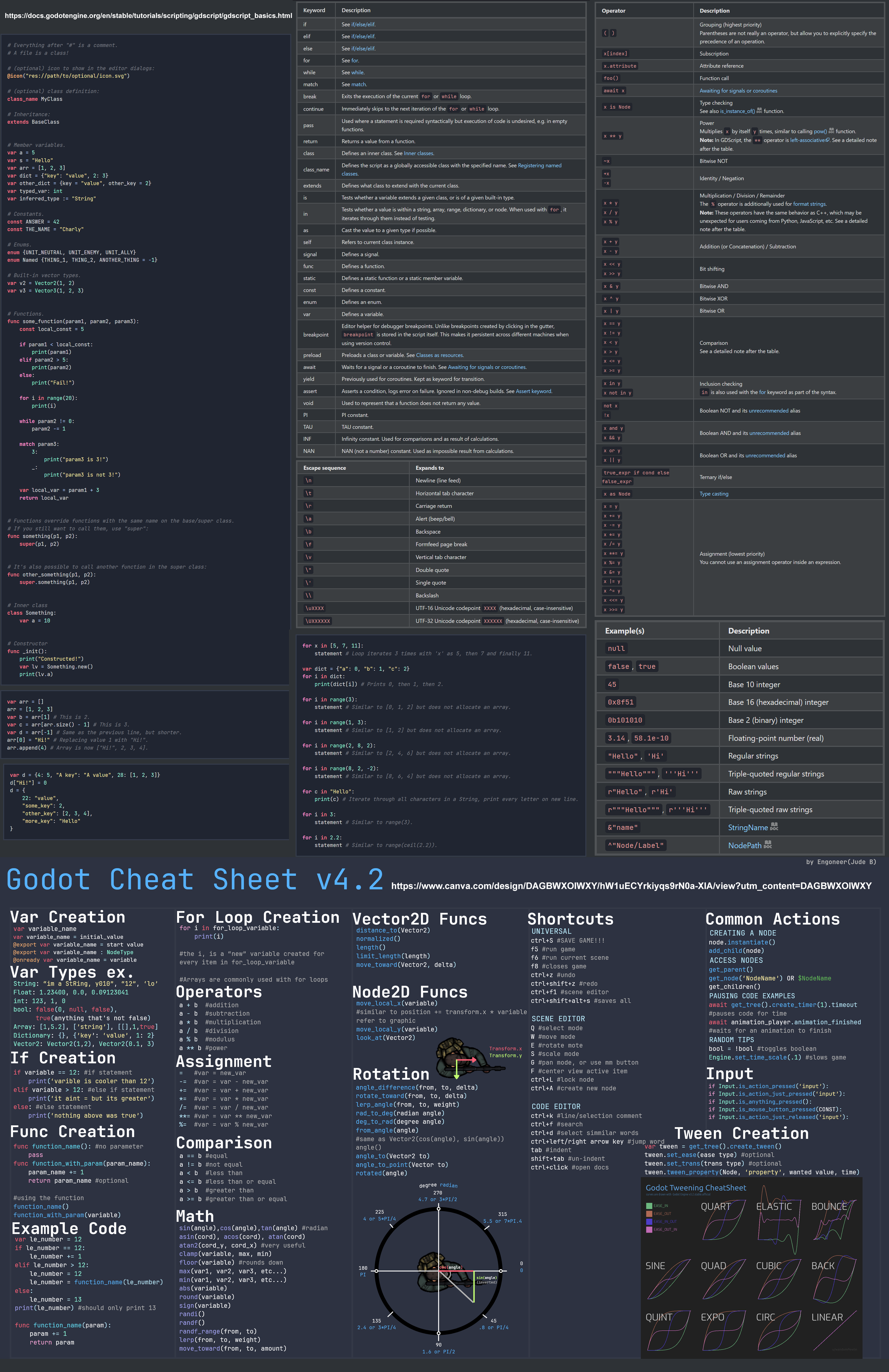
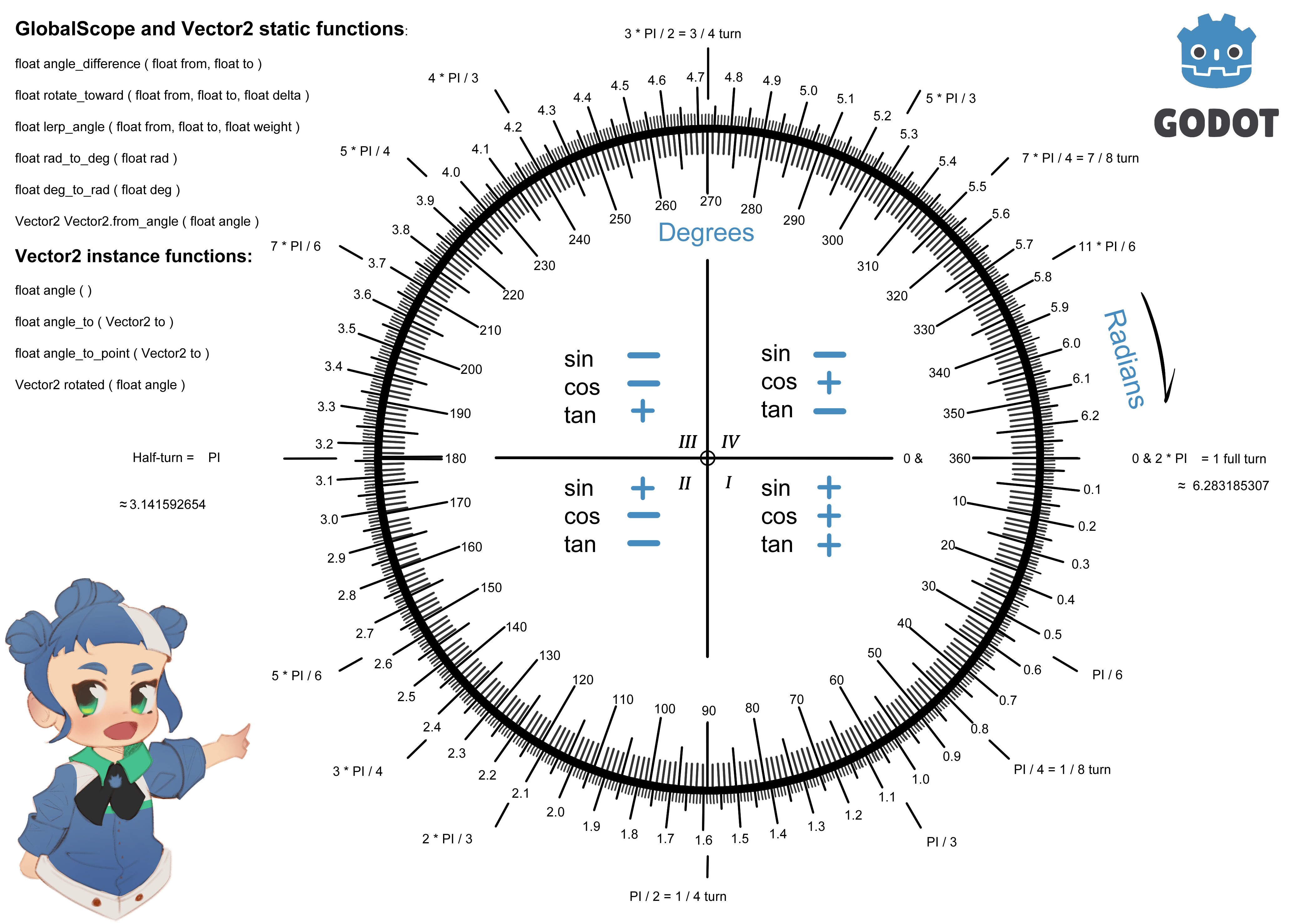
Godot Cheat Sheets
https://docs.godotengine.org/en/stable/tutorials/scripting/gdscript/gdscript_basics.html
https://www.canva.com/design/DAGBWXOIWXY/hW1uECYrkiyqs9rN0a-XIA/view?utm_content=DAGBWXOIWXY
https://www.reddit.com/r/godot/comments/18aid4u/unit_circle_in_godot_format_version_2_by_foxsinart/
Images in the post
<!–more–>