There’s been no statements as to when Midjourney’s technology will start showing up in Meta’s products, or to what degree it will be baked into the company’s AI strategy.
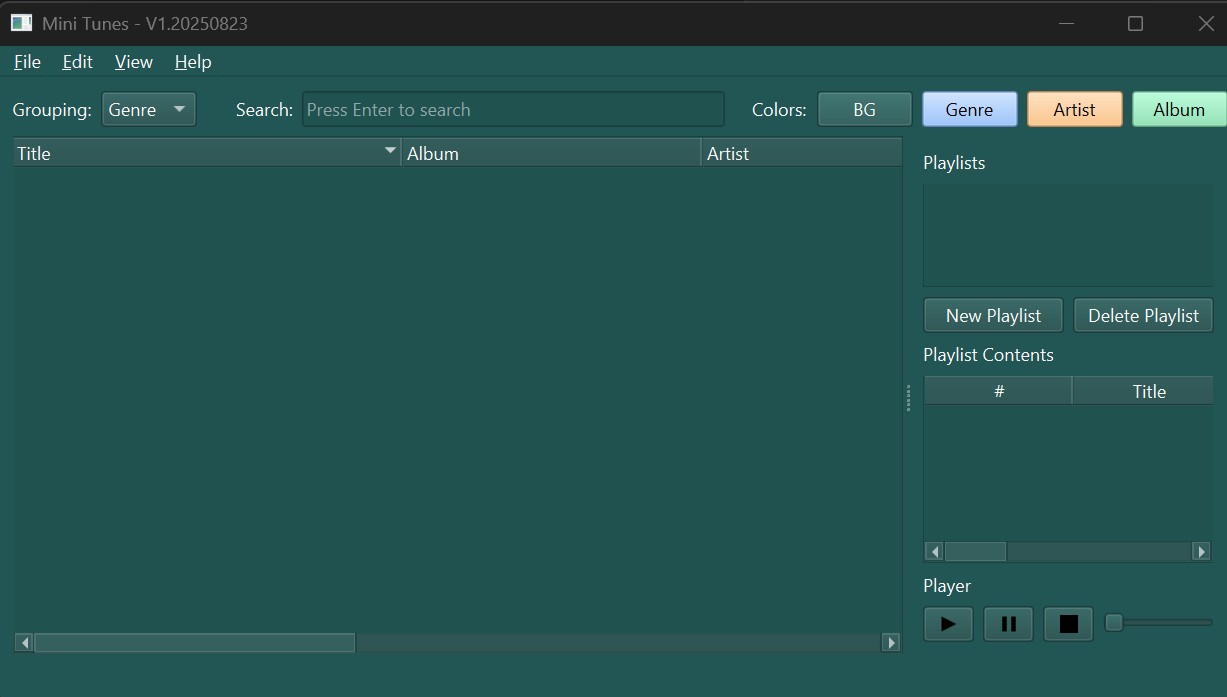
Tired of having iTunes messing up your mp3 library? … Time to try MiniTunes!
– Arrange your library by Genre, Artists or Albums. – Change UI colors at will. – Edit tags and create playlists. – Consolidate your library once for all. – Windows 64 only
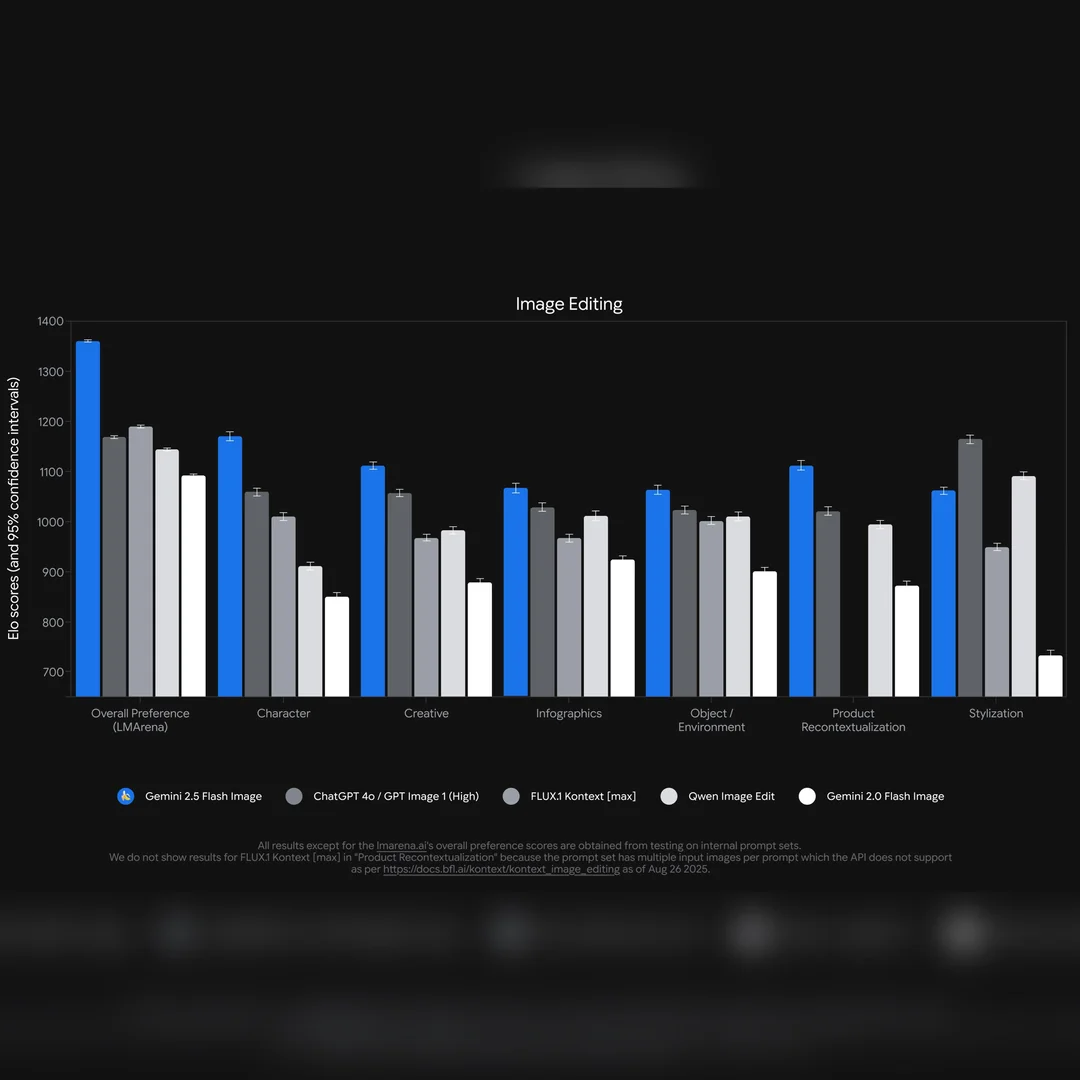
Qwen-Image-Edit is the image editing version of Qwen-Image. It is further trained based on the 20B Qwen-Image model, successfully extending Qwen-Image’s unique text rendering capabilities to editing tasks, enabling precise text editing. In addition, Qwen-Image-Edit feeds the input image into both Qwen2.5-VL (for visual semantic control) and the VAE Encoder (for visual appearance control), thus achieving dual semantic and appearance editing capabilities.
PixiEditor is a universal 2D editor that was made to provide you with tools and features for all your 2D needs. Create beautiful sprites for your games, animations, edit images, create logos. All packed up in an intuitive and familiar interface.
The goal was ambitious: to generate a hyper-detailed 3DGS scan from a massive dataset—20,000 drone photos at full resolution (5280x3956px). All of this on a single machine with just one RTX 4090 GPU.
What was the problem? Most existing tools simply can’t handle this volume of data. For instance, Postshot, which is excellent for many tasks, confidently processed up to 7,000 photos but choked on 20,000—it ran for two days without even starting the model training. The Breakthrough Solution. The real discovery was the software from GreenValley International
Their approach is brilliant: instead of trying to swallow the entire dataset at once, the program intelligently divides it into smaller, manageable chunks, trains each one individually, and then seamlessly merges them into one giant, detailed scene. After 40 hours of rendering, we got this stunning 103 million splats PLY result:
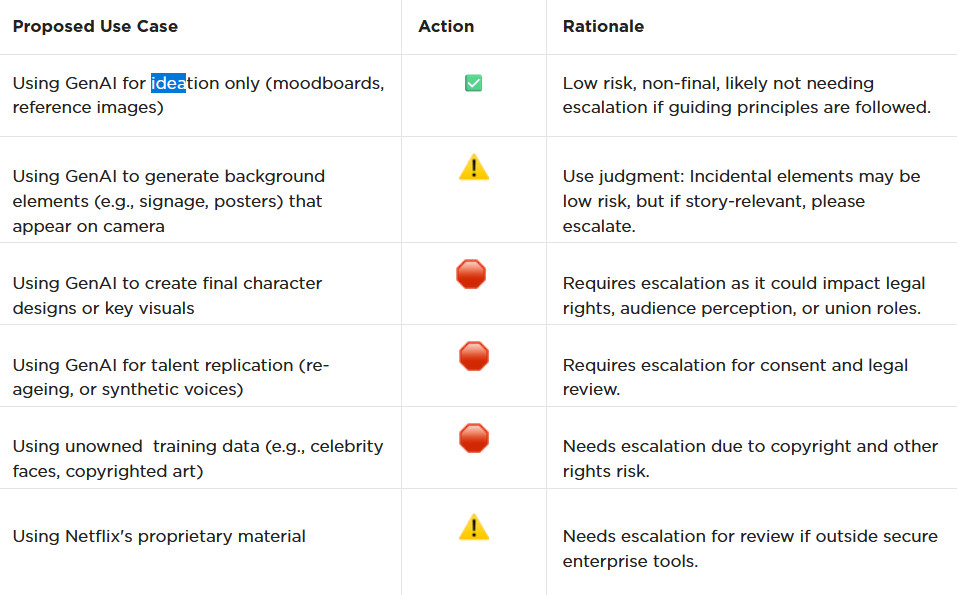
Temporary Use: AI-generated material can be used for ideation, visualization, and exploration—but is currently considered temporary and not part of final deliverables.
Ownership & Rights: All outputs must be carefully reviewed to ensure rights, copyright, and usage are properly cleared before integrating into production.
Transparency: Productions are expected to document and disclose how generative AI is used.
Human Oversight: AI tools are meant to support creative teams, not replace them—final decision-making rests with human creators.
Security & Compliance: Any use of AI tools must align with Netflix’s security protocols and protect confidential production material.
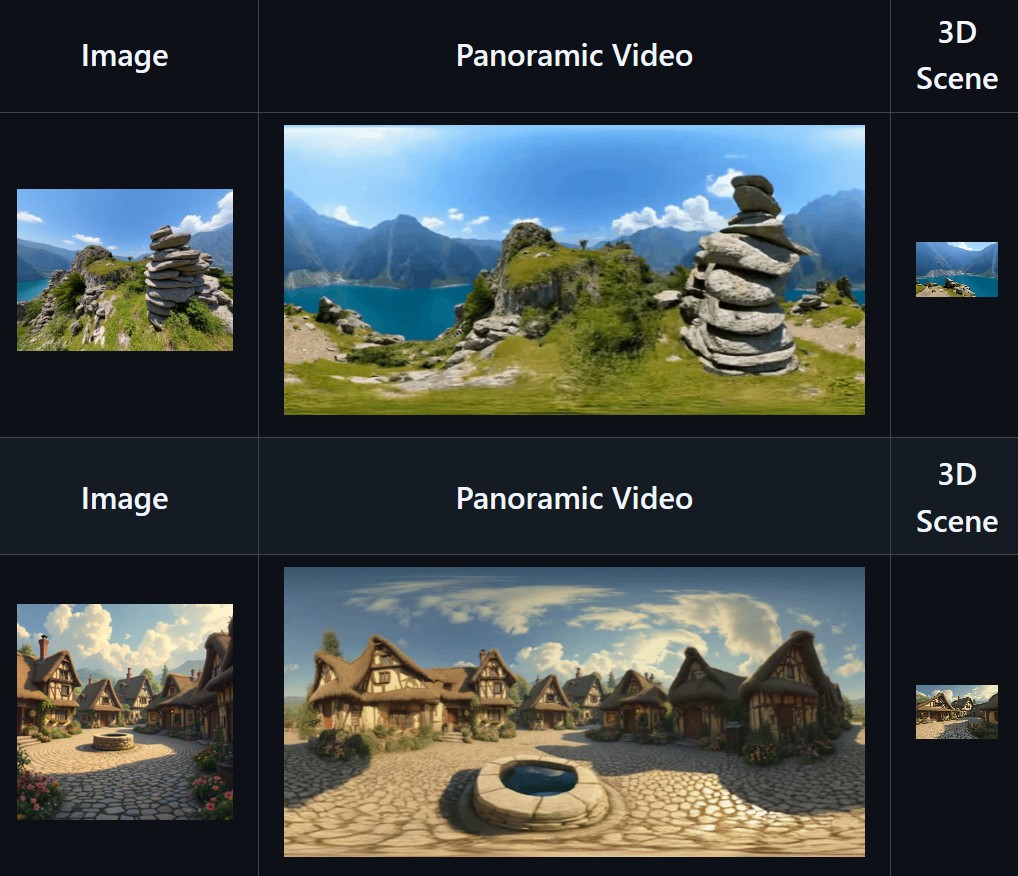
Matrix-3D utilizes panoramic representation for wide-coverage omnidirectional explorable 3D world generation that combines conditional video generation and panoramic 3D reconstruction.
Large-Scale Scene Generation : Compared to existing scene generation approaches, Matrix-3D supports the generation of broader, more expansive scenes that allow for complete 360-degree free exploration.
High Controllability : Matrix-3D supports both text and image inputs, with customizable trajectories and infinite extensibility.
Strong Generalization Capability : Built upon self-developed 3D data and video model priors, Matrix-3D enables the generation of diverse and high-quality 3D scenes.
Speed-Quality Balance: Two types of panoramic 3D reconstruction methods are proposed to achieve rapid and detailed 3D reconstruction respectively.
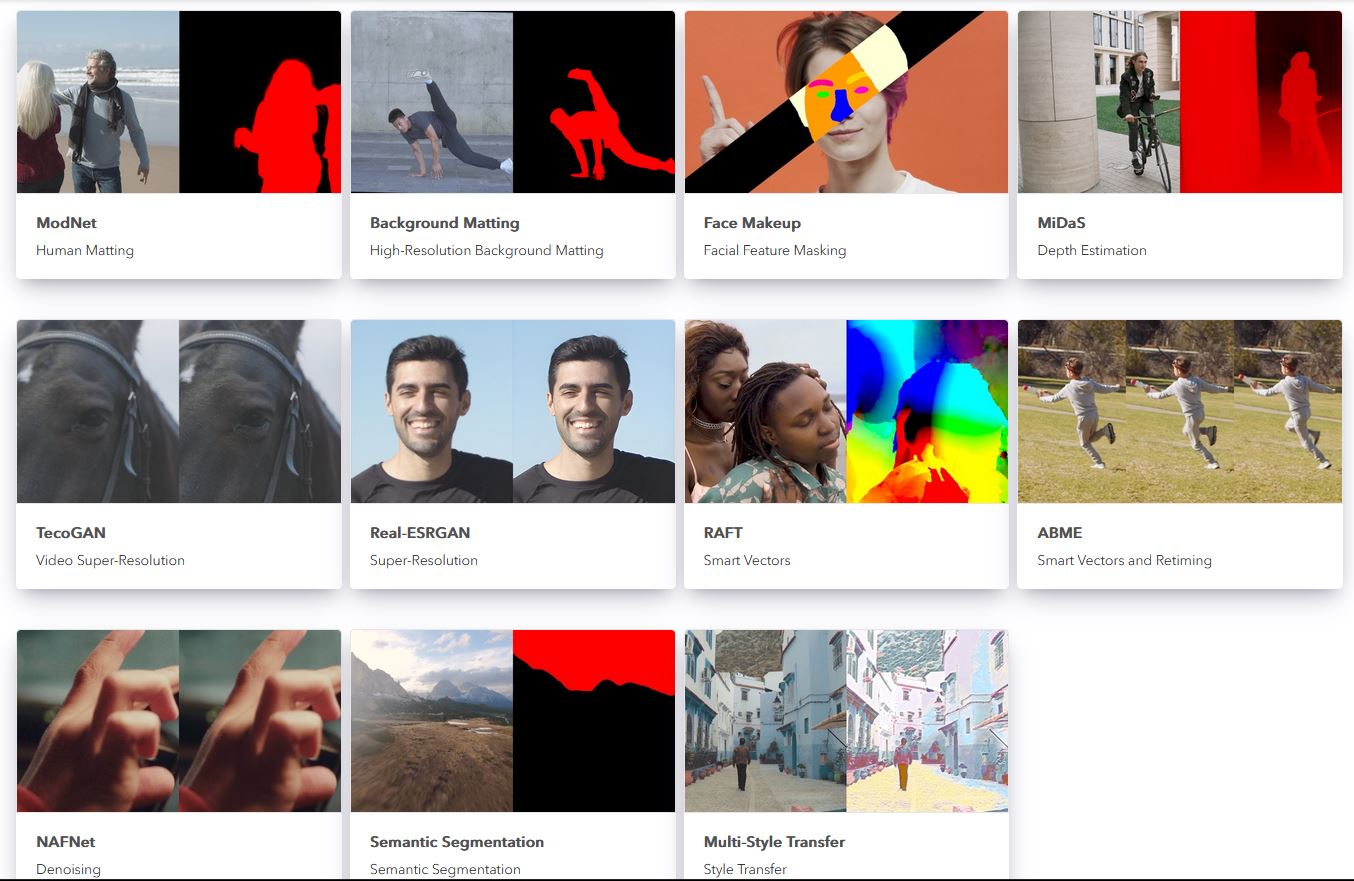
The Cattery is a library of free third-party machine learning models converted to .cat files to run natively in Nuke, designed to bridge the gap between academia and production, providing all communities access to different ML models that all run in Nuke. Users will have access to state-of-the-art models addressing segmentation, depth estimation, optical flow, upscaling, denoising, and style transfer, with plans to expand the models hosted in the future.
“Simon Willison created a Datasette browser to explore WebVid-10M, one of the two datasets used to train the video generation model, and quickly learned that all 10.7 million video clips were scraped from Shutterstock, watermarks and all.”
“In addition to the Shutterstock clips, Meta also used 10 million video clips from this 100M video dataset from Microsoft Research Asia. It’s not mentioned on their GitHub, but if you dig into the paper, you learn that every clip came from over 3 million YouTube videos.”
“It’s become standard practice for technology companies working with AI to commercially use datasets and models collected and trained by non-commercial research entities like universities or non-profits.”
“Like with the artists, photographers, and other creators found in the 2.3 billion images that trained Stable Diffusion, I can’t help but wonder how the creators of those 3 million YouTube videos feel about Meta using their work to train their new model.”
One problem with sRGB is that in a gradient between blue and white, it becomes a bit purple in the middle of the transition. That’s because sRGB really isn’t created to mimic how the eye sees colors; rather, it is based on how CRT monitors work. That means it works with certain frequencies of red, green, and blue, and also the non-linear coding called gamma. It’s a miracle it works as well as it does, but it’s not connected to color perception. When using those tools, you sometimes get surprising results, like purple in the gradient.
There were also attempts to create simple models matching human perception based on XYZ, but as it turned out, it’s not possible to model all color vision that way. Perception of color is incredibly complex and depends, among other things, on whether it is dark or light in the room and the background color it is against. When you look at a photograph, it also depends on what you think the color of the light source is. The dress is a typical example of color vision being very context-dependent. It is almost impossible to model this perfectly.
I based Oklab on two other color spaces, CIECAM16 and IPT. I used the lightness and saturation prediction from CIECAM16, which is a color appearance model, as a target. I actually wanted to use the datasets used to create CIECAM16, but I couldn’t find them.
IPT was designed to have better hue uniformity. In experiments, they asked people to match light and dark colors, saturated and unsaturated colors, which resulted in a dataset for which colors, subjectively, have the same hue. IPT has a few other issues but is the basis for hue in Oklab.
In the Munsell color system, colors are described with three parameters, designed to match the perceived appearance of colors: Hue, Chroma and Value. The parameters are designed to be independent and each have a uniform scale. This results in a color solid with an irregular shape. The parameters are designed to be independent and each have a uniform scale. This results in a color solid with an irregular shape. Modern color spaces and models, such as CIELAB, Cam16 and Björn Ottosson own Oklab, are very similar in their construction.
By far the most used color spaces today for color picking are HSL and HSV, two representations introduced in the classic 1978 paper “Color Spaces for Computer Graphics”. HSL and HSV designed to roughly correlate with perceptual color properties while being very simple and cheap to compute.
Today HSL and HSV are most commonly used together with the sRGB color space.
One of the main advantages of HSL and HSV over the different Lab color spaces is that they map the sRGB gamut to a cylinder. This makes them easy to use since all parameters can be changed independently, without the risk of creating colors outside of the target gamut.
The main drawback on the other hand is that their properties don’t match human perception particularly well.
Reconciling these conflicting goals perfectly isn’t possible, but given that HSV and HSL don’t use anything derived from experiments relating to human perception, creating something that makes a better tradeoff does not seem unreasonable.
With this new lightness estimate, we are ready to look into the construction of Okhsv and Okhsl.